Hi everyone, I joined the course this week and doing first week’s assignment. I am working on several data sets. One of those is copy-move image forgery dataset that can be found at this link: http://www.vcl.fer.hr/comofod/comofod.html
I am treating this as classification problem and feeding images as 4 classes: Original, Forger, Masked and Binary Masked. Then training the models as per the lesson1 notebook.
My question is, is this the correct approach for this problem? Sorry I am new to computer vision don’t know much how to treat different problems. Please let me know. Thanks.
My resent50 validation accuracy is really good : 95.6%. 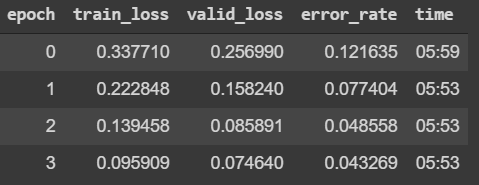
I am also working air quality prediction using images. Will share results soon.
My question is, is this the correct approach for this problem?
I will assume your goal is to eventually infer/predict if any image is original or forged.
I have no domain expertise but it seems like this classifier would work well on masked and binary masked classification, since those have obvious differences, but not so much for the goal above.
For an original vs forged, one would need to establish some sort of a relation within an image set (by set I mean 4 images of same subject, one for each label). Otherwise the classifier has no way to determine if repeated objects in an image are part of the image or copy-pasted in through forgery.
UNLESS, the forging process changes the pixelation around the added-in portions and the model is picking that up as the unique trait/identifier. (Don’t know enough about the how the forged images are created so this is a guess!).
Could you try this only on two classes, original and forged. And then run inference on a few test images (not part of training or validation sets)? I could be wrong here, but I suspect the error rate will go up.
Interesting problems! All the best!
1 Like
Hello Nalini,
Thanks a lot for your reply and answer. I have been business travelling for past some days and finally sitting down to work again. I will implement your suggestions and post colab notebook here.
I think you are right, the error rate will go up with just two classes as the model is very accurate for masked and binary masked classes. Let me rerun everything. I will share tomorrow.
Thanks 
1 Like
I managed to get better accuracy with just two classes. Just had to run the training for 20-25 epochs. The model is able to predict the classes of holdout set correctly. I suspect data leakage.
I will check the train, validation and holdout set for data leak. The results are surprising to me as I am not a computer vision expert.
Here is the colab notebook if you would like to take a look.
https://colab.research.google.com/drive/1c10n7rDXmZE_XaCc73Be4ZMaO-wybyx_?authuser=1#scrollTo=VQqxofO566gs
Hi Amit,
Sorry for the late response. I looked at the colab, and one thing that pops out is that your Training loss is consistently higher than your Validation loss. Afaik this is a sign that the model has not be trained enough (i.e. is under-fitted). I’m not any expert! But I definitely think that given the VERY MINOR differences in your F and O images, under-fitting is a problem. You can see if training for more epochs or setting a higher learning rate fixes this. Note that the error/accuracy is calculated on the validation set. So a low error rate alone doesn’t imply a model is sufficiently trained.
Also, I’m curious why you suspect data leak? Does the dataset have duplicates? From your interp losses it seems like a single Original image can have multiple Forged images? Could this be considered a data leak?
Hope this helps! I’ve not seen anyone attempt such a fine grain classification, so it’ll be interesting to see if its doable!