I am training a model in Kaggle Kernels. I was able to successfully train the frozen model. However, when I unfreeze the model and run lr_find, I receive a CUDA out of memory error. From what I understand from this tutorial, by reloading the model with learn.load(), it should “purge” the memory, freeing it up for later usage. So I added that command, but I still receive a CUDA out of memory error. I may not be fully understand how the GPU memory is being used so I might not be doing this correctly.
This is because in the GPU memory there is still your data, you need first clean your memory by restarting a Kernel in the Jupiter. There is also an option to clean a cache (but not always work): torch.cuda.empty_cache().
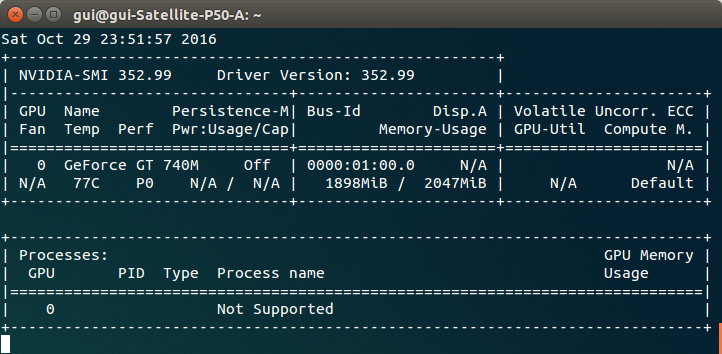
You can see how much memory you left when you can run: nvidia-smi in your console. The software should be installed with your drivers.