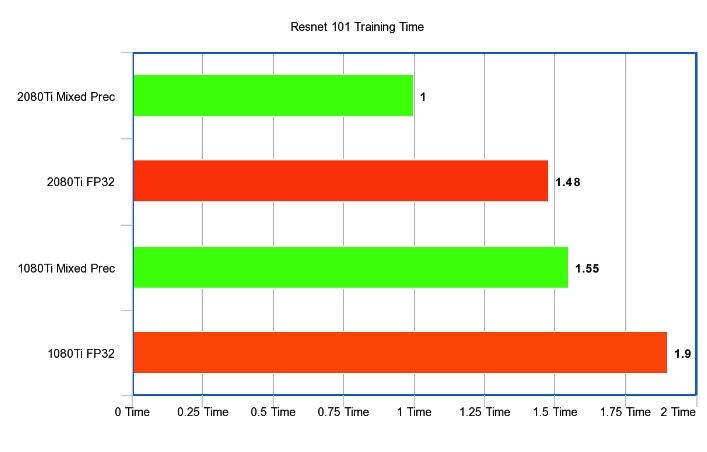
Comparision between .to_fp16() and .to_fp32() with MNIST_SAMPLE
Test environment:
Firstly, run the following command to get the software and hardware info.
from fastai.utils.collect_env import *
show_install(1)
```text
=== Software ===
python : 3.6.6
fastai : 1.0.39
fastprogress : 0.1.18
torch : 1.0.0
nvidia driver : 410.93
torch cuda : 10.0.130 / is available
torch cudnn : 7401 / is enabled
=== Hardware ===
nvidia gpus : 1
torch devices : 1
- gpu0 : 7951MB | GeForce RTX 2070
=== Environment ===
platform : Linux-4.15.0-43-generic-x86_64-with-debian-stretch-sid
distro : Ubuntu 16.04 Xenial Xerus
conda env : step
python : /home/hogan/anaconda3/envs/step/bin/python
sys.path : /home/hogan/anaconda3/envs/step/lib/python36.zip
/home/hogan/anaconda3/envs/step/lib/python3.6
/home/hogan/anaconda3/envs/step/lib/python3.6/lib-dynload
/home/hogan/anaconda3/envs/step/lib/python3.6/site-packages
/home/hogan/anaconda3/envs/step/lib/python3.6/site-packages/IPython/extensions
/home/hogan/.ipython
Thu Jan 24 20:55:14 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.93 Driver Version: 410.93 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 2070 Off | 00000000:05:00.0 On | N/A |
| 31% 30C P8 16W / 185W | 394MiB / 7951MiB | 8% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1596 G /usr/lib/xorg/Xorg 167MiB |
| 0 4521 G 13MiB |
| 0 4925 G /usr/bin/gnome-shell 125MiB |
| 0 8110 G ...AAAAAAAAAIAAAAAAAAAAgAAAAAAAAA --servic 42MiB |
| 0 16638 G ...-token=543973B623488F4E2BC9F280625EB8CA 33MiB |
+-----------------------------------------------------------------------------+
```
Please make sure to include opening/closing ``` when you paste into forums/github to make the reports appear formatted as code sections.
train MNIST_SAMPLE with .to_fp16()
- Run following codes in jupyter notebook.
