My initial tests with given data and enbedings did not give good results. After that I used moving avgs with nn gives 5.14. Now I’m trying to add embedding layer to avg nn might give something like 5.06…
1 Like
I expect so.
1 Like
Hi! Reporting again on this one, its been some weeks already. ![]()
(My main laptop decided to suddenly break just after part1v2 ending -too much work for the unfortunate machine-. So this Xtmas holidays not as much progress as expected… but the laptop is back!
About Favorita, I did manage to do something decent with DL structured approach scoring 0.562, worse than public medians kernel but quite close. Anyway, that medians kernel is possibly overoptimized for the public leaderboard so wouldnt be surprised to see a LB shakeup with better positions for DL approaches.
Anyway… a lot more to think about structured + DL, I have found training speed very slow, I guess GPUs dont like “long” format of data. Also a mistery to me the best relationship/rules of thumb of dropouts in dense layers and embeddings, apart from trial-error.
By the way, Radek,
That result is not that horrible for a first try, better than “last year prediction” benchmark that many real-world retailers still use today… and way better than my first tries. ![]() Public kernel is really hard to beat in Public Leaderboard but, as I said,it is possibly overfitting it.
Public kernel is really hard to beat in Public Leaderboard but, as I said,it is possibly overfitting it.
Well, I don’t think I will do much more on this competition but for me objective was to try structured fastai approach on time series and I consider this first experiment successful already, the thing works!
4 Likes
The problem with “Last year prediction”, as indeed used by many retailers today: it carries the bias of “out-of-stock” SKUs (Stock Keeping Units).
On the other side, what Favorita’s Analytics Team is expecting/stating in this competition is a “God-Mode” only found in Video Games cheat modes: unlimited available inventory, like unlimited ammunition with instant reloading.
But they’ll benchmark competitors’ models to a Real-Life Test dataset, where there’s no unlimited/immediatly available inventory.
They are the only ones to know the true inventory level of the SKUs in the Test set, from Aug 16 to Aug 31 2017.
2 Likes
Hey all,
I just posted my results to the Kaggle forums, https://www.kaggle.com/c/favorita-grocery-sales-forecasting/discussion/47185#266883
tl;dr - I never got better than .547 on the LB with a simple NN using just 4 features, although I learned a ton trying to replicate the approach @jeremy outlined in the Rossman example. Above I shared what I tried and what did/didn’t work.
Happy to share one of my many other notebooks if it helps.
2 Likes
That’s what I did, see Corporación Favorita Grocery Sales Forecasting | Kaggle
1 Like
Thank you - this is good to know. 
I appreciate you sharing this especially as I know how much time this competition can require and how much time you probably had to invest to get to this point.
My big take away here is that one has to take a very organized approach to processing the data and to constructing models. I think I knew this intellectually, but it is a completely different ball game when you jump into actually working on a problem.
I started working on this competition reproducing the Rossman notebook from Jeremy (which BTW I think is an absolutely fabulous learning resource). Being relatively new to pandas I struggled a bit with the API and also invested quite a bit of time into working with relatively big amounts of data with comparatively little hardware resources.
The crux of the matter is that after many, many lines of code, since I didn’t work on this incrementally, I have no clue now why my model is not working as well as I would expect that it should (given the data I feed it I would expect even a simple linear regression to outperform the LB score of 0.546 achieved via taking a mean of medians…).
I tried verifying my data processing pipeline, but that is a lost cause at this point - too much code, processing data on even a beefy AWS instance takes time, impossible now to bolt on checks, hence I am working on this from scratch. Will start with a very simple mean that gets 0.558 on LB and will be incrementally adding things to this, both adding features to the data and working on more complex models. Small, incremental steps - hopefully this will make navigating the complexity of this possible.
Only unfortunate bit is how little time is left in this competition as I would like to give it a proper go, but I probably gave it my best. There will be other challenges to work on and I feel learning the process of doing machine learning is very valuable in itself. Hopefully I’ll be able to put it to good use at some point 
3 Likes
Yes, yes! That’'s how I feel as well. I’m ready to move on to another challenge. I was also relatively new to pandas and found this exercise to be a great boot-camp.
Here are the steps I will follow in the future:
- Start by thinking of possible features. Assume most of the data won’t be predictive of anything.
- Examine each feature, do some EDA to identify predictability.
- Start with a simple model first using a subset of data which is easy to handle.
