C:\ProgramData\Anaconda3\lib\site-packages\fastai\basic_train.py in fit(self, epochs, lr, wd, callbacks)
194 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
195 if defaults.extra_callbacks is not None: callbacks += defaults.extra_callbacks
→ 196 fit(epochs, self, metrics=self.metrics, callbacks=self.callbacks+callbacks)
197
198 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
C:\ProgramData\Anaconda3\lib\site-packages\fastai\basic_train.py in fit(epochs, learn, callbacks, metrics)
96 cb_handler.set_dl(learn.data.train_dl)
97 cb_handler.on_epoch_begin()
—> 98 for xb,yb in progress_bar(learn.data.train_dl, parent=pbar):
99 xb, yb = cb_handler.on_batch_begin(xb, yb)
100 loss = loss_batch(learn.model, xb, yb, learn.loss_func, learn.opt, cb_handler)
C:\ProgramData\Anaconda3\lib\site-packages\fastprogress\fastprogress.py in iter(self)
64 self.update(0)
65 try:
—> 66 for i,o in enumerate(self._gen):
67 yield o
68 if self.auto_update: self.update(i+1)
C:\ProgramData\Anaconda3\lib\site-packages\fastai\basic_data.py in iter(self)
73 def iter(self):
74 “Process and returns items from DataLoader.”
—> 75 for b in self.dl: yield self.proc_batch(b)
76
77 @classmethod
C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py in init(self, loader)
558 # before it starts, and del tries to join but will get:
559 # AssertionError: can only join a started process.
→ 560 w.start()
561 self.index_queues.append(index_queue)
562 self.workers.append(w)
C:\ProgramData\Anaconda3\lib\multiprocessing\process.py in start(self)
110 ‘daemonic processes are not allowed to have children’
111 _cleanup()
→ 112 self._popen = self._Popen(self)
113 self._sentinel = self._popen.sentinel
114 # Avoid a refcycle if the target function holds an indirect
C:\ProgramData\Anaconda3\lib\multiprocessing\context.py in _Popen(process_obj)
221 @staticmethod
222 def _Popen(process_obj):
→ 223 return _default_context.get_context().Process._Popen(process_obj)
224
225 class DefaultContext(BaseContext):
C:\ProgramData\Anaconda3\lib\multiprocessing\context.py in _Popen(process_obj)
320 def _Popen(process_obj):
321 from .popen_spawn_win32 import Popen
→ 322 return Popen(process_obj)
323
324 class SpawnContext(BaseContext):
Sorry, I don’t know anything about windows. I trust @sgugger will have some ideas.
In the future please file those directly as Issues on github so that they are easy to track and for other people to find solutions to their similar problems.
No using multiple processes (which is done by default to speed things up). You should set num_workers=0 when creating a DataBunch to remove it. More details here.
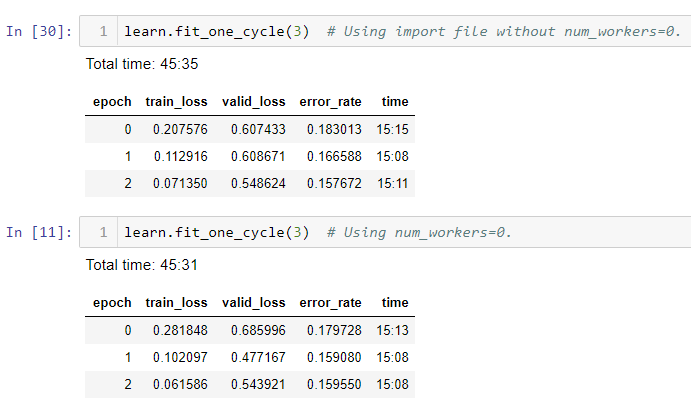
Putting my code creating the ItemList and databunch inside a function inside a new python file and importing that file in my jupyter notebook seemed to remove the need to put num_workers=0.
Both loss, error_rate, and training time were identical.
