How does a CNN deal with different spatial resolutions?
Terms
“Spatial resolution”: The ratio between pixel-to-pixel distance and the physical distance it represents
Elaboration
If I have a picture of two cats, one close to the camera and one far away from the camera, how does a cat-detecting CNN deal with this? In other words, how does a CNN deal with different spatial resolutions? Does it create different filters for each spatial resolution it saw during training? Does it use downsampling to somehow generalize beyond spatial resolution?
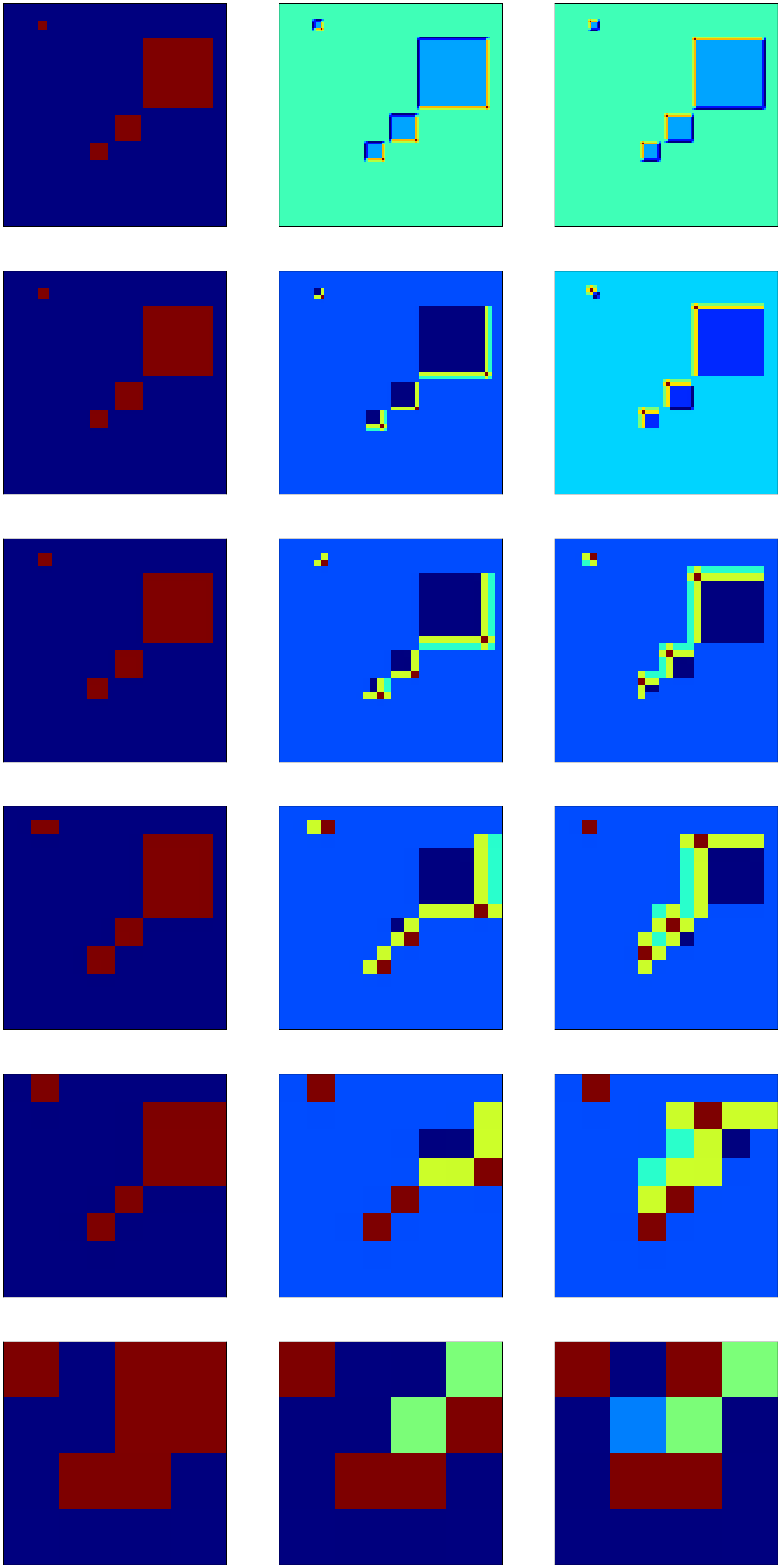
Here’s a picture of two cats, one close and one far (cats == gray squares).