- Get some early baseline results.
- Tune the model to try and improve the results. Get the best results you can by changing model design, type, learning rate, epochs, dropout, etc. Stop when you can’t improve.
- Add more data to see if results improve. If not, back off and just use the smaller set.
- Restart this process by looking for more features.
1 Like
I realised this when I do things from scratch…
After the competition gets over,
Can you people make your kernels/notebooks public on this platform…
It will really help me ton to see the messy code…
Another key learning …
Kaggle is an incredible resource for getting skills and learning. I learned a ton reading through others’ Kernels and work. But ‘winning’ isn’t terribly important since optimizing a model for one small dataset over a small window isn’t terribly important to me.
I’m also not discouraged by a lower ranking if I’m building a stable model and gradually improving it. It seems like most of the Kagglers are just copying Kernels and submitting results. Many do not seem to even understand what they are doing - they kind of “developers” who can’t pass the fizz-buzz question during an interview.
I’m not interested in hiring the people who score high in the contests - I want to hire those who understand why they’re doing something and can follow a systematic process for making improvements.
Ok … off the soapbox.
2 Likes
3 Likes
Thank you…
Per @jeremy’s comment on ‘zero rows’, here is how I did it:
u_dates = train.date.unique()
u_stores = train.store_nbr.unique()
u_items = train.item_nbr.unique()
train.set_index(['date', 'store_nbr', 'item_nbr'], inplace=True)
train=train.reindex(pd.MultiIndex.from_product((u_dates, u_stores, u_items),
names = ['date', 'store_nbr', 'item_nbr'])).reset_index()
train.unit_sales.fillna(0, inplace=True)
train.onpromotion.fillna(0, inplace=True)
1 Like
I started using massive batch sizes of 100,000 or more. Not only did it accelerate training by using more GPU memory but it converged better. I think it is because I only had 4 features and updating in smaller batches allowed the gradients to overshoot.
It only took 3 training epochs with gradually decreasing LR size for my model to converge. See the code I posted for parameters.
1 Like
I just re-watched Lesson 14. @jeremy says a few words about the challenges of debugging Deep Learning:
So, so, so true …
1 Like
Ah yes, these things tend to be somewhat tricky.**
In my case it turns out there were several subtle and not so subtle bugs during data processing. I threw everything out and started from scratch, trying to verify each step along the way. The bugs ranged from improper use of shift and ffill with groupby (well, at least the outcome was not what I was after but pandas was not complaining ) to extra forward slash in path to a file being written, etc.
The debugging techniques I posted to Twitter not too long ago turned out to be very helpful I have never really used them much before hence wrote those couple of tweets and a miracle happened - I had somewhere to look those commands up (my TW) and also got myself better acquainted with them. Both %debug and set_trace() feel very natural to me now and were very helpful! Even doing stuff as calling set_trace() inside a lambda passed to apply is possible - hands on learning!
Not to get overexcited - not sure if I can take it much further. Thus far put the barebones of a pipeline in place, trained a simple model on a single 14 day rolling mean. Just taking a 14 day mean on the last 14 days of the dataset grouped by store_nbr and item_nbr get 0.558 on the LB and I was able to get 0.556 - meaning there is a high chance the data transformations that are in place thus far can be okay
I could end this post moping that there is so little time left and that even getting a more complex deep learning submission in will be a success, but let me rather finish this on a high note - this is complex, meticulous at times, but is also so much fun!!! Already looking forward to doing something more with structured data in the future, where maybe I will have a chance to play around with autoencoders and random forests / gbm etc.
** Sentence nominated for the understatement of the year award.
1 Like
Hi Kevin @kevindewalt ,
I was just looking at the kernel you posted on Kaggle and GitHub, great work and very elegant/kind of you to share 
Just for the sake of understanding the metrics: you named your Kernel posted on Jan-8 as “Simple 4-feature Neural Network for LB 0.547” but I see on the Public Leaderboard that your latest submission on Jan-8 got a score of “0.529”.
Are they the same kernel ?
/respect
EPB
No, the 0.529 submission was achieved by copying the paulo pinto kernal I reference. Afterward I derived the same features and used NNs.