from fastai import *
from fastai.vision import *
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
model = simple_cnn((3,16,16,2))
learn = Learner(data, model, metrics=[accuracy]).to_fp16()
learn.fit_one_cycle(5)
for p in model.parameters():
print(p.type())
Total time: 00:18
| epoch | train_loss | valid_loss | accuracy |
|---|---|---|---|
| 1 | 0.202413 | 0.136330 | 0.949460 |
| 2 | 0.102659 | 0.092405 | 0.970559 |
| 3 | 0.077279 | 0.069442 | 0.974975 |
| 4 | 0.064258 | 0.059099 | 0.979392 |
| 5 | 0.062370 | 0.058341 | 0.978901 |
torch.cuda.HalfTensor
torch.cuda.HalfTensor
torch.cuda.HalfTensor
torch.cuda.HalfTensor
torch.cuda.HalfTensor
torch.cuda.HalfTensor
The Gpu memory and memory usage are as follows:
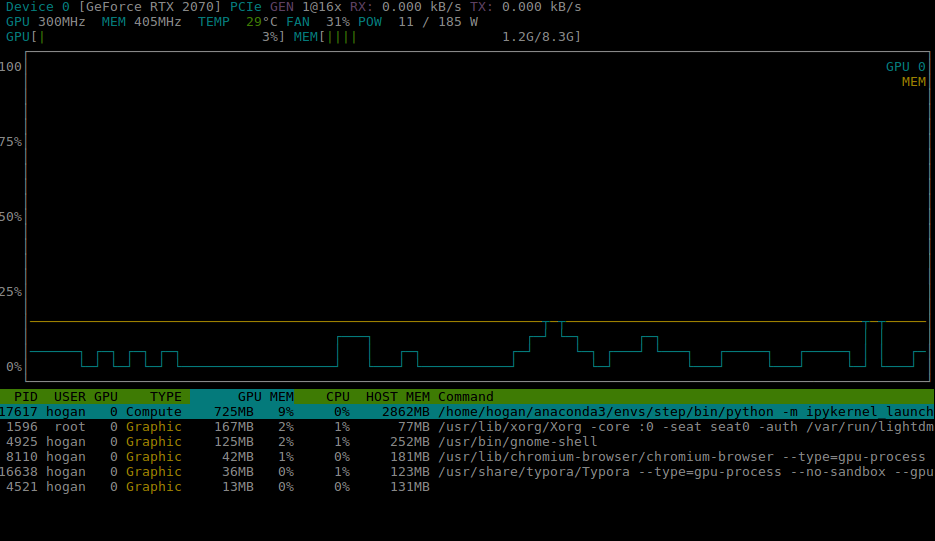
- GPU Memory 725M
- Memory 2862M
- Total time: 00:18
- Run kernel-> Restart, then test for .to_fp32()
train MNIST_SAMPLE with .to_fp32()
from fastai import *
from fastai.vision import *
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
model = simple_cnn((3,16,16,2))
learn = Learner(data, model, metrics=[accuracy])
learn.fit_one_cycle(5)
for p in model.parameters():
print(p.type())
Total time: 00:18
| epoch | train_loss | valid_loss | accuracy |
|---|---|---|---|
| 1 | 0.205327 | 0.134014 | 0.951423 |
| 2 | 0.094773 | 0.072822 | 0.974975 |
| 3 | 0.066074 | 0.059597 | 0.978410 |
| 4 | 0.049261 | 0.045921 | 0.984789 |
| 5 | 0.045165 | 0.045733 | 0.985280 |
torch.cuda.FloatTensor
torch.cuda.FloatTensor
torch.cuda.FloatTensor
torch.cuda.FloatTensor
torch.cuda.FloatTensor
torch.cuda.FloatTensor
The Gpu memory and memory usage are as follows:
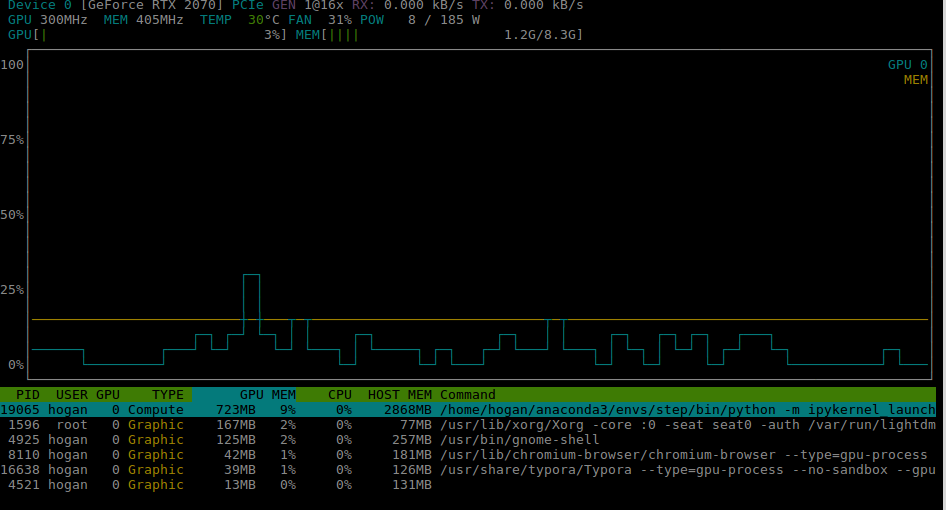
- GPU Memory 723M
- Memory 2868M
- Total time: 00:18
Conclusion
Dataset: MNIST_SAMPLE
| method | GPU memory | Memory | Total time |
|---|---|---|---|
| to_fp16() | 725M | 2862M | 00:18 |
| to_fp32() | 723M | 2868M | 00:18 |
So, is three anything wrong? I can not improve the training from neither GPU memory usage nor time…