I’m trying to train a convolutional network with large amount of classes (up to 30 000 classes) with resnet34.
My dataset consist of one image per class (and a few extra images for validation).
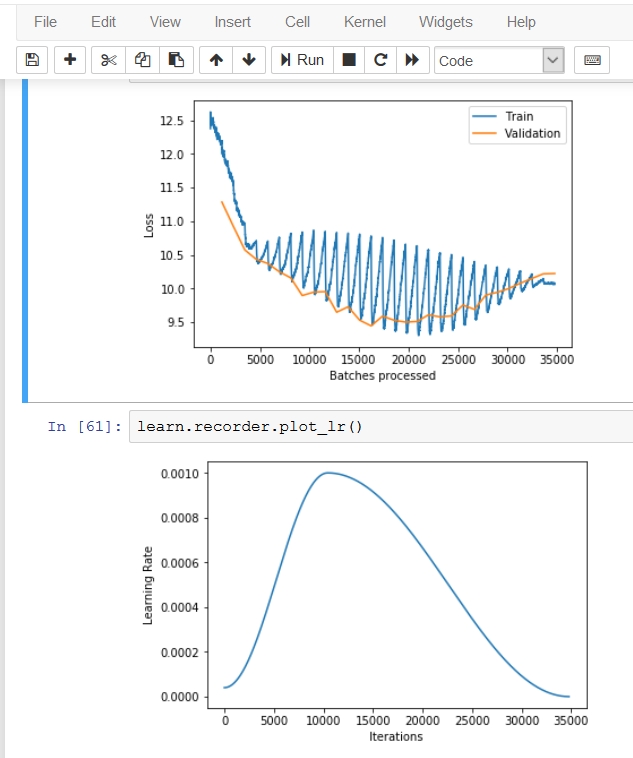
The learning goes quite well for about 200 classes, but I get strange graph from the recorder for larger sets. The train loss drops very fast at the start of the epoch and then it grows back. The result is a saw-tooth graph.
Woah thats a lot of classes! And not a lot of training data per class… Are you doing lots of augmentations to increase the number of training examples? Your loss looks very high even at the end of your training run, you might just need more training examples. Also if you scaled this chart to 0 - 13 on the Y axis your sawtooth effect would be less dramatic and might just resemble “normal” fluctuations in loss…
Sorry I don’t have a theory to explain the sawtooth effect, apart from noticing that it gets worse as the LR increases, maybe its the result of large jumps around the loss space without being able to find a good place to settle…
Yes, I do the augmentations - specifically rotation, resize and warp. And yes, the loss is quite high. The saw-tooth effect is present with the smaller amount of classes (2000), too, only not so strong. And yes, it gets worse with higher LR.
I don’t think it’s a normal fluctuation, as the individual teeth really match the epochs.
I’m looking into it, thanks a lot. Looks it could be a solution (although the comparsion to 40 000 vectors can take some time - I need to try).
However I got stuck in the last notebook - cannot create similarity dict, fails with:
in create_similarity_dict(model, dataloader)
29 dists = {}
30 for i, (whale, _) in enumerate(dataloader.items):
—> 31 dists[whale] = torch.pairwise_distance(descs[i], descs).cpu().numpy()
32
33 return dists
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
Finally found out the root cause of the " IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)". It happens when you use a dataloader with batch_size = 1 (which I did due to error in the notebook). Just for the case anyone else faces the same problem…
From my understanding since the number of samples per class in the training data is so less I think the model starts overfitting on the training data. It’s not able to generalize at all. Thus the validation loss starts shooting up.