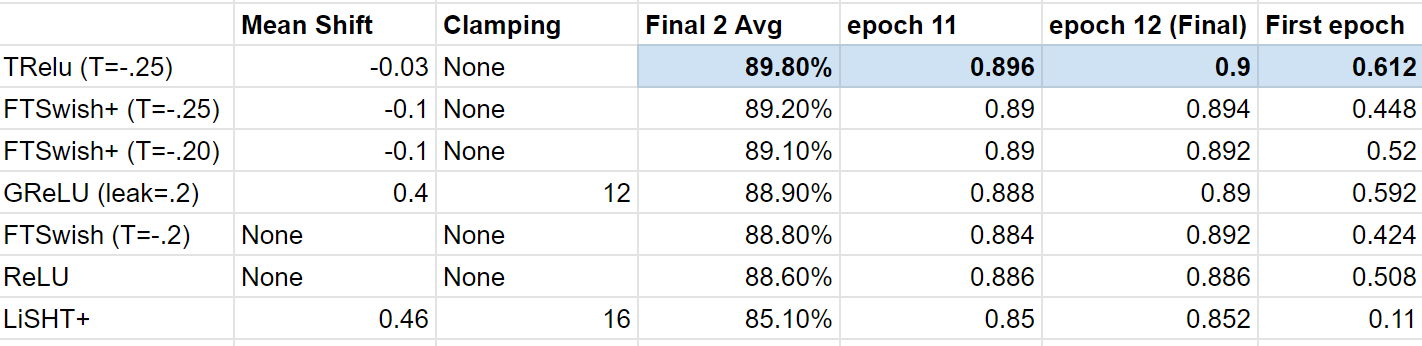
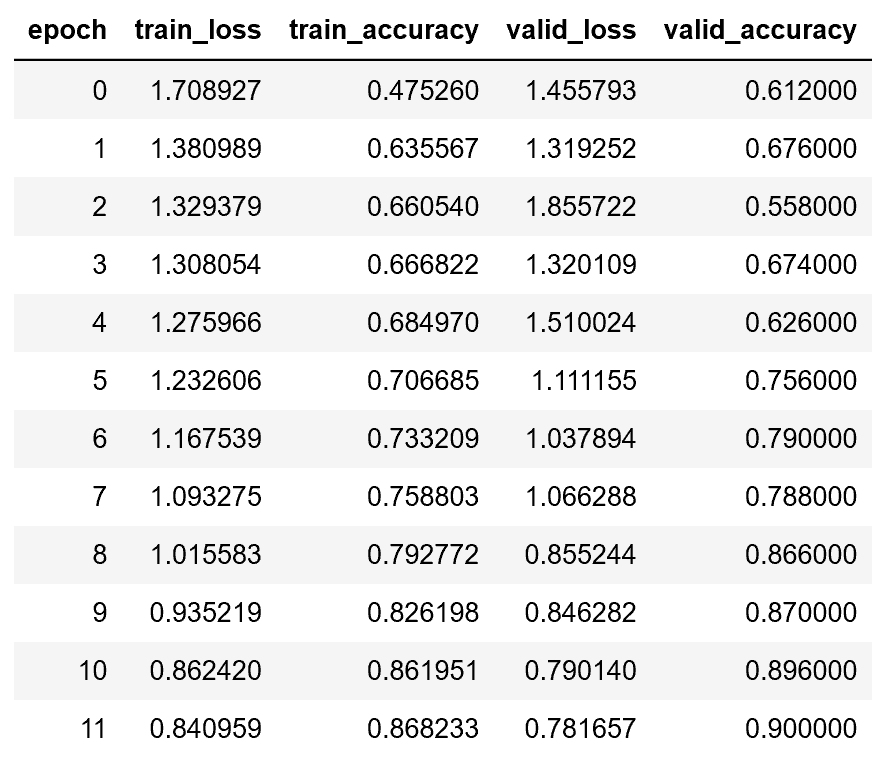
Edit and update: Based on a question by @yonatan365, a new activation function was made, TRelu, and that is now the new winner of this initial runoff. Originally it was FTSwishPlus…details in the thread but wanted to clarify why early posts talk about FTSwishPlus as the winner…details in the thread!).
