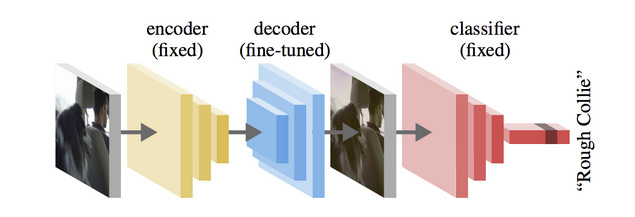
They use a SegNet autoencoder followed by an image classifier (ResNet50, VGG, …), then look at the decoder output in order to interpret what the classifier net actually learned.
The authors then note patterns like these in the decoder output (taken from the paper):
But the authors came to very different conclusions and base other theories on finding these artefacts. He said that they still could not fully explain the patterns and that they are actively researching this further.
So I looked up the paper and read it and I can’t find any mention of the deconv effects, they do not seem to be aware of these. But after further researching this, I am pretty sure deconv is the cause (at least partially):
They “fine-tune” the decoder of the autoencoder through backpropagation from Classifier-CNNs, which from my understanding constitutes transposed convolution with exactly those effects.
Or how is what they found different from those deconv artefacts?
How could this hypothesis be tested? (the model code using pytorch is available on github)
I watched the video and if I understand what you’re asking, you wonder if the deconv artefacts from the backprop through the classifier causes these effects? Which even if that is the case it’s still an interesting question that they’re asking.
You’re not asking about the deconv on the decoder, right?
I’m interested in this concept of using an encoder to prep an image for a classifier but I’m not sure what to think of this work. I’m still processing it. I wonder if a better title would be, “what do classifiers learn to ignore”.
There seems to be general confusion with respect to the nature of the artifacts that I would like to clear up.
We don’t use deconvs! (we use unpooling)
The appearance of those artifacts (if they look like checkerboard patterns or not) doesn’t really matter. What’s important is that the artifacts are consistent between different reconstructions. This phenomenon can be analyzed from an information standpoint: if all images have the same value for the pixel at position (a, b), that pixel position carries no information about the class it has been associated to. Quantifying this observation is one of the main contributions of the paper.
Whenever we compute the gradients of a convolutional layer, we do deconvolution (transposed convolution) on the backward pass. This can cause checkerboard patterns in the gradient, just like when we use deconvolution to generate images.
From my understanding that is exactly what you would have “captured” in the decoder output/reconstruction. This also aligns with the fact, that the architectures that use more stride have the largest noticible artifacts (Alexnet: Kernelsize 11, Stride 4; ResNet: Kernelsize 7, Stride 2 and Kernelsize 3, Stride 2) whereas e.g. VGG (only KS:3, Stride 1 convs) has much less artefacts.
Regarding No. 2: Citing from the same source (highlighting mine):
It’s unclear what the broader implications of these gradient artifacts are. One way to think about them is that some neurons will get many times the gradient of their neighbors, basically arbitrarily. Equivalently, the network will care much more about some pixels in the input than others, for no good reason. Neither of those sounds ideal.
So I think your findings mirror and extend this and that is what my original question was about (“How is this different?”)
you are right, the checkerboard effect can indirectly appear due to the implicit deconvolution in backprop. Note that we don’t really care about the shape but the implications of having such a pattern.
UPDATE:
This also aligns with the fact, that the architectures that use more stride have the largest noticible artifacts
Note that Inception v3 has Kernelsize 3, Stride 2. However, reconstructions have no visible checkerboard artifacts.
There are several additions to this phenomenon that we discuss in the paper:
We provide at least a lower bound on how much of those pixels in the input are being ignored by the network (to use the same language of Odena et al., 2016) through the nMI experiments. Our results allow us to make stronger claims about the influence of those ignored pixels: instead of saying that a network will “care much more about some pixels” we can now argue that for some of these networks, the amount of information that remains from the original image is the same amount of information that was replaced by the checkerboard artifact.
We cross-check how much of the ignored pixels in one network (e.g., ResNet-50) are not ignored by a second network (e.g., Inception v3). These results are quite surprising because the amount of information that is preserved does not directly correspond to the “universality” of what remains. For example, the nMI measurements show that Inception uses more information than ResNet-50. Furthermore, the information preserved by ResNet-50 is enough to get a good accuracy with Inception. However, the contrary does not hold. Several of those conclusions can be drawn from experiments related to the RRC values and the formal concept lattice that can be constructed from those.
We show that using an AE whose decoder is finetuned with gradients from the classifier is a viable way of analyzing global patterns that the classifier picks up on (or patterns/biases that the dataset exhibits).
Finally, we discuss the idea of defining the rather elusive notion of “model capacity” (which up until know has informally referred to the amount of layers, filters or neurons that a network has). We want to also include the notion of “remaining signal that is available at a particular layer” (if you went to the talk at GTC you probably remember the pitch ). Towards the end of the paper, we show how other experiments in the literature align nicely with this complementary definition.
Thanks for the discussion! Just to clarify: pooling is known to suffer from the same problem, although to a lesser extent. The Distil paper cites on this:
I know, you caught me on that one. I left it out of the list above on purpose The thing is, I can’t say I fully grasp what goes on inside inceptionv3. But it only has a single 3x3/2 conv at the beginning, whereas the other nets have multiple layers with stride 2. Every inception module also has stride 2 convs, but - those work “in parallel” with stride1 convs and also 1x1 convs and the results get concatenated together. So following your point #4 (re: remaining signal at specific layer) I would think that this would carry much more information down to the lower levels, also the backprop will work in parallel so the effects of these stride2 convs inside the inception modules would probably be reduced a lot, which could be an explanation, but this is only a guess. And just to be clear - I really liked your talk ! And no, right now I have no suggestions, but I will keep thinking…
Are you saying the standalone point (a,b) carries no information and only the neighbour patters do? Or if all the images had pixel X to be the same value(Which is never the case) then the encode would choose to throw away that information?
Can you clarify “What’s important is that the artifacts are consistent between different reconstructions.” What do you mean by ‘consistent’? The artifiacts are the same or consistently different?
More the former. The decoder is essentially throwing away information at fixed pixel positions, regardless of the input sample.
Artifacts (i.e., the patterns that are introduced by the decoder once it has been fine-tuned with gradients from the classifier) are basically the same e.g., they look always magenta across all input samples.
But the picture(and the whole paper) implies otherwise doesn’t it? It is saying that the artificers produced are different therefore different information is used by different nets. The picture in the first post clearly implies this
Artifacts are constant with respect to one network i.e., patterns are “constant” when looking at reconstructions based on one network.
Artifacts across networks reveals that different networks look at different parts of the image i.e., patterns are different when looking at reconstructions from two different networks.