Hi all,
I’m trying to code up the Avagrad optimizer which looks to outperform SGD by adaptively scaling the variance…however, in their paper they have magically included a d reference…with no explanation what it is.
I’m wondering if anyone can clarify what they are referring to in the green box I’ve highlighted in the pseudo-code? Is d a known term that I simply haven’t seen and that’s why they include with no explanation? I searched the entire paper to find it with no results.
*Of course I am emailing the authors but hoping @sgugger or similar may be able to answer faster as I’m ready to test except for that missing item.
Hi @morgan - I hope so!
Both AvaGrad and SLS esp are more focused on trying to be adaptive and somewhat automated.
SLS is especially automated as it does a line search at every epoch and can actually run some steps (w/o gradient) to ‘preview’ the changes and adjust step size accordingly.
I’m waiting for SLS to update to support param groups and then will be able to do some broader testing with AvaGrad and SLS to provide some results and recommendations.
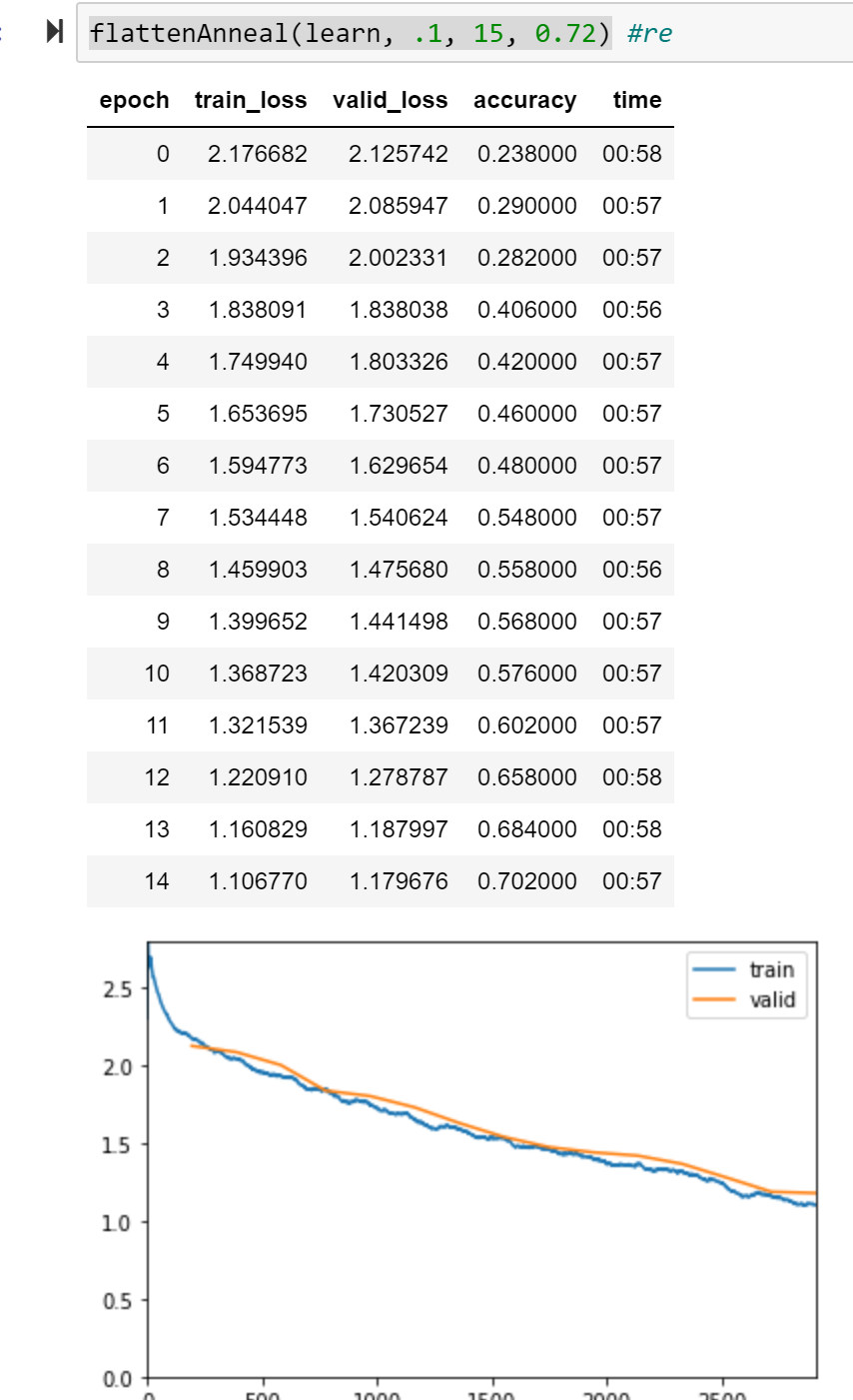
(Note - don’t use fit_one_cycle with AvaGrad, I can say that lol).

 It’s b/c Avagrad is auto-adaptive.
It’s b/c Avagrad is auto-adaptive.