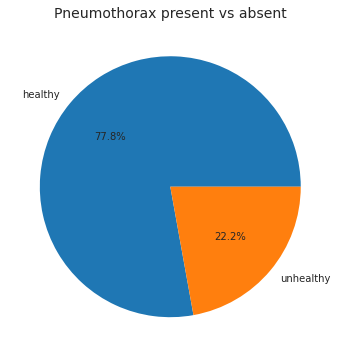
I know such distribution would need balancing in Classification tasks. Is this the same for Segmentation? Do I have to balance these classes or I can just train the model as is?
Is there a preferred way to handle the balancing? In classification, we have oversampling of the smaller class as the preferred method. Does it work too for segmentation?
The first thing you need to try without thinking is the approach of oversampling.
Oversampling > Undersampling.
You might miss out on crucial data points if you undersample data points from the majority.
Once that is done, use the model tag untagged data.
Keep in mind nothing helps a model more than “more data”
And using a loss function that deals with class imbalance helps, too. For example I successfully worked with FocalLossFlat(). Use search here and on Google
That’s what I thought too, I’ll try training it without fixing anything and then training it with the fixed suggested here and see what happens. After all, Deep Learning is all about the experiments.