1 Like
I’m scratching my head here: I’ve trained a model, based on Rossmann notebook principles, using:
md = ColumnarModelData.from_data_frame(PATH, val_idx, df, y.astype(np.float32),
cat_flds=cat_vars, bs=2048, test_df=df_test)
But when I use pred_test = m.predict(True), I get a massive Stack Trace with:
RuntimeError: running_mean should contain 3 elements not 1
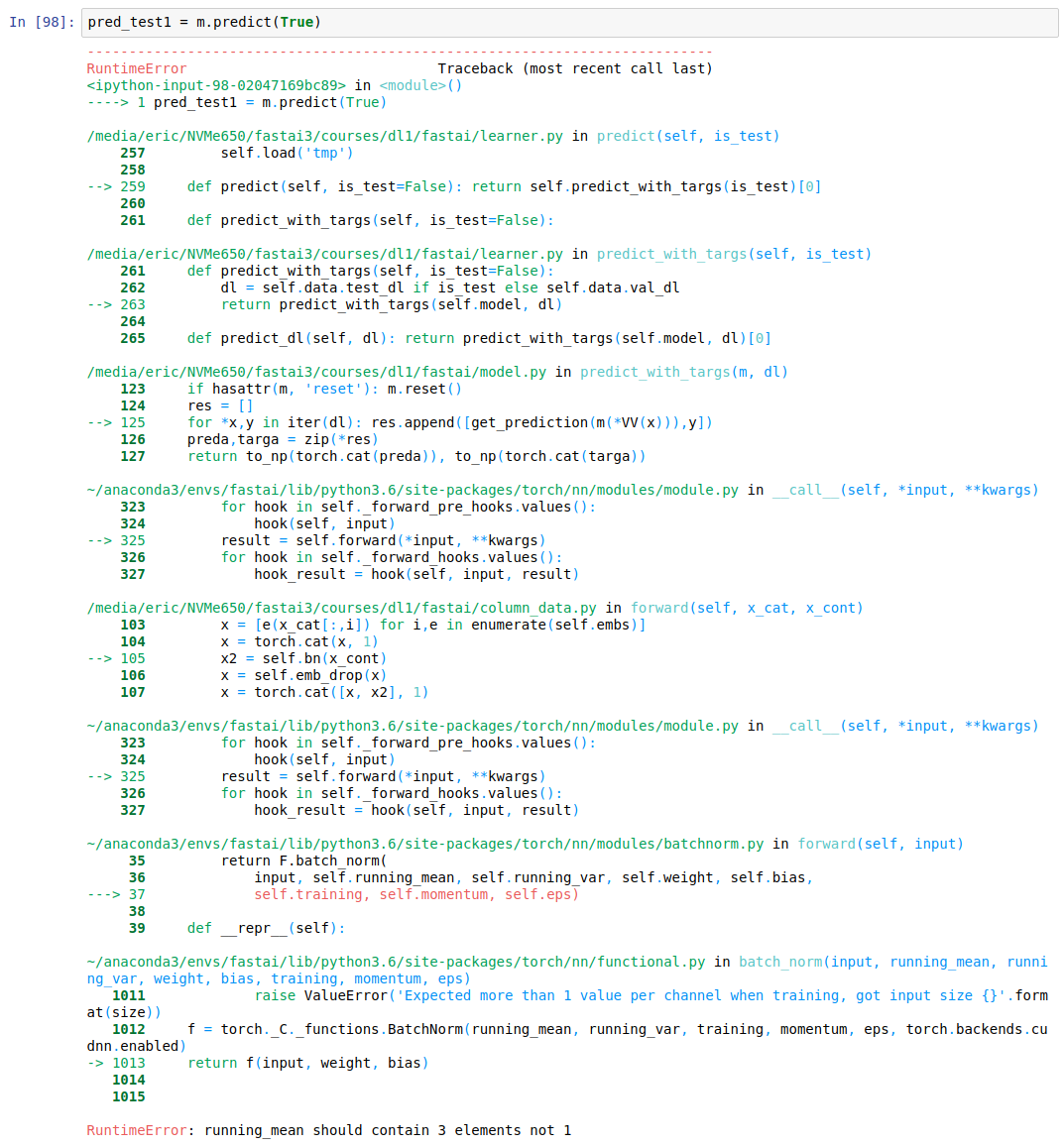
Any idea what I’m doing wrong ?
@EricPB, I faced it while trying with keras. I’m not sure if its the same problem. The embedding layer outputs 3 dim and the normal keras outputs were 2 dim. so you should resize the inputs and and outputs for 3 dims. (3,x) to something like (3,1,x).