I am about to apply collaborative filtering for matching target audience of different advertisement campaigns and sites/applications. Before some real examples lets take a look at lesson 5 notebook:
- 671 Users, 9066 movies, 1.6% non empty cells in matrix
- Accuracy on train / test : 0.61688 0.76318 (mine real results)
So, we slightly overfit and accuracy on train set should be slightly better.
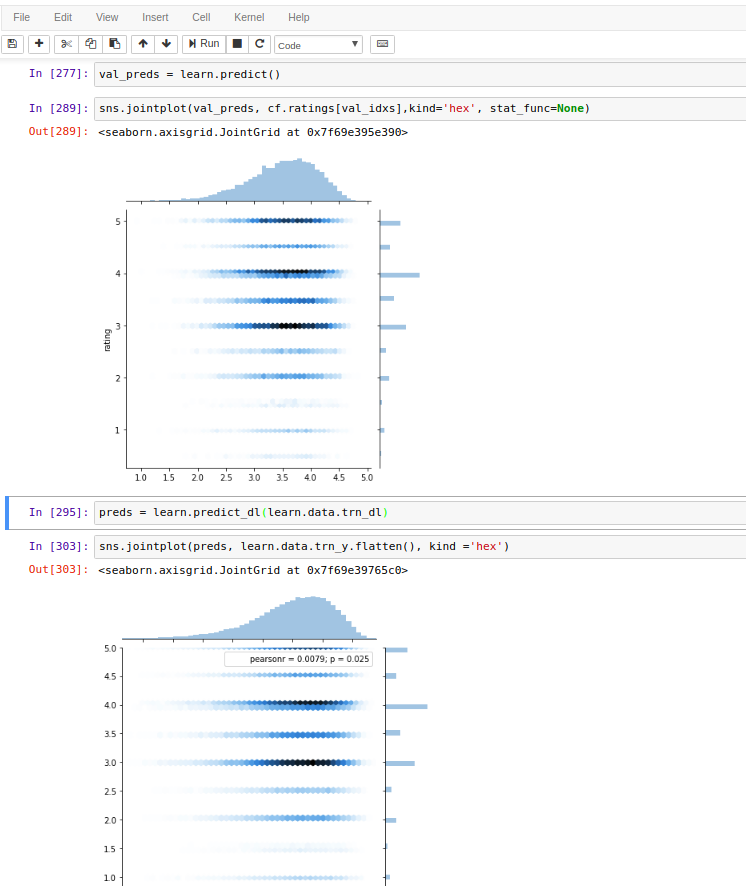
Validation set
fact = learn.data.val_y.reshape(-1)
preds = predict(learn.model, learn.data.val_dl)
Box plot of predictions:
Correlation is 0.57 (which is very high). Predictions are very wide, but, as Jeremy told, moving up when real ratings are moving up as well. So we learnt something.
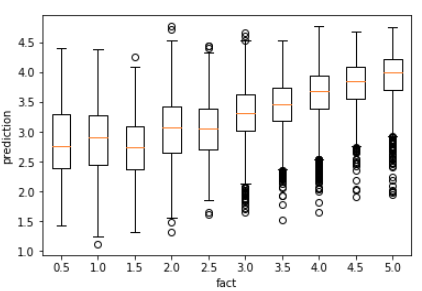
Train set
fact = learn.data.trn_y.reshape(-1)
preds = predict(learn.model, learn.data.trn_dl)
Box plot of predictions:
Correlation is 0.00058. Predictions for all ratings looks like have exactly the same distribution. Anybody has an idea why?
Real world case
Company X is running advertisement campaigns by buying traffic (user visits) from different sites (placements). The idea is quite simple: ad campaigns = userId, placements = movieId, go and build recommendation system. Instead of rankings I use some other number, called conversion rate = user bought product / users viewed an ad. Evident differences from movies rating example:
- % of non empty cells in matrix is 5 times lower - 0.3%
- target values is continuous (instead of 10 possible rating values)
- range of target values might be huge: from 0.0001 to 7
- 60% of values are zero (placement was useless for specific ad campaign)
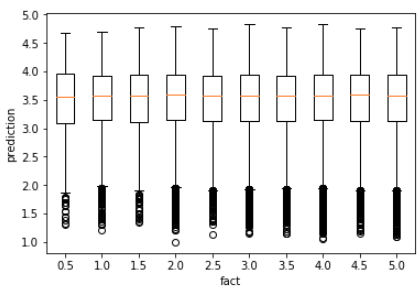
What I get:
- Some learning is happening
[ 0. 0.10338 0.09928] [ 1. 0.06246 0.05808] [ 2. 0.05271 0.05509] [ 3. 0.0477 0.04698] [ 4. 0.0454 0.04563] [ 5. 0.0439 0.04541] [ 6. 0.0423 0.04542]
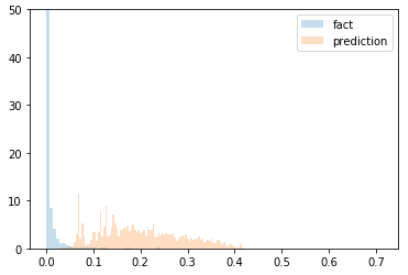
Hist of predictions and facts looks terrible, CF significantly overestimates real values (x 20-30 times) :
Correlation is 0.1. For train set - same case as with movie ratings: 0 correlation, no visible accuracy. Any hints are highly welcome.
UPDT:
- I substituted continuous values with binary (0 - placement was useless, 1 - placement was useful, I lost information how good was a placement for a campaign but thats ok in my case) - and this improved correlation to 0.42, AUC 0.74 (after some tuning got AUC 0.8), and make prediction accuracy visible and similar to movies rating:
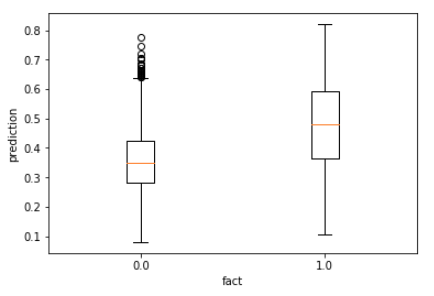
- Logistic regression gives the same accuracy for this dataset (AUC 0.8)
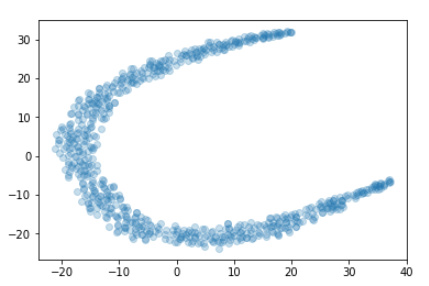
- TSNE of userId embeddings - no visible clusters, no structure.
- For those who are interested in getting deeppppper into CF - A Comparative Study of Collaborative Filtering Algorithms
- After some paper reading I realize embeddings start meaning something only if you have really dense matrix. In this case embeddings need to solve complex problem - to fit to multiple varying cross - ratings. If you have highly sparse matrix, say 1 rating for movie-user than CF is not better than any simple algorithm.