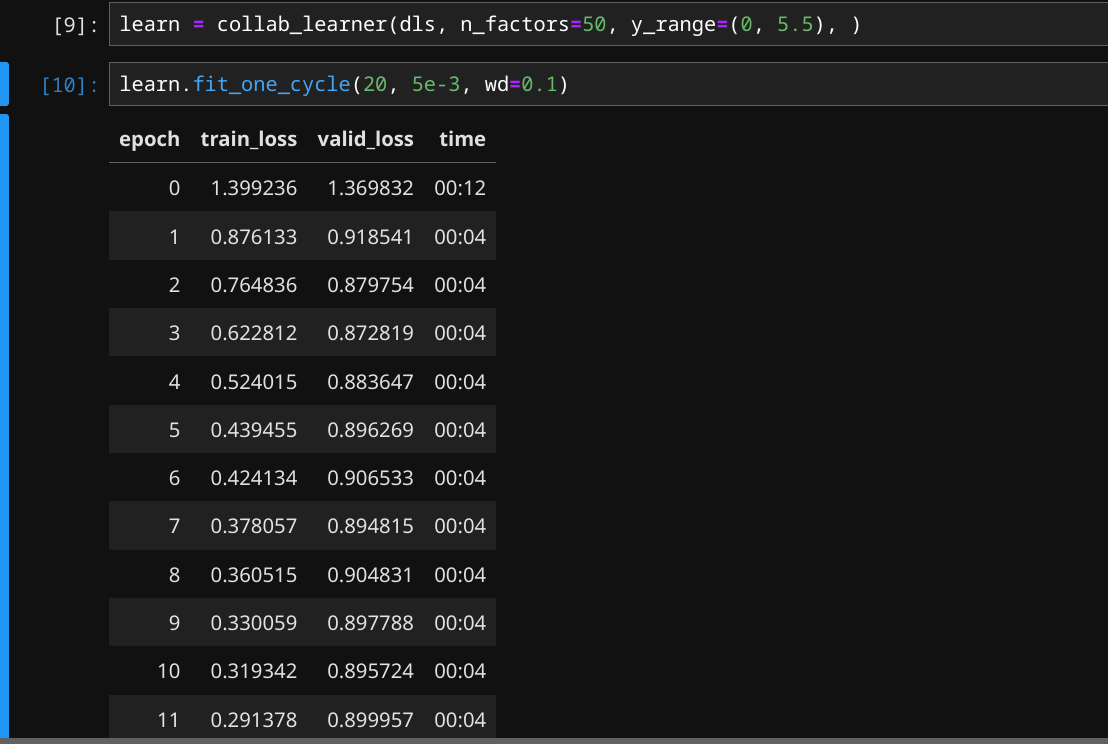
I’m on the chapter about collaborative filtering and was training the model from the notebook. But I am confused about how we know the model is doing well. When training we are shown train_loss and the valid loss.
Even though our train loss decreases with each epoch the valid loss barely decreases, plateaus, or slightly increases the more we train, So I don’t know if we were supposed to use that to tell if the model was doing well.
So my question is what metric are we using to tell if the collaborative filtering model is doing well?
In collaborative filtering, the key metrics to monitor the model’s performance are train_loss and valid_loss.
Train Loss: This indicates how well the model is fitting the training data. A decreasing train loss is generally a good sign, as it shows that the model is learning.
Validation Loss: This measures how well the model performs on unseen data. If the valid loss decreases alongside train loss, that typically indicates the model is learning effectively. However, if the valid loss plateaus or increases while train loss decreases, it may suggest overfitting, where the model learns the training data too well but fails to generalize to new data.
For a well-performing collaborative filtering model:
Aim for both train and valid losses to decrease over epochs.
Monitor the gap between train and valid losses; a large gap might indicate overfitting.
In your case, if the valid loss is not decreasing, you might consider:
Regularization: Adjust the weight decay (wd) parameter.
Learning Rate: Experiment with different learning rates.
Model Complexity: Simplifying or adding complexity to the model might help.
You can also look into metrics like Mean Absolute Error (MAE) or Root Mean Square Error (RMSE) if you’re interested in more interpretable performance indicators for collaborative filtering tasks.