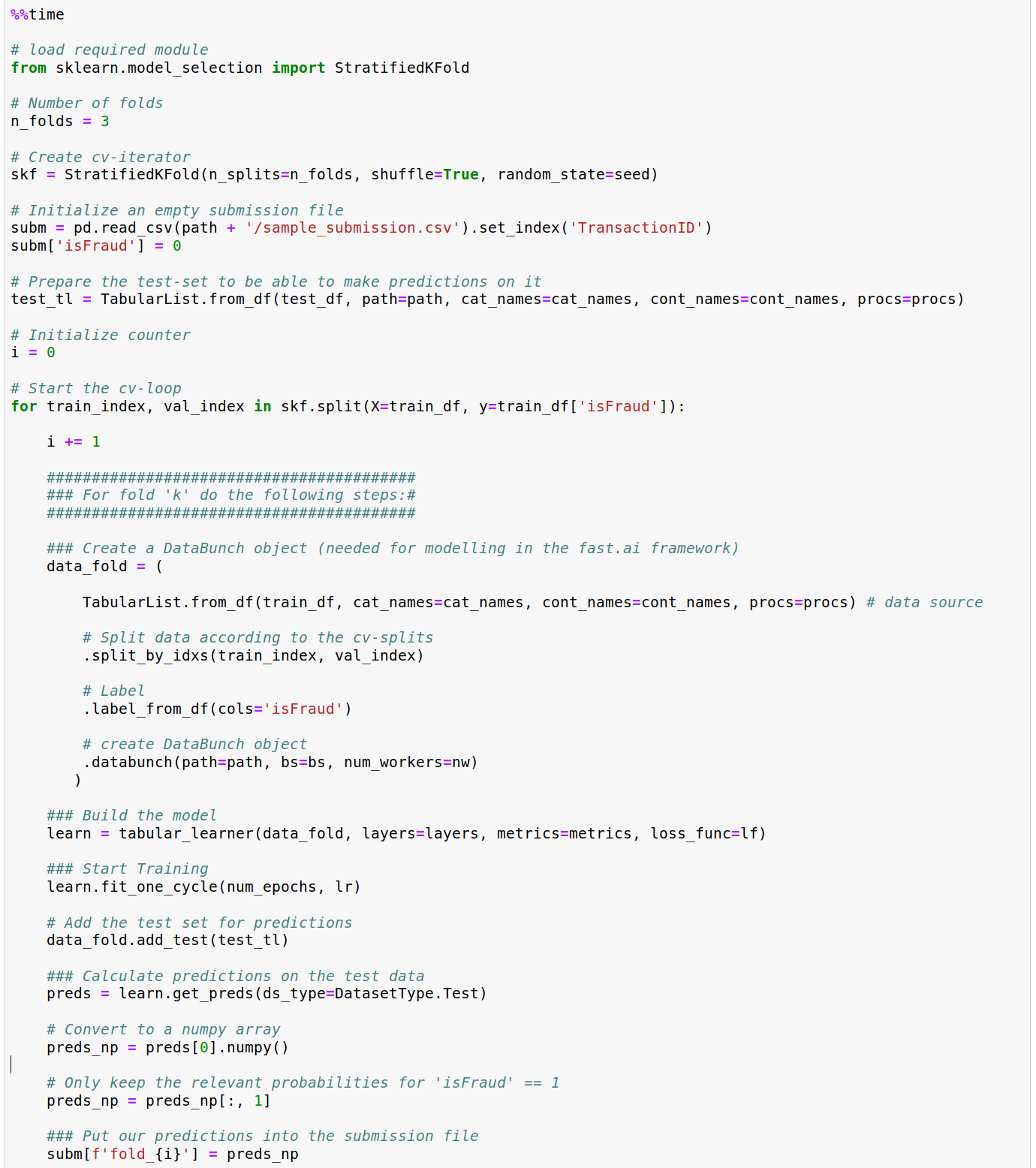
Hello all, let me first say that i am new to the forums and to fast.ai/python in general, so if this topic belongs to another part of the forum, please feel free to tell me.