There were two new papers on activation functions on Arxiv recently, and I thought it would be interesting to put them to the test along with GeneralRelu and of course ReLU.
In brief, the two new activation functions:
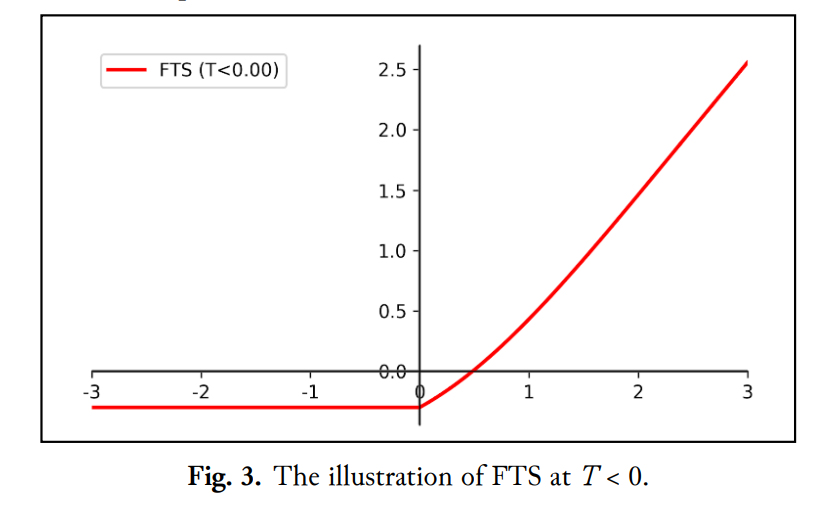
1 - Flattened threshold swish: A swish-like activation with near equivalent value for positive values (x*sigmoid(x) + threshold), and a fixed (flat) threshold for negative values. (x = threshold). Their recommended default for this threshold is -.2.
Paper: https://arxiv.org/abs/1812.06247
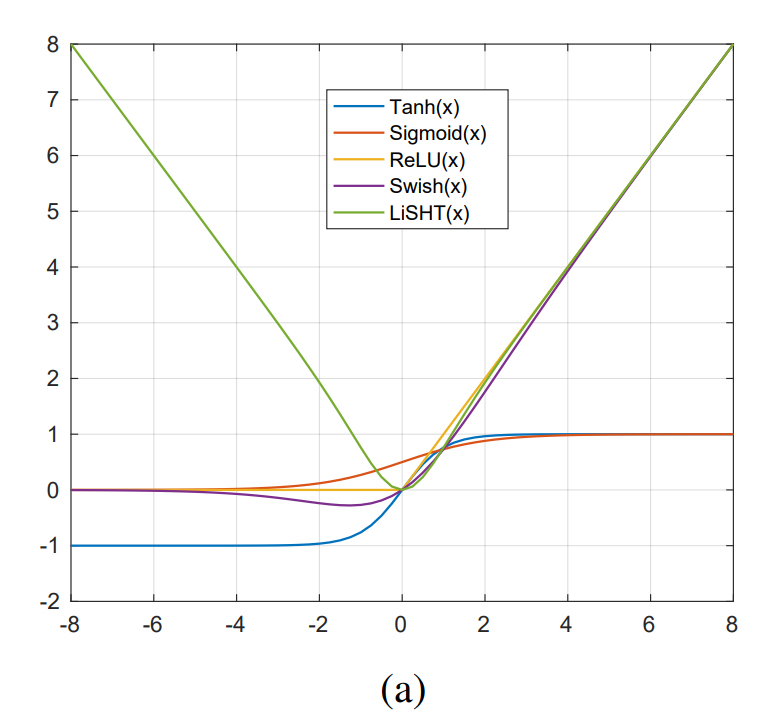
2 - Linear Scaled Hyperbolic Tangent - LiSHT - provides a parabola shape activation where negative values are scaled as their absolute value, and thus become positive. Code is simple: x = x *torch.tanh(x)
Paper: https://arxiv.org/abs/1901.05894#
3 - General ReLU - you already know this one, but Relu + mean shift + leak + clamping.
4 - ReLU - used as the ‘baseline’ for comparison.
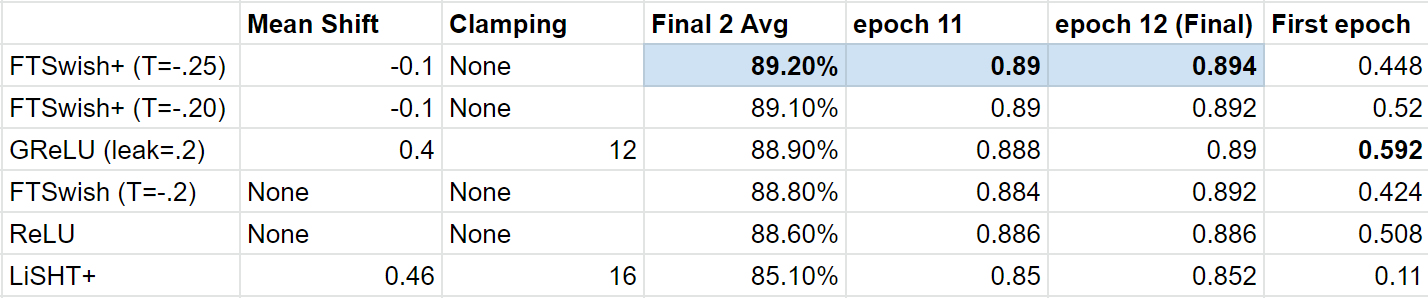
Results: After testing all four on ImageNette, (XResNet18, cyclical learning with lr=1e-2) for up to 40 epochs each, General Relu was the winner. However, I then decided to add mean shift + clamping to both LiSHT and FTSWish to make LiSHT+ and FTSwish+.
Clamping stabilized the training path (i.e. epoch accuracy gains were steadier) but ultimately ended up short in terms of final accuracy.
However - the mean shift on FTSwish+ turned out to be a very big improvement.
The mean shift was surprisingly, - .1.
After that, FTSwish+ took top place with - .2 threshold.
I then tested - .3 and - .4 which did well but not as well as - .2…
Finally, I tested with - .25 (as - .3 had done quite well and -.2 was the current winner), and that proved to be the final winner. The original paper found -.2 as the optimal threshold, but since it was for MNIST, I was not surprised to see a slightly larger threshold improve it for 3 channel images.
Here are the results:
One other bonus for FTSwish+ was the path per epoch was very smooth.
ReLU and GRelu for example both had epochs that were worse than a previous epoch…by contrast FTSwish+ was very smooth with progress every epoch and worst case the same - never a step backward. This was also true with LiSHT+, except it was never able to arrive at a competitive ending accuracy (I did let it run additional epochs to see what would happen, but it tended to stall out).
Here’s the code for FTSwish+ if you would like to try it:
class FTSwishPlus(nn.Module):
def __init__(self, threshold=-.25, mean_shift=-.1):
super().__init__()
self.threshold = threshold
self.mean_shift = mean_shift
#warning - does not handle multi-gpu case below
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def forward(self, x):
#FTSwish+ for positive values
pos_value = (x*torch.sigmoid(x)) + self.threshold
#FTSwish+ for negative values
tval = torch.tensor([self.threshold],device=self.device)
#apply to x tensor based on positive or negative value
x = torch.where(x>=0, pos_value, tval)
#apply mean shift to drive mean to 0. -.1 was tested as optimal for kaiming init
if self.mean_shift is not None:
x.sub_(self.mean_shift)
return x