@shub.chat Am i running into the same problems that you were talking about?
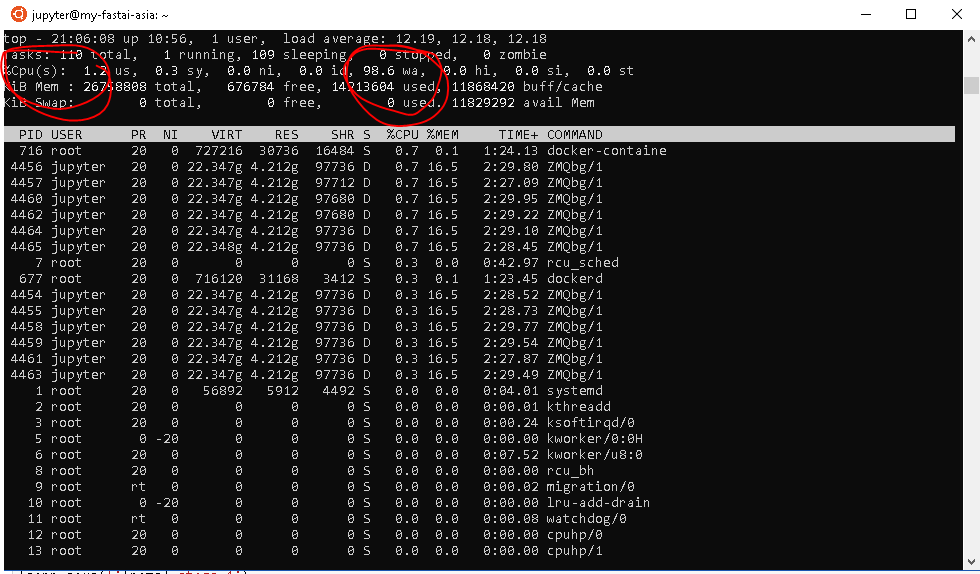
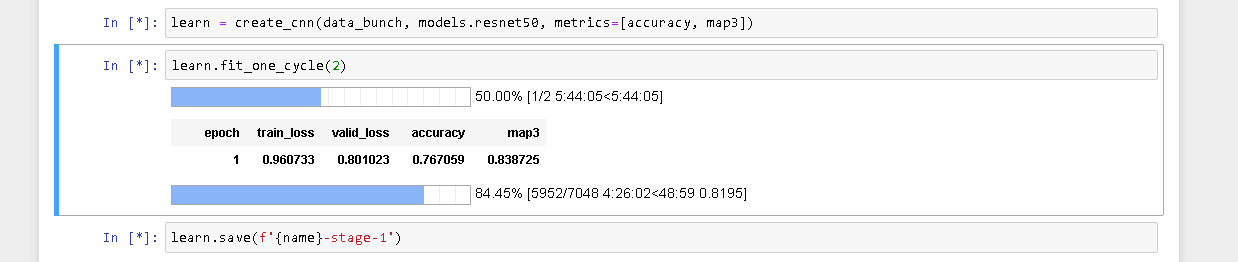
Yeah looks exactly like mine.Cant get my head around why this may be happening .I am wondering can this be a Bottleneck in the dataloaders for higher batch size ?
I’m about to test my theory (waiting for GCP to create a snapshot) but it may be as simple as disk IO like we discussed last night. I’m going to rebuild my VM with an SSD and see if that makes a difference.
I’m a bit peeved after I was so excited to move to the 16gb P100 but now i’m worse off.
If you have many steps in your image transformations it won’t help with keeping the GPU busy. You might want to pre-create all the transformations as a new set of images on disk and then avoid on-the-fly transformations altogether. You can prove the theory by removing transformations and seeing what different it makes.
1 Like
Ok, TLDR SSD makes a real difference.
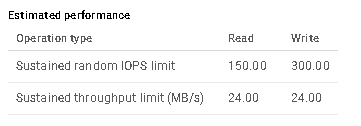
Firstly the HDD performance (taken from the GCP disk editing page)
And now the SSD…yep, seems quicker

from %98 to %10-13, I’ll take it.
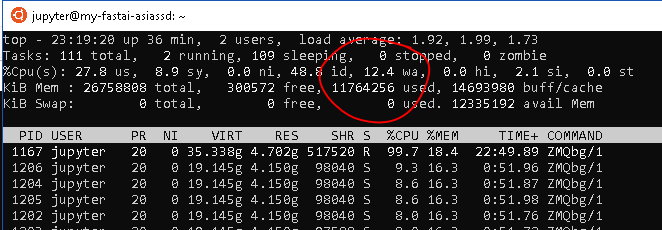
and the all important learning time.
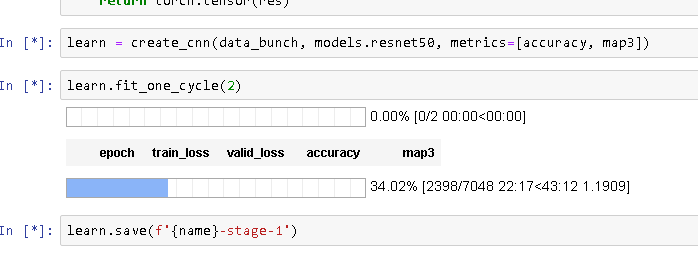
If any nasty surprises crop up i’ll let you know but it seems that for the extra 10c per hour this is the way to go if you are using big datasets.
2 Likes
Looks really promising Tim.If this works as we are expecting it will be worth writing a short blog about it .I am sure there are many others who might benefit with this little experiment and work around .