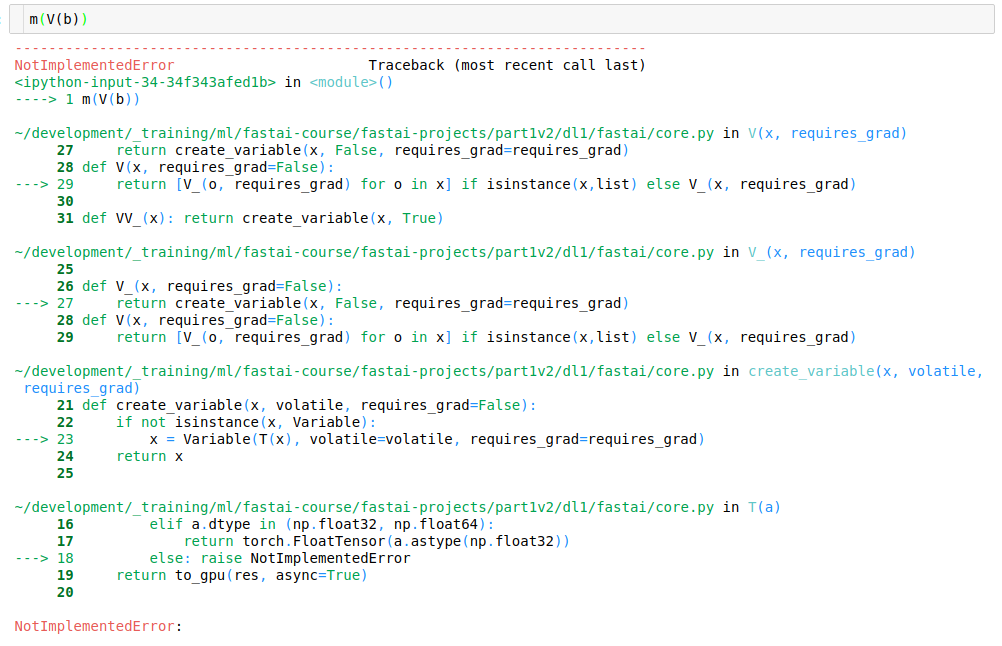
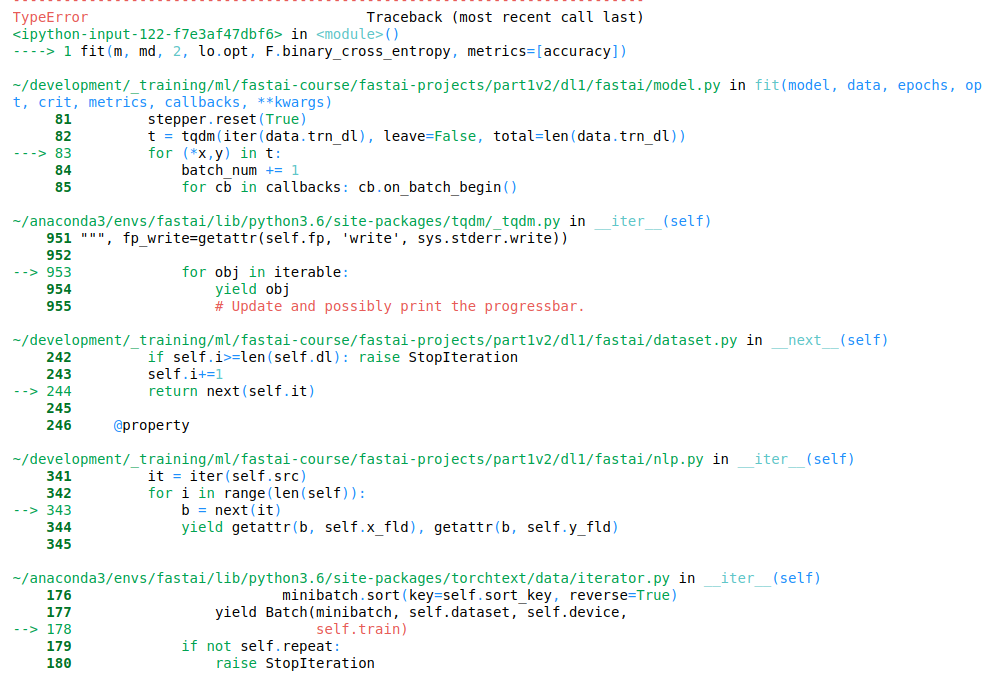
Fighting with this for the last hour …
The error message:
RuntimeError: cuda runtime error (59) : device-side assert triggered at /opt/conda/conda-bld/pytorch_1512386481460/work/torch/lib/THC/generated/../generic/THCTensorMathReduce.cu:18
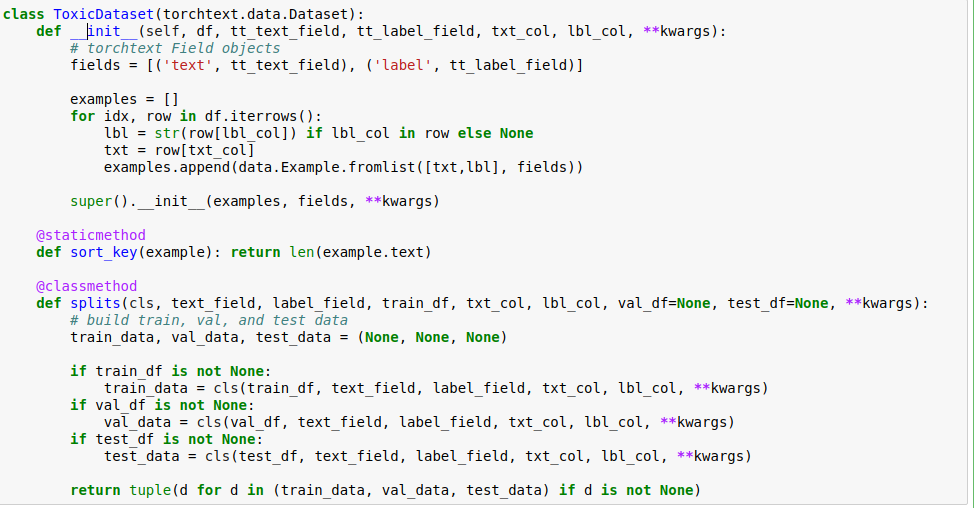
Working on toxic comments competition and trying to define a very simple LSTM to predict just one of the categories (“toxic”). I had to define a custom dataset class and also a modified version of TextData because the fast.ai one has calls to build_vocab for both the label and text field that I don’t want. I can post all that code (if anyone is interested), but I think the problem has something to do with my simple LSTM below.
I’ve defined my text and label fields as such
tt_TEXT = data.Field(sequential=True, tokenize=tokenizer, fix_length=100)
tt_LABEL = data.Field(sequential=False, use_vocab=False)
splits = ToxicDataset.splits(tt_TEXT, tt_LABEL, train_df, 'comment_text', 'toxic', val_df, None)
