Jeremy,
If you’re looking for porting a Favorita top solution to Fastai library as you did with Rossmann 3rd Place: one of the 1st Place team members in Favorita posted a single Keras+Tensorflow kernel.
https://www.kaggle.com/shixw125/1st-place-nn-model-public-0-507-private-0-513/code
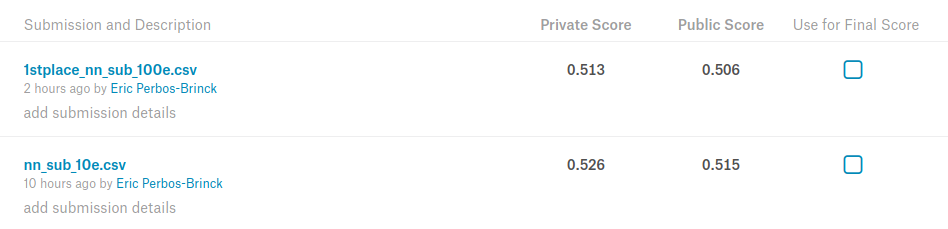
I tested it and it works “out of the box” with Keras: takes about 10hours to run on a 1080Ti and achieves 0.513 on Private LB (3rd place).
Here’s the Favorita Private Leaderboard
Took up to 48 Gb of RAM though during the Join_Tables & Feature Engineering phase (the swap file helped a lot).