@jeremy said during the class that the addition of meta-data doesn’t, in some situations, even matter or add any more value for collaborative filtering, above just trying to learn the latent variables through gradient descent and having them do all the heavy lifting when it comes to making predictions.
It occurred to me - this must ONLY be the case if the input matrix is not too sparse.It would seem that the model would only be able to learn good latent variables if the user / movie rating matrix was fairly dense, meaning, most users rate most movies. If most users do not rate most movies, then the data you are starting off with must be quite weak. Its hard to imagine the model learning good latent variables in this case. Is my intuition accurate?
Nope! The netflix prize dataset was extremely sparse, and it was true for that dataset.
I’m not following your intuition, so I’m not sure how to help explain… What is it about taking a dot-product between vectors that means the matrix has to be dense for it to work well?
I think it is true that you need plenty of observations - but it’s the quantity, not the density, that seems to matter. Well… also, each user needs to have watched a few movies, and each movie needs to be watched by a few people, otherwise there’s nothing to go on - but it could still be a very small percentage of all the movies and users.
Thanks for your response! And, I think its the scenario that I you describe that I was referring to, not the sparsity of the matrix per se. I.e., that each user needs to have at least a few ratings, and each movie needs at least a few ratings.
By sparse, I think I meant you might have on average, one response per movie, and one response per user.
I suppose its worth noting that, even if you had the movie metadata, it might not be any good because you wouldn’t know anything about the users anyway so you couldn’t learn good parameters for each user.
Forgive me for speculating randomly (and incorrectly!!)
Ah OK I think we’re saying the same thing then. If a user or movie has few ratings, you get poor results. This is called the “cold start problem” in collaborative filtering, and refers to the problem that new users and items can’t have useful recommendations. So this is a great place for metadata models.
Speaking of collaborative filtering (and I’m hijacking the thread here, sorry!), someone in class brought up a good point during lecture and I’m a bit curious as to the answer.
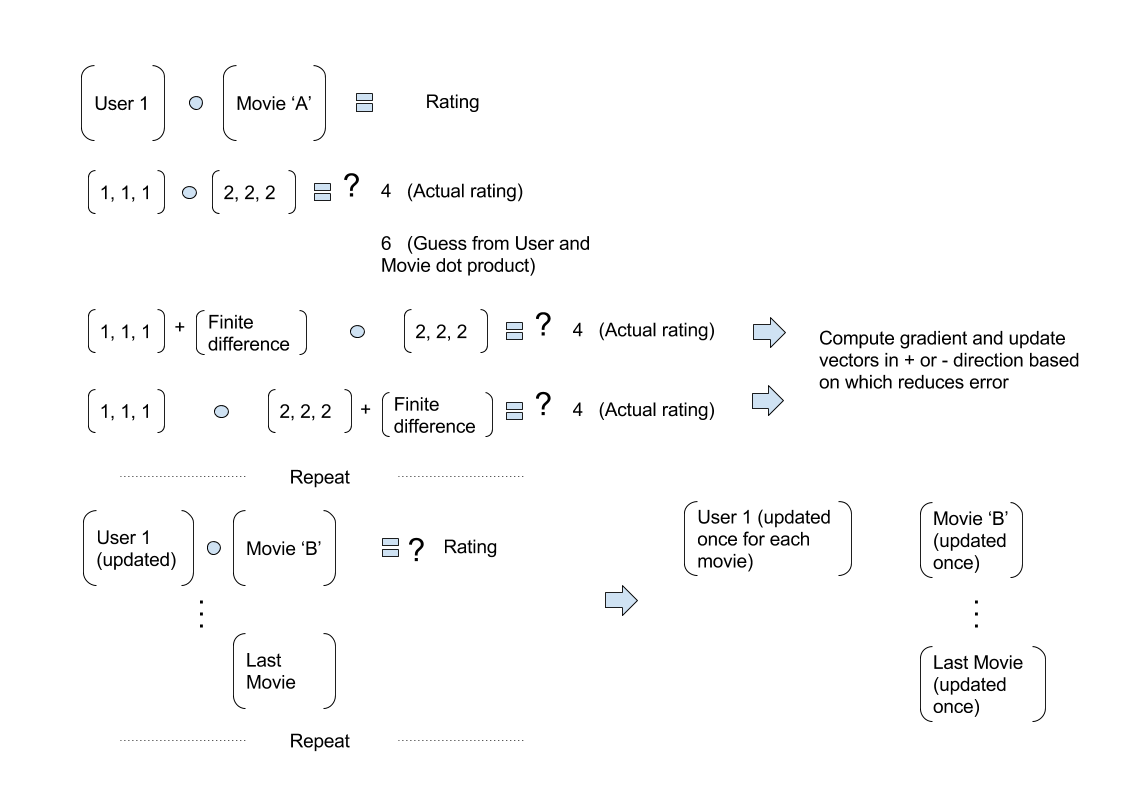
When we were looking at movie factors and user ratings, we seeded these matrices (movieid and userid) with random values, and let SGD optimize over it to minimize the loss. Sounds good!
