Hello,
We have been training a collaborative filtering model, EmbeddingDotBias, using fastai 2.5.3. We launched the training for 10 epochs, but it seems that it stopped after 5.
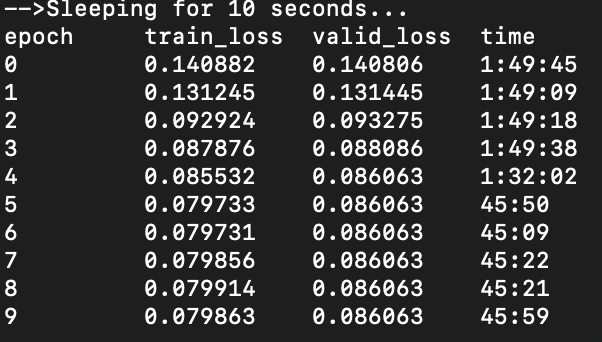
In the picture, you can find the losses and durations of the training.
What bothers us:
- after 5 epochs, embeddings are actually not moving at all (we checked manually in saved learners of each epoch)
- the epoch duration is way lower after 5, so we believe something is going run at the point. Because even if we reached a plateau, it should take the same time to run an epoch, no?
- the lr is at its highest value at epoch 5 (using fit_one_cycle), so it’s probably not a plateau issue
- the embeddings make sense after 5 epochs, so the model is converging decently for 5 epochs, we just want it to keep improving
A few info on the training:
- Our dataset is made of 600M pairs, ~1M5 items, ~5M users.
- Scores are 0 and 1 only. (ratio is 50-50, 0s attributed randomly)
- We do not use the sigmoid (range=None)
- We use 100 factors, bs=8K
- Otherwise, we use fastai’s default parameters
- lr = 1e-3, defined with lr_find
- we train on GPU
We tested:
- using the sigmoid, but it returns poor embeddings after training (which is what we aim for), most of the signal seems to be in the bias (very weird btw)
- using SGD, instead of Adam, it made us use a waaaay larger lr (~1e3) but behaved similarly
Does anyone have any idea to help our model finish his training? 
Just for my own education, what makes you believe it should keep improving? ie; that something is wrong?
Is it possible that this is the best that can be achieved?
I’ve had this question before, as to when to stop training, and I’m wondering as to why do you think this model could do better? (just the fact that the time it’s taking after 5 epoch’s is 50% of the time taken for the previous 5?)
What I find interesting is that the time for epoch 5+ is almost exactly half the time of the first 5 epochs. This is too uniform a problem. I wonder if you’re hitting a wall on your GPU in terms of memory limits etc?
Indeed, the first thing is the training time, I highly suspect something has been cut off there.
The other thing is that the loss remains exactly the same, and so do the inner embeddings. As we use gradient descent, I would expect the embeddings to change a tiny little bit between each epoch, even if we are very close to the optimal solution (which is never strictly reached).
Indeed the factor 2 is provocative. 
As you say, we are probably hitting a wall on the GPU during the 5th epoch. The first 4 epochs are very stable, the 5th was 15 minutes shorter (certainly because we hit the wall there), and the remaining 5 epochs are half the time.
I don’t know enough about GPU machinery to understand what could go wrong here. 
Not sure how (logistically) convenient it may be, but it might be worthwhile to try this experiment on a cloud instance to rule out your current setup as a possible factor.
Also, I’m not sure if it’s possible to reduce the data set size to 50% or 25% of the current size and see if the epochs go farther than 5?
Just a wild guess here that you may be hitting some kind of a limit or maybe even a bug that gets triggered after a certain amount of processing has occured?
Good luck!
1 Like
Thank you for your help @mike.moloch
Not sure how (logistically) convenient it may be, but it might be worthwhile to try this experiment on a cloud instance to rule out your current setup as a possible factor.
We are already running this on Linode but they only offer one kind of gpu.
Some plans offer 2+ gpus, but we never managed to train on more than 1 at a time with fastai. 
Also, I’m not sure if it’s possible to reduce the data set size to 50% or 25% of the current size and see if the epochs go farther than 5?
Indeed, this is an easy test we can run to better understand the origin of the problem. I’ll keep you posted in a few days.
Just a wild guess here that you may be hitting some kind of a limit or maybe even a bug that gets triggered after a certain amount of processing has occured?
Yup, this is our wild guess too, but we are limited by our understanding of GPUs, and interactions with fastai/pytorch.
1 Like