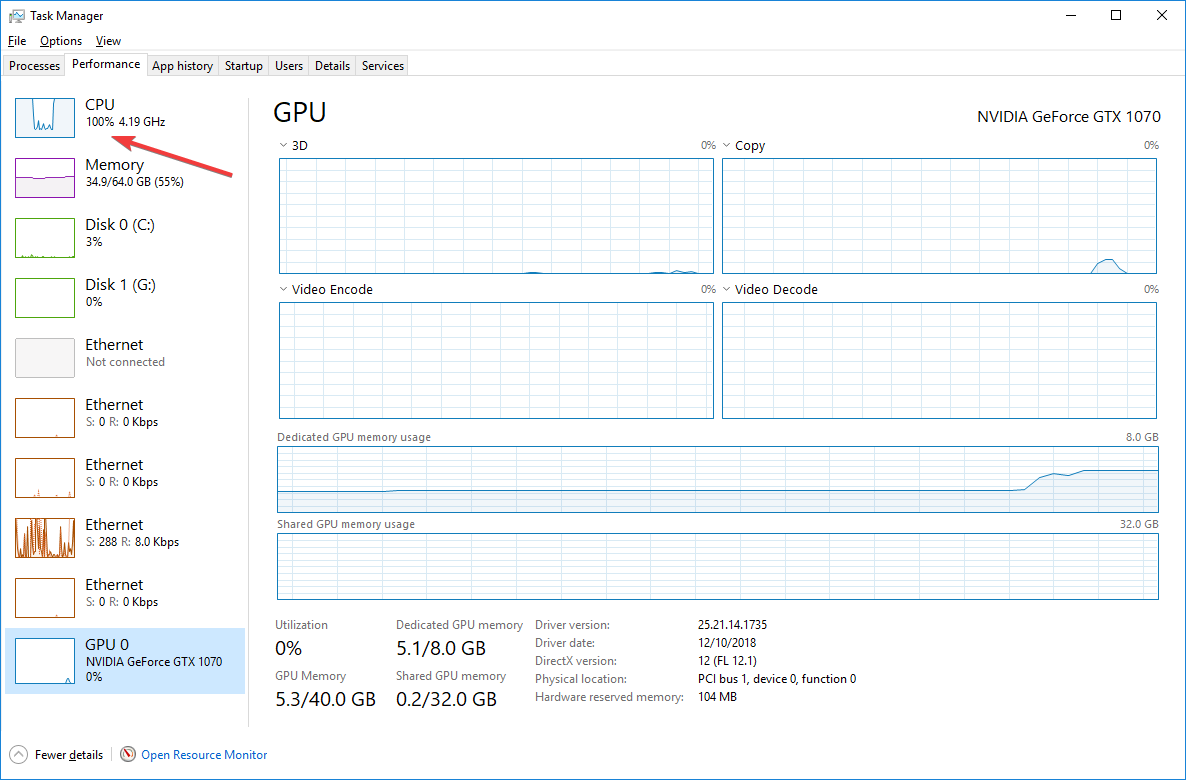
After doing lesson 1, I wanted to try it on my own dataset. I tried it with around 160k labelled images I have from work. The images are around 1440x1080 pixels on disk (sometime larger sometime smaller)…
It is training, but rather slowly. CPU seems to be my bottleneck even though torch.cuda.is_available() returns true. So I assume that pytorch is using my GPU. I am on windows. The CPU is at 100% and the GPU is barely used:
I’m not sure doing transforms on the GPU is possible, at least I’m not aware of anyone doing that. GPUs are good at doing basic operations on matrices (and now also tensors with the new tensor cores), but I think most transforms can’t be reduced to simple matrix or tensor operation.
If that’s right, the only thing you can do is apply the tfms before and separately from the training with apply_tfms and then train on those transformed images.
Well, if you apply transforms in advance, that will reduce the randomness of the transformation unless there is no randomness involved in your transform, like resizing or padding.
I have the same issue here, coz for computer vision, image augmentation is inevitable and doing it with a CPU is always my bottleneck for training. In this case, a DL rig with 4 GPUs won’t make any sense. I really want to know how are people solving such problems!
My idea comes from the fact that most games are rendered using the GPU, textures are simply images. Those textures are applied to polygons, so they are zoomed, rotated etc etc. This is why I was thinking we could simply do something similar before feeding a batch in the training loop.
The big problem with doing data augmentation on the GPU is that you need to already have images of the same size to batch them together, which is very often not the case. Other than that, most the data augmentation can be adapted to be done on the GPU since in fastai it’s done on pytorch tensors.
So if we pre-processed our images on disk to be already all the same size. You could theoretically do everything on the GPU? This would be very very nice.
