I’m trying to create a custom dataset for saved torch tensors. The tensors are saved as .pt files and labeled via a pandas dataframe. These are the two classes I’ve created so far:
class TensorItem(ItemBase):
def __init__(self, data):
self.data=self.obj=data
def apply_tfms(self, tfms, **kwargs):
return self
def __repr__(self):
return f'{self.__class__.__name__} {tuple(self.data.shape)}'
class TensorList(ItemList):
_bunch = DataBunch
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def open(self, fn):
return TensorItem(torch.load(self.path/fn))
def get(self, i):
fn = super().get(i)
res = self.open(fn)
return res
From these, I can create a set of LabelLists:
data = TensorList.from_df(df, path, 'data_col').split_by_rand_pct(0.1).label_from_df('label_col')
At this point, everything seems correct. I can index into the dataset like data.train[0][0].data and it returns a loaded tensor. Everything is correctly labeled. Issues start when I try to create a databunch.
I can run the databunch creation:
data = data.databunch(bs=32, num_workers=0)
But trying to grab a batch throws errors:
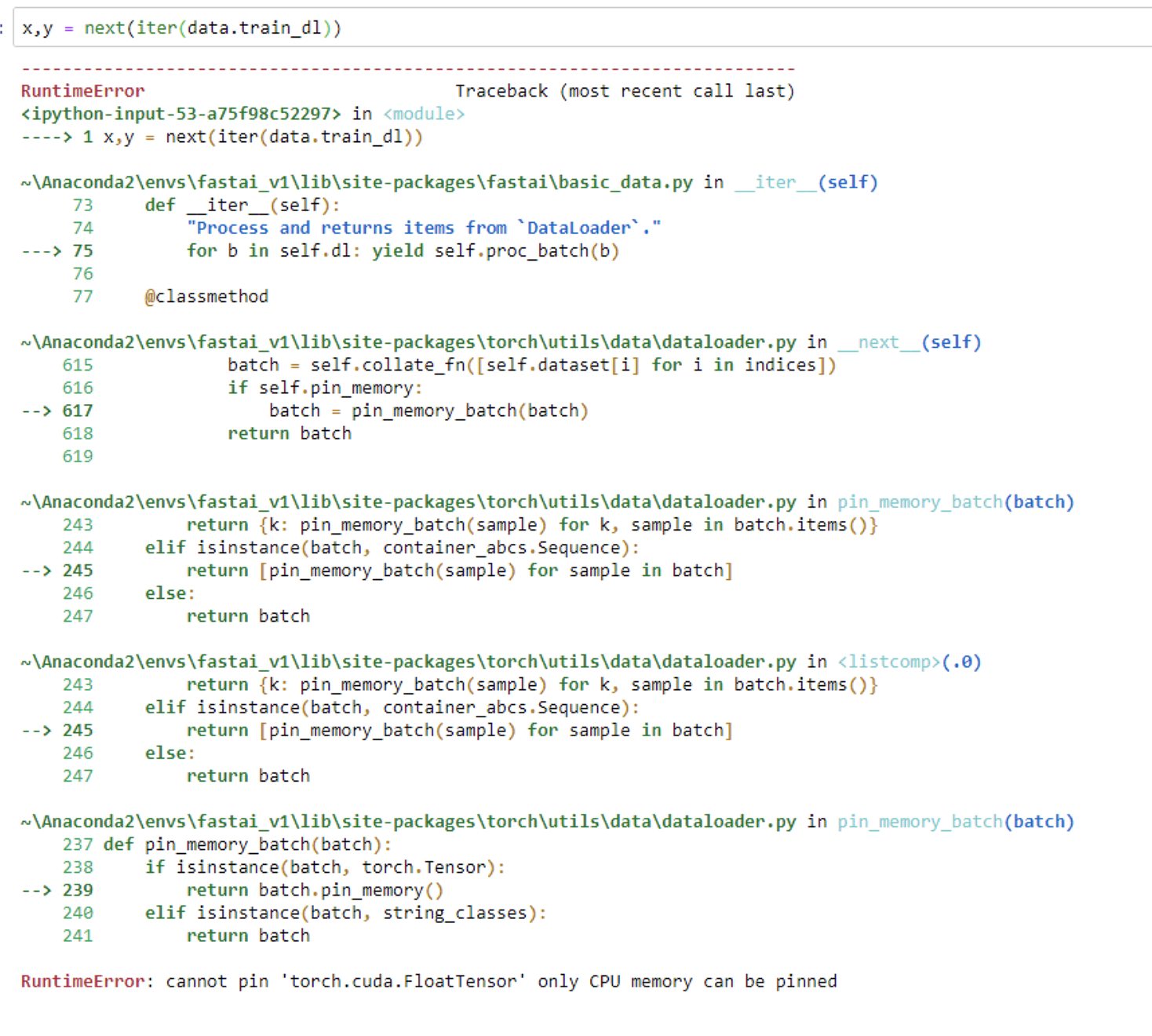
If I use multiple workers:
data = data.databunch(bs=32, num_workers=8)
Trying to grab a batch hangs indefinitely. On a keyboard interrupt, I get the following stack trace:

In both cases the issue seems to be with the proc_batch function. I think the solution is to create a custom dataloader, but I’m not sure what needs to be changed. The actual proc_batch function is in the DeviceDataLoader class, not the DataBunch class. Or is this something a custom collate function would solve? Ideas welcome.