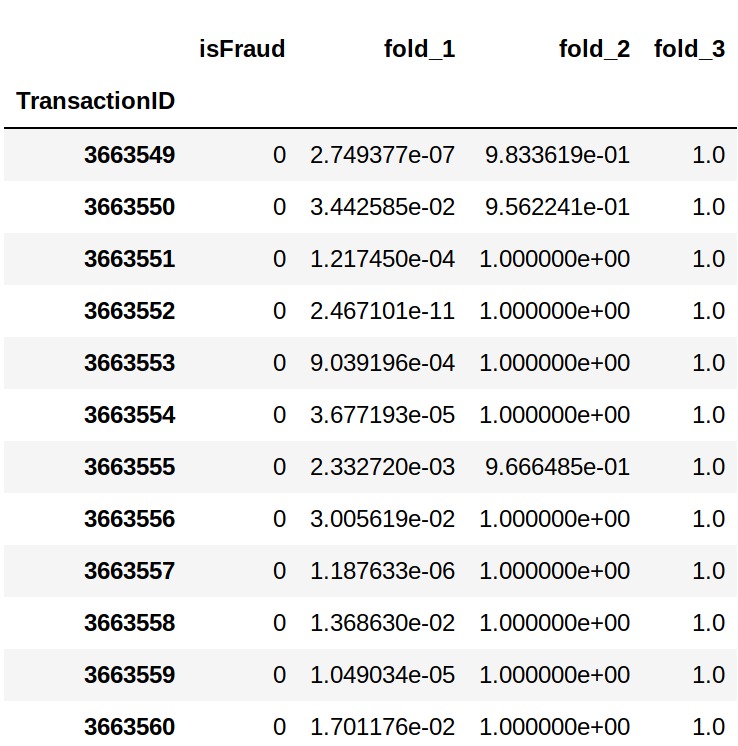
I am trying to make CV work, but the results are kind of odd. The final predictions (= probabilty values for target class == 1) seem fine for the first fold only. For all the other folds however, the probabilities are getting close to 100% for each item in the test set (which cannot possibly be true, as the probabilities should be very small).
I know i am making a stupid mistake somewhere in the loop, but can’t seem to figure it out. I experimented with it almost the entire day but can’t get it working.
I would really appreciate if someone could help me out and point me to my mistake.
That is quite interesting indeed. I posted this in another thread but here is my implementation of k-fold:
val_pct = []
test_pct = []
for train_index, val_index in skf.split(train_df.index, train_df[dep_var]):
data_fold = (TabularList.from_df(train_df, path=path, cat_names=cat_names.copy(),
cont_names=cont_names.copy(), procs=procs,
processor=data_init.processor) # Very important
.split_by_idxs(train_index, val_index)
.label_from_df(cols=dep_var)
.databunch())
data_test = (TabularList.from_df(test_df, path=path, cat_names=cat_names.copy(),
cont_names=cont_names.copy(), procs=procs,
processor=data_init.processor) # Very important
.split_none()
.label_from_df(cols=dep_var))
data_test.valid = data_test.train
data_test = data_test.databunch()
learn = tabular_learner(data_fold, layers=[200,100], metrics=accuracy)
learn.fit(1)
_, val = learn.validate()
learn.data.valid_dl = data_test.valid_dl
_, test = learn.validate()
val_pct.append(val.numpy())
test_pct.append(test.numpy())
for a labeled test set. If you have unlabeled change data_fold to be:
data_fold = (TabularList.from_df(train_df, path=path, cat_names=cat_names.copy(),
cont_names=cont_names.copy(), procs=procs,
processor=data_init.processor) # Very important
.split_by_idxs(train_index, val_index)
.label_from_df(cols=dep_var)
.add_test(TabularList.from_df(test_df, ...)
.databunch())
That bit that says very important relates back to building an initial databunch with all the data as some processes (the categorical matrix for one) were not lining up, so I built a normal one and pulled from it. I hope this can help solve your problem to some degree