Edit: I had an error in my import file and my learner was using the old (identical) databunch. After fixing the error and confirming the import file was creating the new databunch correctly, I kept getting the same BrokenPipeError.
My stuff used images and I think image transformations are what takes a lot of time if you have num_workers=0 because you don’t take advantage of multiple GPUs. But I have not done any empirical tests, but it felt a lot slower with num_workers=0.
But if you want to be 100% sure, just surround the code using the data block api inside this if (inside your jupyter notebook):
@ashwinakannan I’m running on Win10, but pytorch 1.0.1 fastai 1.0.47 did not resolve the issue for me. I’m still relying on num_workers=0 to workaround the ForkingPicker broken pipe error.
Have you tried latest version from master? I found an issue regarding that yesterday and committed a fix. But it seems like it needed some adjustments to make it work for google collab:
@sgugger I am almost finished with a tutorial on how to use MixedItemList with the PetFinder dataset.. I want to release my notebook as a potential tutorial for fastai eventually. The only part left is predicting on the test dataset to make a submission to the kaggle competition but I am having problems with inference for the test set.
But then I get this exception… Not too sure whatI am doing wrong, I followed the instructions from https://docs.fast.ai/tutorial.inference.html, but maybe there’s something I am missing…
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-92-2ffbca749f38> in <module>
----> 1 learn = load_learner(path, 'mixed.pkl', text=mixedTest)
c:\work\ml\fastai-dev\fastai\fastai\basic_train.py in load_learner(path, file, test, **db_kwargs)
595 state = torch.load(source, map_location='cpu') if defaults.device == torch.device('cpu') else torch.load(source)
596 model = state.pop('model')
--> 597 src = LabelLists.load_state(path, state.pop('data'))
598 if test is not None: src.add_test(test)
599 data = src.databunch(**db_kwargs)
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in load_state(cls, path, state)
563 "Create a `LabelLists` with empty sets from the serialized `state`."
564 path = Path(path)
--> 565 train_ds = LabelList.load_state(path, state)
566 valid_ds = LabelList.load_state(path, state)
567 return LabelLists(path, train=train_ds, valid=valid_ds)
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in load_state(cls, path, state)
673 def load_state(cls, path:PathOrStr, state:dict) -> 'LabelList':
674 "Create a `LabelList` from `state`."
--> 675 x = state['x_cls']([], path=path, processor=state['x_proc'], ignore_empty=True)
676 y = state['y_cls']([], path=path, processor=state['y_proc'], ignore_empty=True)
677 res = cls(x, y, tfms=state['tfms'], tfm_y=state['tfm_y'], **state['tfmargs']).process()
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in __init__(self, item_lists, path, label_cls, inner_df, x, ignore_empty, processor)
769 if processor is None:
770 processor = MixedProcessor([ifnone(il.processor, dp) for il,dp in zip(item_lists, default_procs)])
--> 771 super().__init__(range_of(item_lists[0]), processor=processor, path=ifnone(path, item_lists[0].path),
772 label_cls=label_cls, inner_df=inner_df, x=x, ignore_empty=ignore_empty)
773
IndexError: list index out of range
Looking at the code more, MixedItemList constructor is different than the other ItemLists. The first argument is a list of ItemList. But usually the first argument for an ItemList is a Iterator of items.
MixedItemList def __init__(self, item_lists, ...
ItemList def __init__(self, items:Iterator, ...
So when we run export, we are saving one ItemList in state[‘x_cls’]. But in the case of MixedItemList, we should save a list of ItemList involved in the MixedItemList.
Because in LabelList.load_state, we are trying to recreate the MixedItemList with this line:
x = state['x_cls']([], path=path, processor=state['x_proc'], ignore_empty=True)
The [] here is usually intended for the items property of ItemList constructor, but in the case of MixedItemList, this lines up with the item_lists parameter. So the constructor for MixedItemList is passed an empty list of ItemList which cause the exception.
 Using:
Using: