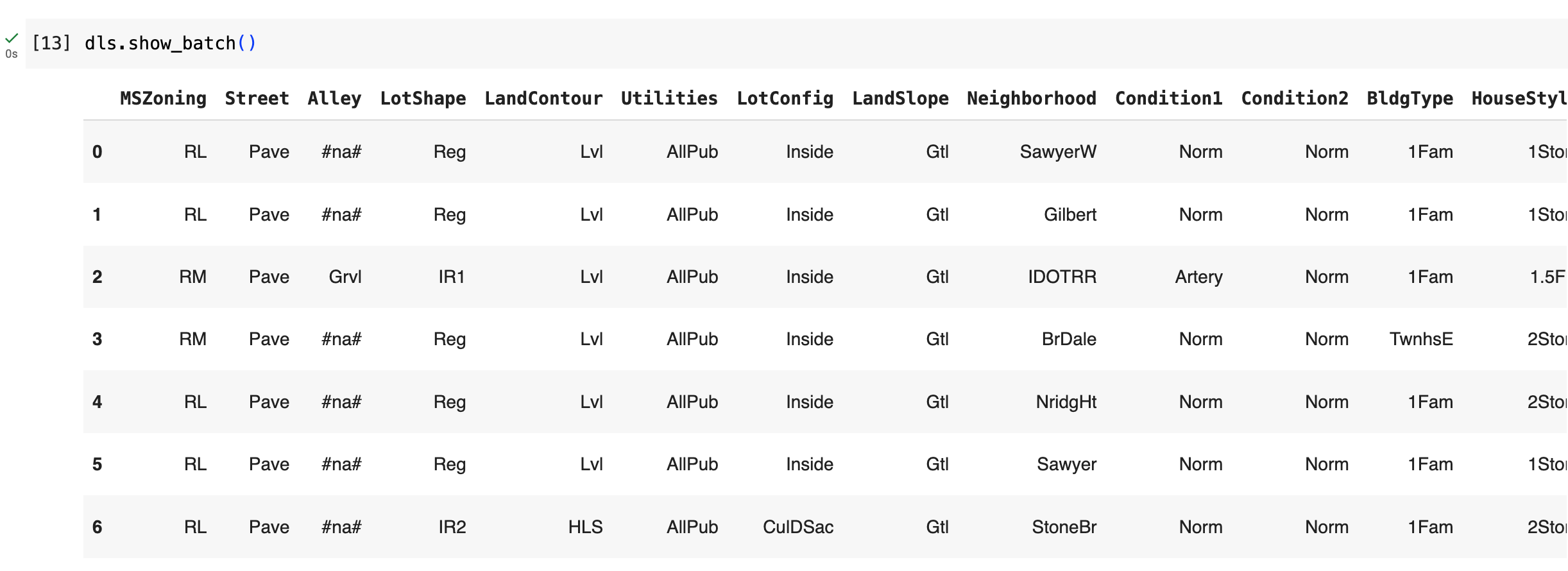
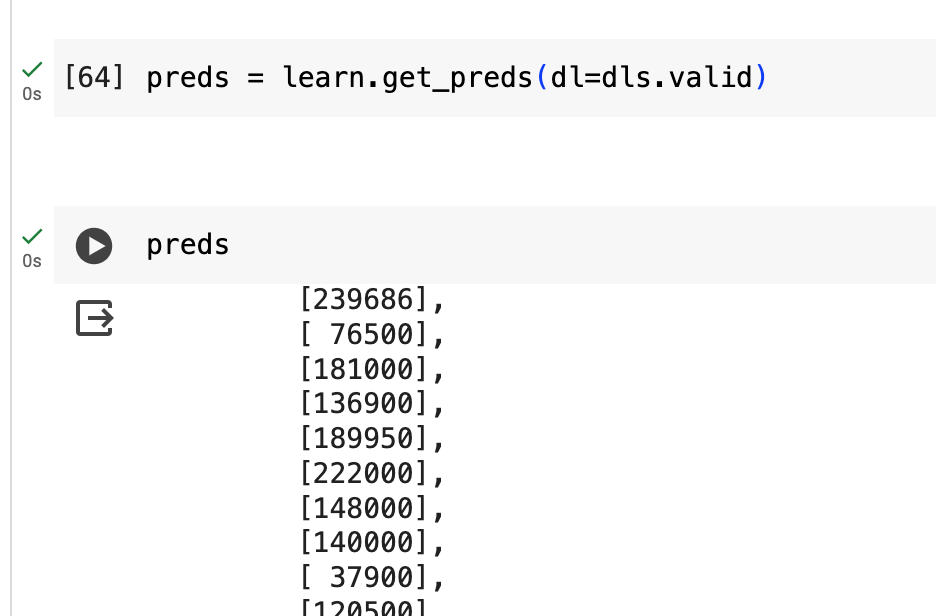
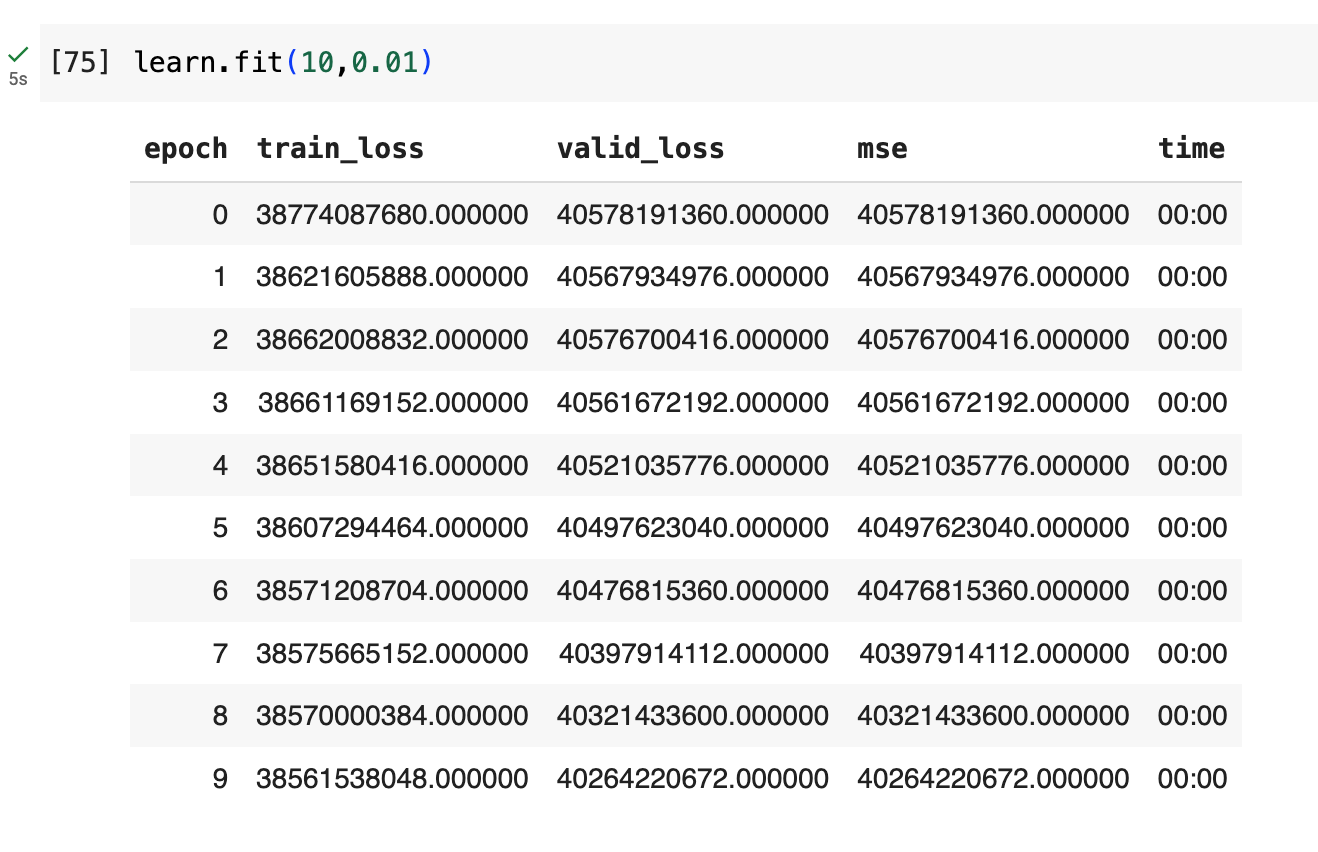
Hi everyone,
I’m currently working on the Practical Deep Learning for Coders course and recently completed Lesson 5. I’m interested in trying out fast.ai for a different project, so I downloaded the House Prices - Advanced Regression Techniques dataset from Kaggle.
My goal is to use the fast.ai tabular learner to compare its predictions with models like polynomial regression and random forests. Initially, I thought this would be straightforward, but I’ve encountered two errors that I’m struggling to resolve.
Based on my search in the forums, it seems removing the Normalize function from the procs attribute in TabularPandas might resolve the errors. However, without data normalization, the model’s predictions become significantly inaccurate.
I’m unsure if I’m approaching this project incorrectly or if there’s a subtle detail causing the errors. Here’s a summary of the issues:
1st error.
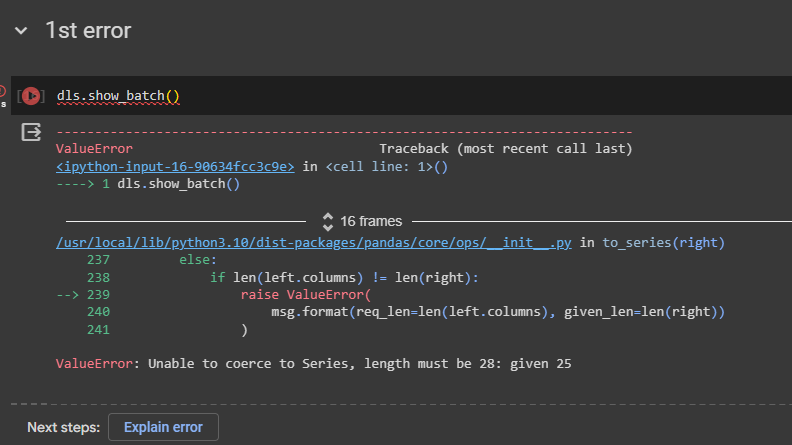
2nd error
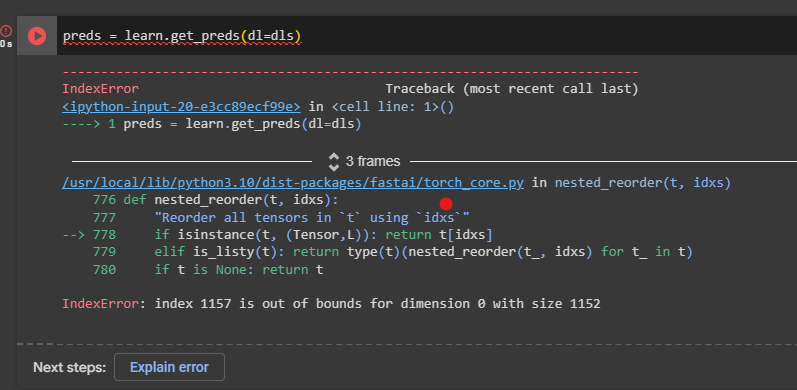
I’ve also shared my notebook for further insights:
I’d greatly appreciate any suggestions or guidance you can offer to help me overcome these challenges and effectively compare the fast.ai learner with other models.
Thanks you!