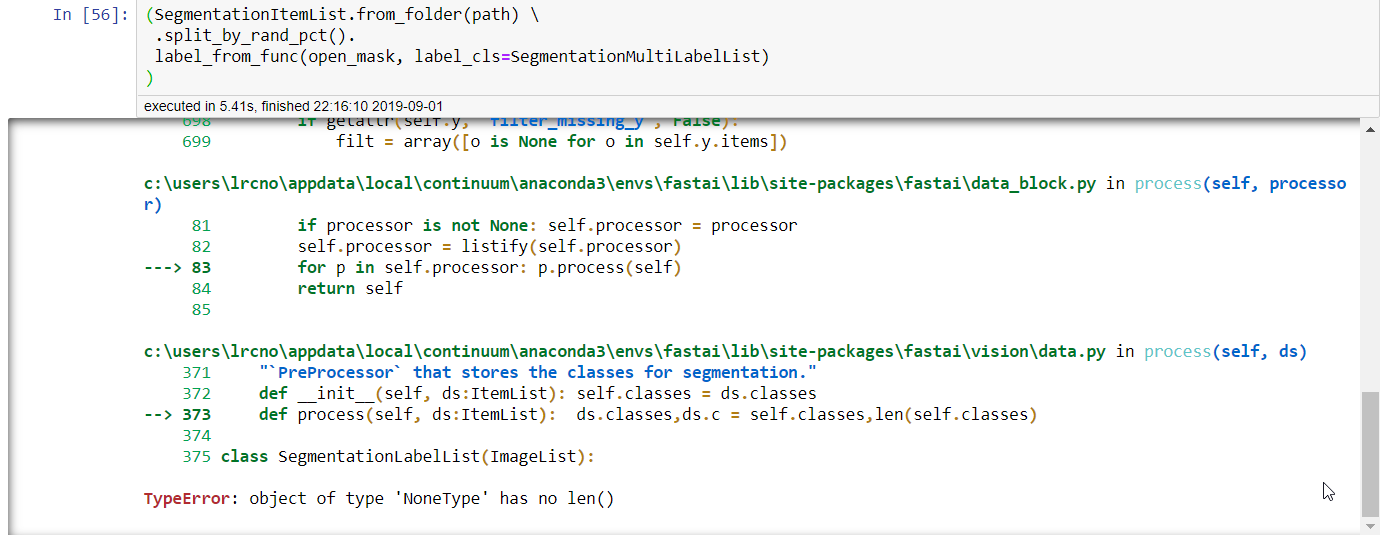
YoungProgrammer, I think I had a similar issue using the default accuracy metric while doing a multi-class segmentation problem.
At a high level, my issue is that the default implementation of accuracy takes the argmax across the wrong dimension. So I implemented a custom accuracy metric that slightly tweaks the default behavior.
def cust_accuracy(input:Tensor, targs:Tensor)->Rank0Tensor:
"Computes accuracy with `targs` when `input` is bs * n_classes."
n = targs.shape[0]
input = input.argmax(dim=1).view(n,-1)
targs = targs.view(n,-1)
return (input==targs).float().mean()
Notebook for course 1 lesson 3 implements a custom metric that does a similar thing.
Then I passed this custom metric when initializing my learner
learn = unet_learner(test_databunch, models.resnet34, metrics=[cust_accuracy], wd=wd)
Should fix your problem. Hope this helps and isn’t completely off base!
Explanation of what happened for me
When evaluating the model, your metric takes your prediction (the “input” to the accuracy metric) and compares it to target.
Out of multiclass segmentation, your output is going to be of shape [batch size, # classes, height, width]
Importantly, the second dimension contains your class-level probability estimate. Therefore, it takes the highest predicted probability across all your classes–this is what input.argmax(dim=1) does.
However, the metric accuracy() implemented in the source code (link) is actually taking input.argmax(dim=-1) which is just giving the highest probability for a given row of your image.
This is nonsensical for our purposes. I’m not totally sure why it’s designed this way. I think it’s because for other classification types where you use accuracy, input is of format [batch size, classification]?