But at first glance I get a bit of anxiety – since it seems like we are solving a system with more unknowns than solutions. The fundamental question is, “What two vectors, when dotted, will equal some known value?” But it seems like there could be multiple solutions.
Apologizing in advance for the poor analogy: In the same way that 2 * 1 = 2, and 1 * 2 = 2, how can we determine the values in both the unknown values in both the userid and movie matrices? Why would the gradients choose to assign, say, 2 * 1 over 1 * 2? Or, said in other words, why would a user’s attribute be a 2 and the movie’s be a 1, instead of the commutative case?
I feel like I’m not explaining this as well as I’d like. Someone from class asked the same question as well at this point in lecture. Maybe the audio from the question can help clarify too. Thanks!!
There’s no reason it would choose one over the other. They are equally good solutions. Which one gets selected would depend entirely on whether the random starting point was closer to one than the other.
There’s no reason that multiple equally-good points need confuse SGD. Indeed - why should it? As long as gradients point towards one of them at the point we randomly initialize to, we’ll find it!
I was under the impression that SGD is effective because of the existence of a global minimum on the error surface. How can there be multiple solutions yet a single global minimum?
Nope - that’s not true. Take a look at the graddesc spreadsheet to see exactly what sgd does, or the sgd-intro notebook. Each of them steps through each update without anything hidden. As you can see, there’s no assumptions about a global optimum built in to any step of the process.
It looks like sgd-intro.ipynb runs the update 20 times (hardcoded in) before stopping.
The graddesc spreadsheet stops after it “Repeats…lots of times. Eventually we end up with some decent weights.”
So I’m getting the feeling that it’s all about running the algo for a certain number of epochs.
But then again, Wikipedia says, “stochastic gradient descent converges almost surely to a global minimum when the objective function is convex.”
Is the idea to run SGD until you feel like it’s pretty much done (i.e., your scores stop improving)? Why not run until it converges (assuming you have the time to let it run)?
Wikipedia says “if the function is convex”. Our function is not convex. You never really know if it has converged. My strong advice is to try building many many models of many many datasets to get a strong intuition of how SGD behaves in the context of deep learning - there’s really no substitute for experience here!
Yes I definitely need to get up my experience level!
Meanwhile, as I once again reference my book learning, I know that SSE is a convex function. And that’s what we’ve used in the 2 examples (the jupyter notebook and the excel file). Shouldn’t that be enough?
SSE is the loss function - but remember that the function of the parameters is a long compound of matrix products (or convolutions) and non-linear activations… with SSE just the very last step of that!
(…and since it’s the parameters that we’re optimizing, it’s the relationship between them and the loss that we care about)
Wow…I didn’t realize that was going on. Thanks so much for clueing me in on this. Just last week our study group got in a raucous debate – “How are things convex when you differentiate a ReLu anyway??” and this just swept a lot of that up in one fell swoop.
One thing still scares me a bit. If there are what amounts multiple solutions when it comes to fitted weights, then I feel like the explainability/interpretability of the model just got blown out of the water. I know NNs are black boxes…but this feels like they are nailed shut wrapped in duct tape black boxes. You’d be making a huge mistake if you looked at the weights you fitted, say from the collab_filtering.xls, and tried to make a firm statement about, for example, a user’s bias. Are these weights good only for the sake of the model, and nothing else?
I see what you guys mean on that linked thread. The bit from Leo Breiman is really insightful. Great approach in general, it sounds like.
One more question and hopefully I can stop what dares to be me beating a dead horse: In the case of the collaborative filtering example, if the bias for userid #1 is fitted at 0.9, but could also be fitted equally well at 0.1, isn’t that an issue? This is the interpretability of the weights part that is nerve-wracking. Can we safely interpret weights at all…even a tiny bit?
Please don’t feel any pressure to stop asking questions - I think this is great!
You’re absolutely right - the biases definitely do have a particular meaning. And there’s no way to change the order of the biases and still get the same answer. So if you run the algorithm multiple times, you’ll see that the biases are much the same every time - try it and see!
So if there’s only one good way of setting some parameter(s), then SGD will have to figure that out in order to get a reasonable answer.
I am answering my own question after doing some thinking:
Biases are random like the parameters. They capture “how much a user loves all the movies?” and “how much a movie is liked by all the users?” and they will be evaluated during the optimization step.
They was a bit counter-intuitive to me because I used ALS for matrix factorization and I don’t think it has a notion of a bias. I’m guessing that it is closely related to the way we represent embeddings, or am I wrong ?