I ran the test in two parts, and compared it to the original Resnet implementation ( FasiAI’s Siamese Tutorial)
- ConvNeXt Body with FastAi’s head
- ConvNeXt Body with a new head that takes clues from the ConvNeXt paper, and has:
- GELU instead of ReLU
- No BatchNorm, has a single LayerNorm2D
- No Dropout (I just used the
Linear portion of LinBnDrop)
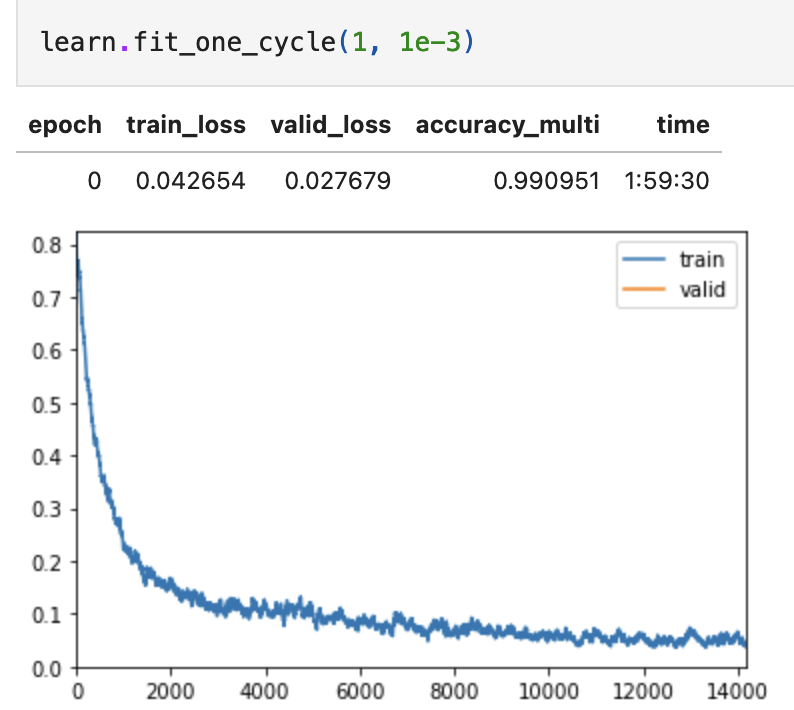
Original Resnet Based Training(for reference) with these two parts. This old training was done using Resnet50:
Resnet fit_one_cycle() reference:
Resnet training/convergence reference:

Part 1 : Test the same dataset, with ConvNeXt body, but with Resnet head from create_head()
The Last layers of a convnext_t model are as:
CNBlock(
(block): Sequential(
(0): Conv2d(768, 768, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=768)
(1): Permute()
(2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(3): Linear(in_features=768, out_features=3072, bias=True)
(4): GELU(approximate=none)
(5): Linear(in_features=3072, out_features=768, bias=True)
(6): Permute()
)
(stochastic_depth): StochasticDepth(p=0.1, mode=row)
)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=1)
(classifier): Sequential(
(0): LayerNorm2d((768,), eps=1e-06, elementwise_affine=True)
(1): Flatten(start_dim=1, end_dim=-1)
(2): Linear(in_features=768, out_features=1000, bias=True)
)
FasiAI’s create_head() chops off the last pooling layer, and adds this instead :
Sequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): Flatten(full=False)
(2): BatchNorm1d(1536, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25, inplace=False)
(4): Linear(in_features=1536, out_features=1024, bias=False)
(5): ReLU(inplace=True)
(6): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5, inplace=False)
(8): Linear(in_features=1024, out_features=1, bias=False)
)
Training with the same dataset:
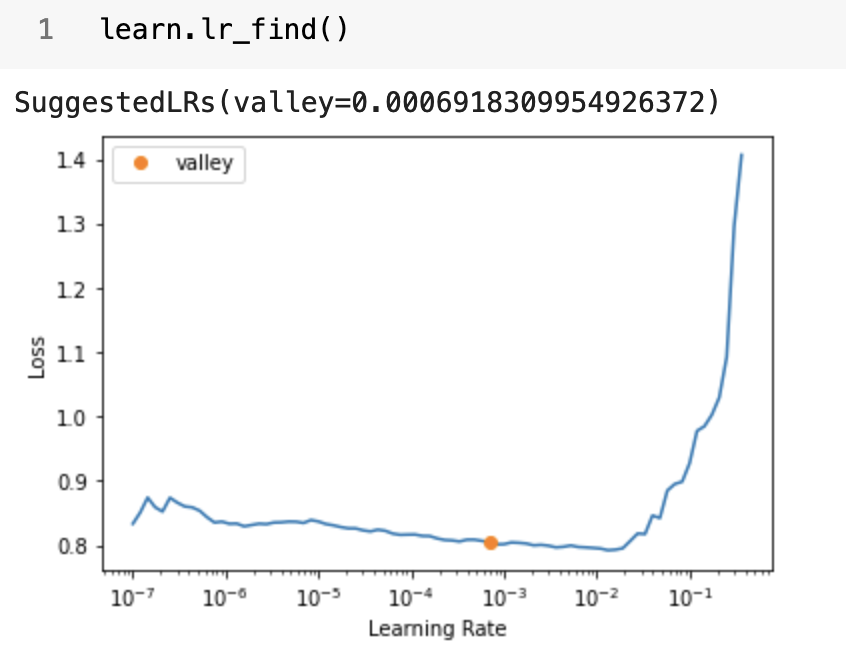
lr_find() :
Training with learn.freeze():
The model is not really able to utilize transfer learning from the ConvNeXt body.
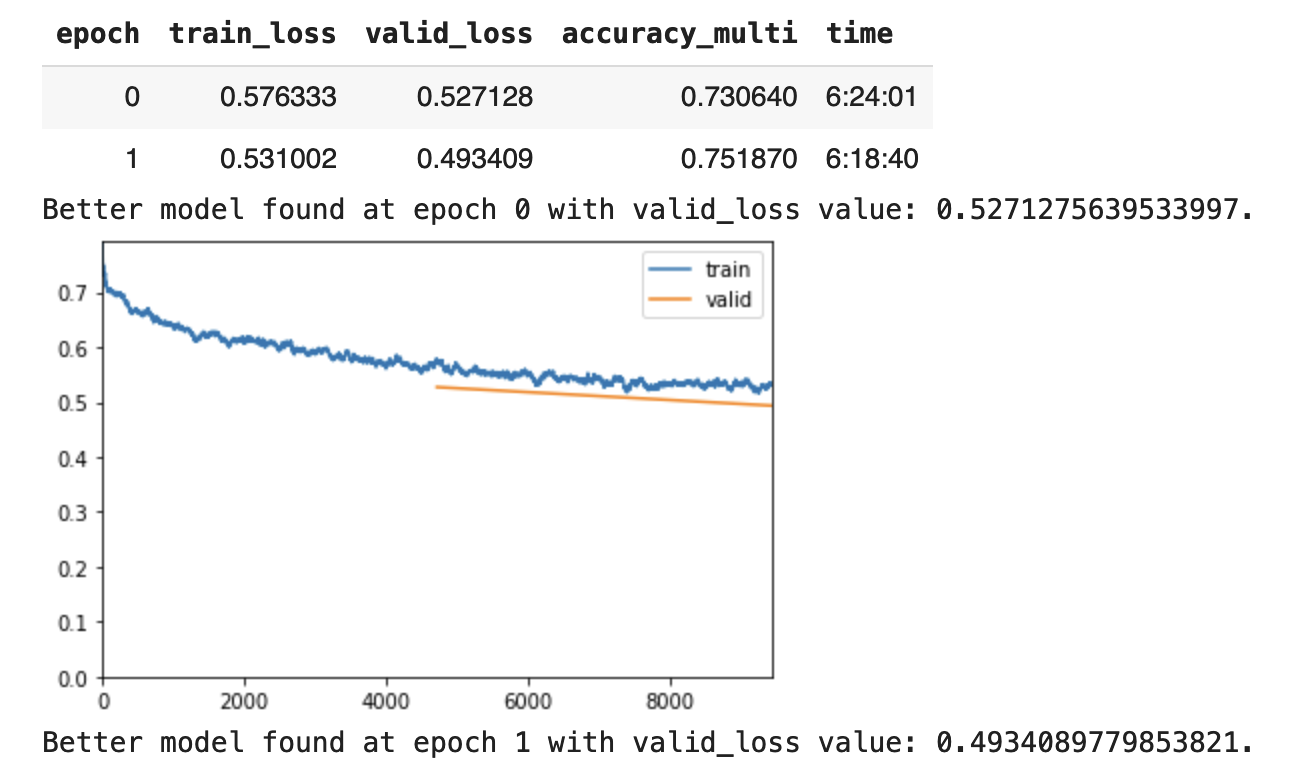
Training with learn.unfreeze()
(Sorry, the kernel restarted here, but the model does’nt get much better than this and the error rate flattens around at around 95% accuracy)
Part 2 : Test the same dataset, with ConvNeXt body, but with ConvNeXt-based head (GELU, no BN, no Dropout etc)
Instead of the FastAI head, I used this head:
Sequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): LayerNorm2d((1536,), eps=1e-06, elementwise_affine=True)
(2): Flatten(start_dim=1, end_dim=-1)
(3): Linear(in_features=1536, out_features=1024, bias=True)
(4): GELU(approximate=none)
(5): Linear(in_features=1024, out_features=1, bias=True)
)
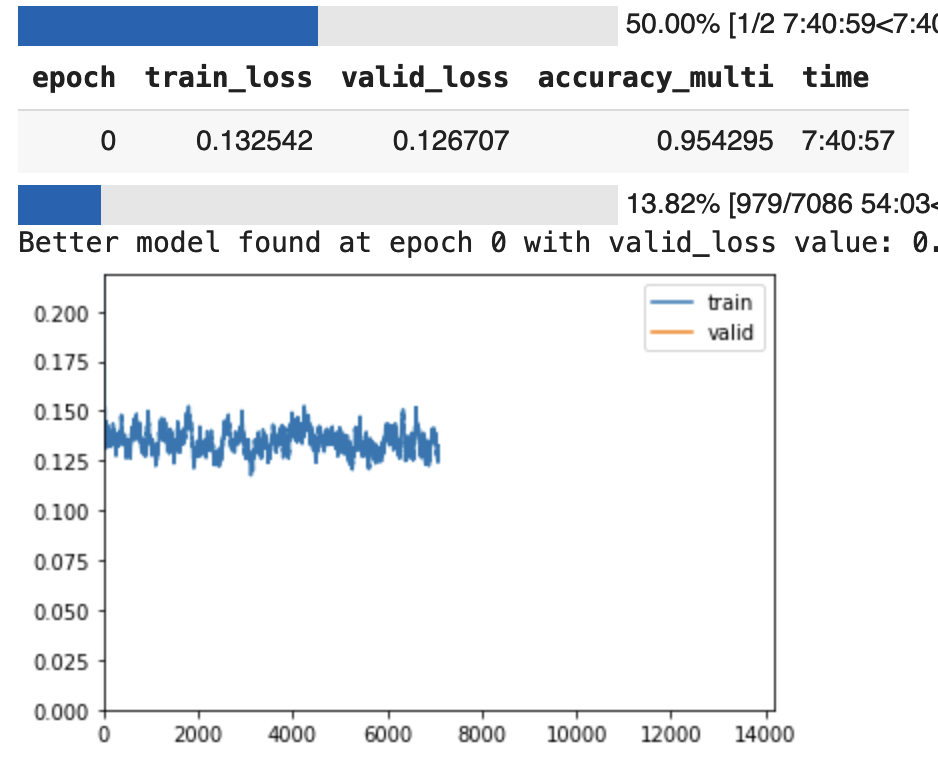
Output of last the few epochs :
This head too, taps-out at around 95% accuracy.
Results:
- A Resnet based body appears to perform better than a ConNeXt body, no matter the choice of head. They had higher accuracy than both of the ConvNeXt experiments.
- Resnets utilize transfer-learning much better than ConvNeXt.
learn.freeze() training outputs give far better accuracy for Resnets.
- Resnets converge really fast. ConvNeXts took much longer to converge. Maybe it is in line with this excerpt from ConvNeXt paper. ConvNeXts are trained for more than three-times the epochs for an equivalent Resnet.
Still trying to figure out how to improve ConvNeXt based training, over Resnets, for a Siamese Network 
Warm Regards
-Gary