Say a CNN found it useful to create a filter like the one above, maybe to detect corners of cats’ heads. It seems to work for cats at each spatial resolution, but is that a coincidence?
Here’s another filter applied to the same image:
Here the spatial resolution mattered with respect to the filter. The weirdness of this filter makes me doubt the relevance of this example, though, and so I’m left with confusion about the question.
Why I ask
I’m thinking of trying transfer learning from an ImageNet-trained model to a model used for satellite image analysis, where I don’t have much data. I thought the initial, low-level filters of the former model might help the latter, but, the spatial resolutions of satellite images and everyday images are very different.
Plan
Ask for help.
An experiment-oriented way: Just do it. See if transfer learning helps.
A theory-oriented way: Use Deep Visualization Toolbox to better understand how CNNs deal with different spatial resolutions (e.g. feed it pictures of cats at different spatial resolutions and see how the activations change).
I think the maxpooling operator allows a little bit of scale invariance. For example, if you have a 4x4 square and a 2x2 square and you have a corner detecting feature, a 2x2 max pool will produce the same output for both squares (if you get lucky with the alignment). It’s definitely not perfect scale invariance, but there’s some flexibility in there.
The network might also approximate difference of Gaussian type features before and after pooling layers to create an approximation of SIFT style key points.
I haven’t studied it myself yet, but this paper should give reasonable citations to previous attempts at scale invariant CNNs, as well as suggesting a particular approach: https://arxiv.org/abs/1602.01255
Generally scale invariance happens through:
Using zooming as a data augmentation approach
Having different sized objects naturally appear in various images
So the CNN learns to become scale invariant.
I’d suggest focusing on experiments (predictable, I know ). I’m pretty sure the early layers will be helpful, based on my own experience. I haven’t tried any scale invariant architectures, so would be interested to hear results if you try them. I’m not sure anyone has looked much into them for transfer learning, so you might be able to get some new results…
Just a very simple experiment with multiple size squares in an image, two convolutional filters (upper left (UL) and bottom right (BR) corner detectors), and then multiple max pooling steps.
You can see that all but the largest square end up with the same activation (active for UL and BR in the same location) at the later levels of pooling.
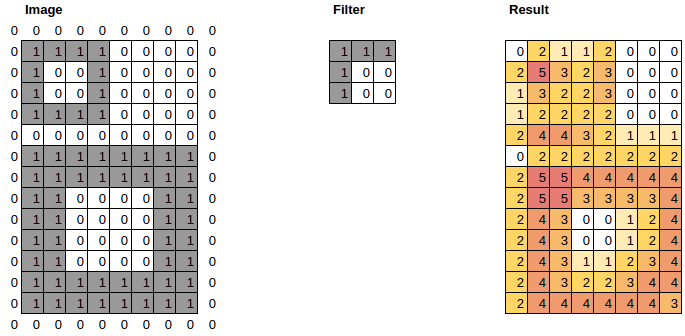
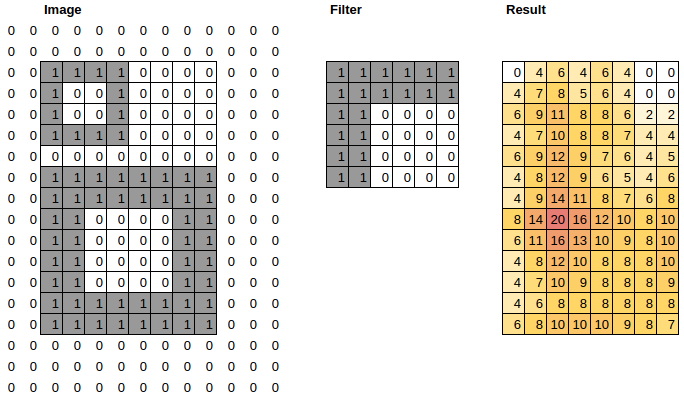
 ). I’m pretty sure the early layers will be helpful, based on my own experience. I haven’t tried any scale invariant architectures, so would be interested to hear results if you try them. I’m not sure anyone has looked much into them for transfer learning, so you might be able to get some new results…
). I’m pretty sure the early layers will be helpful, based on my own experience. I haven’t tried any scale invariant architectures, so would be interested to hear results if you try them. I’m not sure anyone has looked much into them for transfer learning, so you might be able to get some new results…