@sgugger, are you saying that we can just “simply” put the “transforms pytorch tensors” on gpu, since fastai is just doing transforms on pytorch tensors on cpu? Preprocessing the image data into the same size is not a big issue at all…
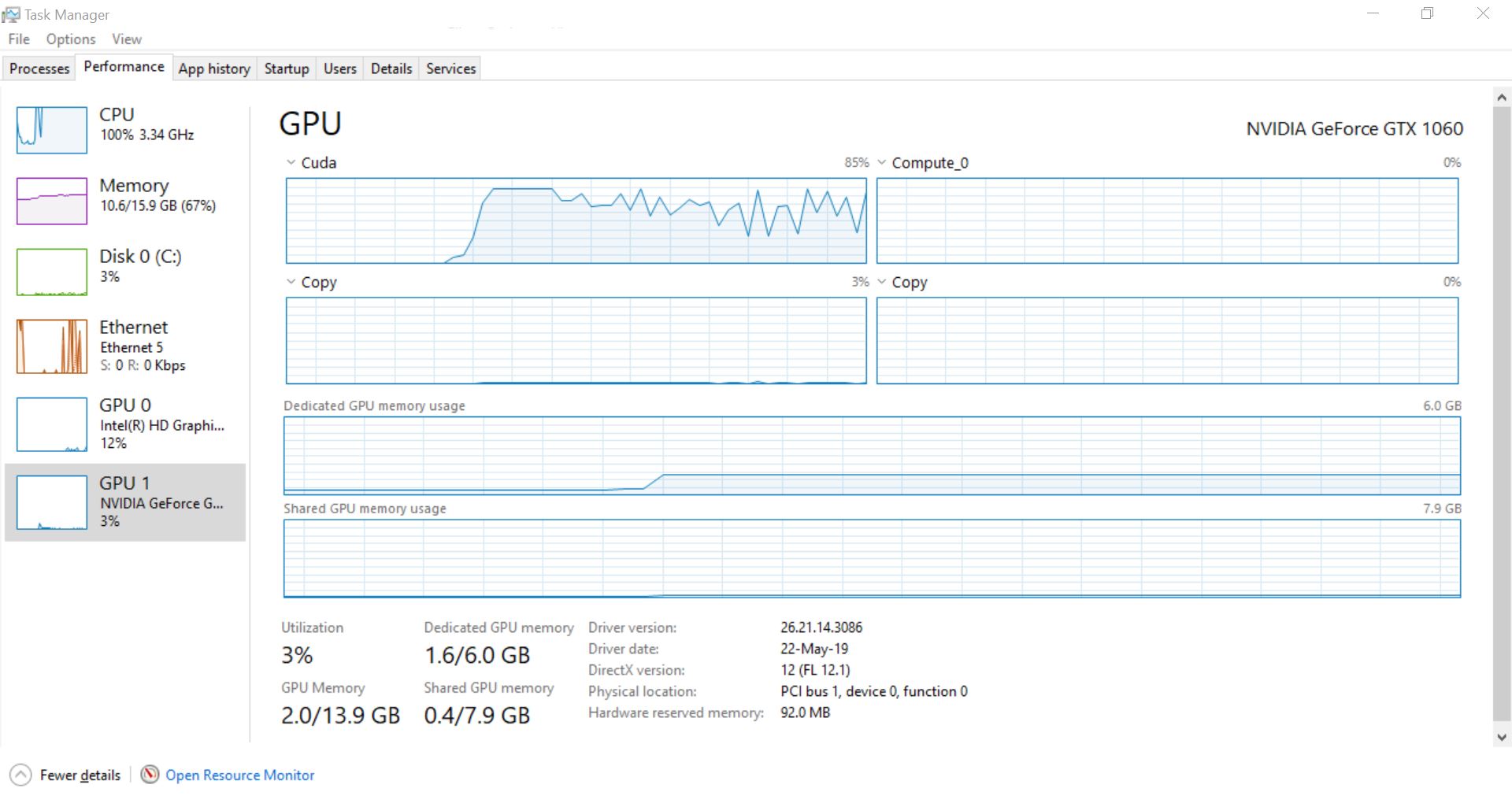
As you can see, I am facing the same problem.
In the Task Manager, you can change the metrics to show how much of Cuda power you using, as I did.
And it easy to see that my GPU working as well, but I have a CPU bottleneck.
Sounds good. However, I am working on a project using fastai v1 and am interested in using GPU augmentations to decrease training time. How would I go about doing that? To me, it isn’t clear how fastai is applying the augmentations. Is it happening through the DeviceDataLoader?
@sgugger I dug through the fastai source code to better figure out and I think I am misunderstanding something because to me it seems fastai should already be using GPU for transforms. Here’s what I mean: