Notice that Conv1d expects an input of dims [batch size, number of channels, length] the kernel size of 3 won’t change the output dimension if you add padding of 3//2. If you just have 1 channel you can do an input.view(128, 1, 248) but the output will be (128, 128, 248) as you have selected 128 output channels. Are your inputs time-series or something similar?
Not really my inputs are tabular features but i want to try a CNN over them. So basically i have 248 columns of which 199 are cont and 49 is an embedding. I then want to use a conv1d as the first layer of the network. I copied the TabularModel and added the following in the beginning:
layers = []
layers.append(conv_layer(ni=1, nf=248, ks=3, bias=None, stride=1, padding=None, is_1d=True))
for i,(n_in,n_out,dp,act) in enumerate(zip(sizes[:-1],sizes[1:],[0.]+ps,actns)):
I haven’t added dilation yet either but i want to try a couple of conv1d layers with dilation and then the typical couple of dense layers after that. It’s also extra confusing because of the fact that model.summary doesn’t work if you have your dimensions wrong (which totally defeats it’s purpose) and torchsummary doesn’t seem to work with a fastai tabular model (that takes both cont and cat features as parameters for forward).
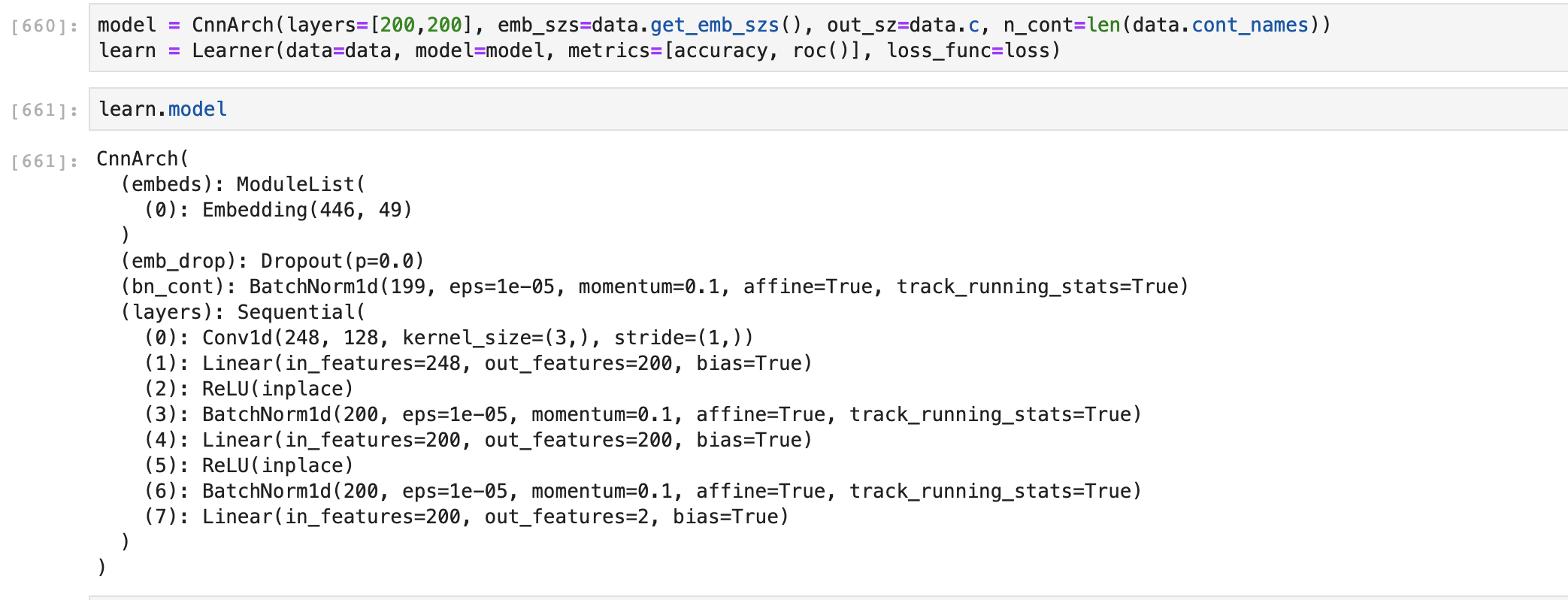
I tried adding the view code you mentioned as well as unsqueeze(1) and they both result in the same error at the BN layer, which is rather weird since i don’t see 2 layers after eachother with those dimms (attached)
Then you write set_trace() in the forward of the model (or any other place you need to debug) and you can go line by line and print the sizes.
But if you are using a 1d convolution kernel over your inputs you are computing linear combinations of nearby features. Unless your features have some particular order that is important (like in a time-series) I don’t see how that can help. The regular linear layer combines all the features together.
Thanks for the suggestion I’ll try the debugger. It’s rather suprising to me too, why would that be the case but several people reported that switching from dense to cnn got them a boost from ~86 to ~89/90 ROC in this competition: https://www.kaggle.com/c/santander-customer-transaction-prediction/discussion
So i just wanted to try and replicate that within fastai. I tried a lot of dropout after the first FC layer as a substitution for that but it didn’t help the overfitting too much. Maybe I should try dropout on the inputs and see if that actually helps more.
Hey Feras, can you link to the actual discussion? That sounds interesting, but I poked around and didn’t see anything similar.
Highly recommend set_trace debugging. It’s really useful for understanding layer sizes and where things are going wrong and you gain a much deeper understanding of the network that way.
Sure, I think this mentions it, but I did see it in a few more places mentioned as well. I’m not sure if the idea is to act more as a regulariztion (my thought, by sampling a lesser amount of the features), or the idea is more so to pick up some spacial interaction between features (but then my guess is that would be picked up by the dense layers anyways and it would just push the rest of the irrelevant weights closer to 0). It’s a very weird competition, where the mean you get with GBM is about 0.9 and nothing seemingly works.