Hi @jeremy ,
I’ve made a quick tour of the new Fastai library that’s a framework as you mentioned.
I would like to start making simple contributions like commenting the methods.
I think everyone who types SHIFT+TAB is expecting to see a description of the method but
at the current stage some methods are self-explanatory but for some other we must test them
before understanding what they do.
And I think with this community, it’ll go fast to have the framework documented.
What do you think about that ? or you didn’t plan it to be done for now?
4 Likes
I would love that  This is a great thread for us to discuss any contributions to the framework, or questions about it.
This is a great thread for us to discuss any contributions to the framework, or questions about it.
1 Like
So Where to start?
In fact I’ve never done a pull request! I’ve just heard about that.
So should post here comments I made for a method then receiving comments and finally commit it to github?
I think it would be useful to allow fastai to run on CPU too (primarily for code development using small sample data). I saw a few places where .cuda() is called. I wrapped that around if (torch.cuda.is_available()) but then ran into some other deeper problem.
Is there anything in the design that fundamentally prevents that? If not, is it worth investing in the path to get it to work on CPU?
2 Likes
Here’s an easy way to create a PR: GitHub - mislav/hub: A command-line tool that makes git easier to use with GitHub.
Yes definitely worth it. It shouldn’t take changes to more than a couple of lines of code - if it does, we should figure out how to simplify it!
It’s not exactly a contribution, but I’ve been thinking that, if you ever release it independently of fast.ai, you could call it “Prometheus”, as it’s bringing PyTorch to humans.
2 Likes
I am happy to help with pull requests.
Hi @jeremy -
I created a Pull Request to make the code compatible with GPU and CPU. More details here - https://github.com/fastai/fastai/pull/12
Any feedback from Jeremy or anyone on this thread is greatly appreciated.
1 Like
This name sounds good but is a bit long.
As you might notice @jeremy likes short names, tfms(transformations), sz(size).
No fluff, just to the point and I find fastai to be very good, short and the name stands for what it is for:
start playing with your Deep Learning model with the least lines of code.
I can contribute to writing docstring as well. I think it is good to have a consistent format so that different parts of the library do not use different format though.
Any preferences, @jeremy?
Otherwise, would something like this work okay?
''' Brief description of a function
A little more detailed description of a function
:param arg1:
:param arg2:
:return:
'''
Oh! I see google style docstring in conv_learner.py. Should we use https://google.github.io/styleguide/pyguide.html?showone=Comments#Comments ?
1 Like
Tried it. Works well! Ship it
prmths?
Thanks! @yinterian has written the docstrings that are there now, so use the same approach as she has, unless you think there’s a better way, in which case please let us know what/why and we can discuss here.
That’s a really nice name. Although I think we’re going to stick with calling it ‘fastai’ ![]()
1 Like
Sounds good! It looks like transforms.py has the most docstrings, so I will follow suit
1 Like
I have submitted https://github.com/fastai/fastai/pull/11
This pull request fixes a bug and has a version of read_dirs which is atleast 3x faster on my machine.
It’s great to have access to a working codebase. There are a few TODO’s ( @jeremy: breadcrumbs?). This could be a place to start making contributions 
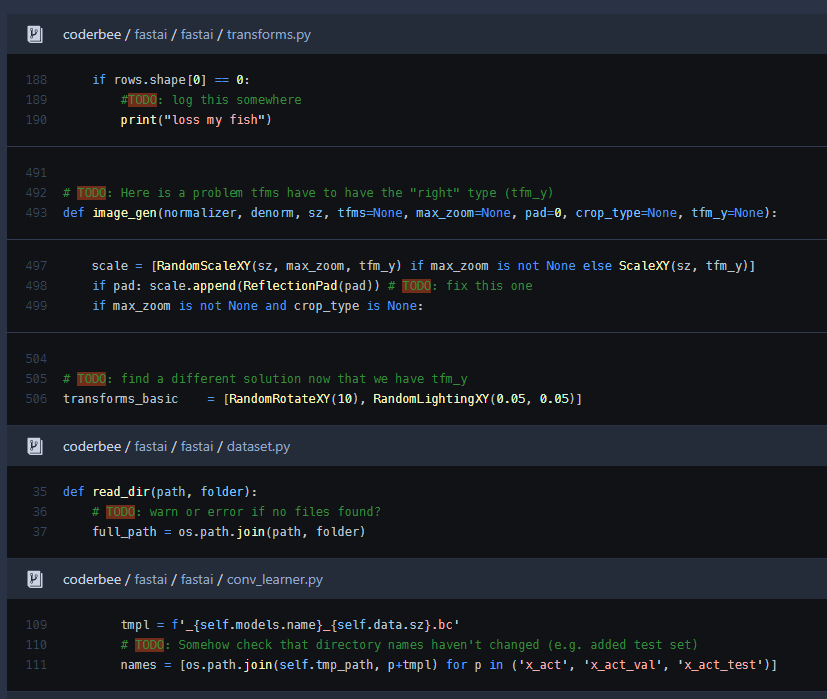
I think nearly all of those TODOs are from @yinterian, so we should ping her!
When making changes to the code, try to add a test that shows that the new code works, if possible. Currently, there are no tests, which is of course not how we want things long term!
2 Likes
One problem that we are having is that sometimes your code breaks because tmp directory is missing something. We need stronger checks there.
inside this function
def get_activations(self, force=False):
One case that breaks is the following: (1) run your code without providing a test folder (2) run your code after providing a test folder.
Let me know if this makes sense. Thank you!
1 Like