Training a language model using language_model_learner(data_lm, AWD_LSTM, drop_mult=0.5) . I am getting the following as lr_find plot. How should I choose the lr?
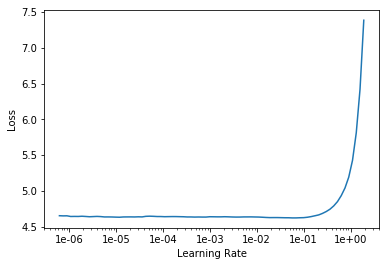
Training a language model using language_model_learner(data_lm, AWD_LSTM, drop_mult=0.5) . I am getting the following as lr_find plot. How should I choose the lr?
The Learning rate seems to be increasing exponentially after 1e-01 before which it is constant.
So anywhere between 1e-06 to 1e-01 should be good.
Yes , that is what I have been using , but accuracy of the lm does not seem be increasing post .40 . Also wanted to check how much accuracy is good enough for build a decent lm ? The lm will be used for text classification.
If I were choosing in your particular case, I’d probably go with something like 5e-2, which is high but farther away from where loss starts to increase. You don’t want to go too low or it will take forever to train the model.
I’d also suggest taking a look at the Automated Learning Rate Suggester post
A language model accuracy in the range of mid-30% to mid-40% is good. Remember what the LM is doing - it’s predicting the next word in a sequence. That it is able to do so at 40% accuracy is quite impressive (to me, at least) give how diverse language is.
Could you share the exact result of the model?
Generally there is no one point where model is good enough, it also depends on what data you had etc.
By result do you mean the result of training output ?
Yes, unless you are sure you are not overfitting or underfitting your data. As @Tchotchke mentioned 40% accuracy is not bad at all, but it is still possible that you are underfitting/overfitting and the results can be improved.
I would say that for an LM somewhere between to .35 to .4 can already be considered pretty good.