tt_TEXT.build_vocab(splits[0], max_size=20000)
My batches look like this:
b = next(iter(md.trn_dl))
b[0].size(), b[1].size()
Returns: (torch.Size([100, 64]), torch.Size([64]))
Here is my model:
class LstmClassifier(nn.Module):
def __init__(self, vocab_size, n_fac, bs, nl=1, out_sz=1):
super().__init__()
self.vocab_size, self.nl, self.out_sz = vocab_size, nl, out_sz
self.e = nn.Embedding(vocab_size, n_fac)
self.rnn = nn.LSTM(n_fac, n_hidden, nl, dropout=0.5)
self.l_out = nn.Linear(n_hidden, out_sz)
self.h = self.init_hidden(bs)
def forward(self, words):
outp, h = self.rnn(self.e(words), self.h)
self.h = repackage_var(h)
preds = self.l_out(outp[-1])
return F.log_softmax(preds)
def init_hidden(self, bs):
return(V(torch.zeros(self.nl, bs, n_hidden)), V(torch.zeros(self.nl, bs, n_hidden)))
m = LstmClassifier(md.nt, n_fac, bsz, 2, 1).cuda()
opt = optim.Adam(m.parameters(), 1e-3)
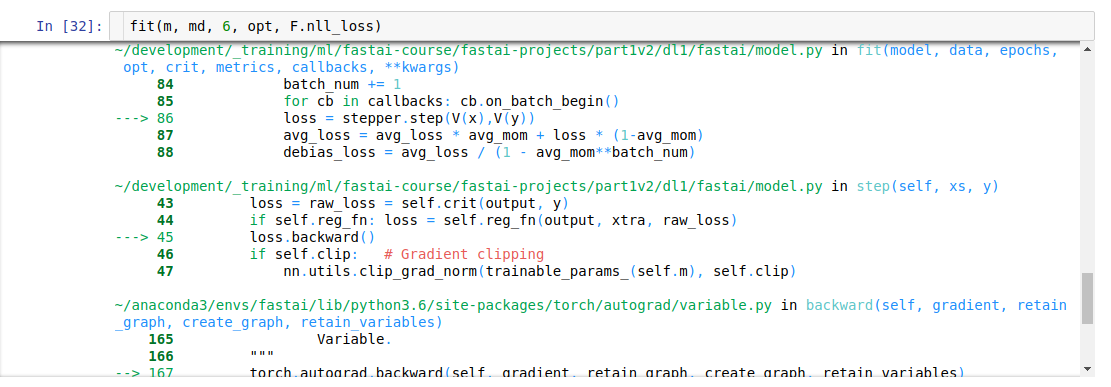
Here is where I hit the error:
fit(m, md, 6, opt, F.nll_loss)
For anyone bold enough to have read this far, any ideas on what I may have pooched?