I started off modifying the dataframe so it’s just the index and whether the xray contains consolidation (fluid in the lungs). And then removed the last 7000 rows from the df to use as my test set.
I ended up with around 30000 images that had consolidation and 80000 that didn’t have. (72% without)
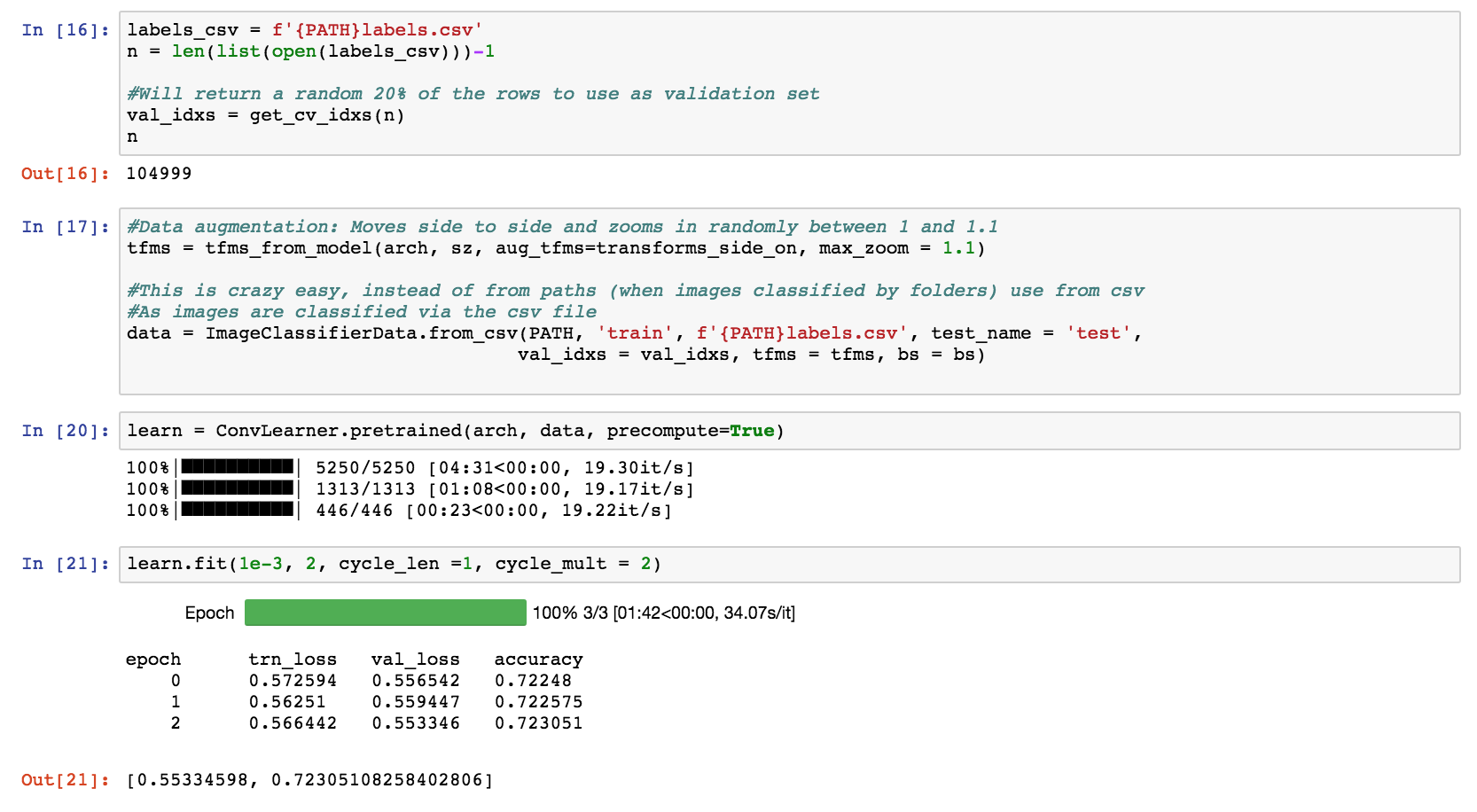
When I run learn.fit it’s giving me an accuracy of 0.72, essentially exactly the accuracy you’d get if you predicted every image as not having consolidation.
From searching the forum I’ve tried:
making sure training data is randomized with shuffle = True
reducing the learning rate
unfreezing
having a 50/50 split between consolidation and no consolidation (ended up with a 0.5 accuracy)
I hope I’ve explained that sufficiently, my understanding of what I’m doing is somewhat tenuous at the moment!
Can anyone help me understand what I’m doing wrong?
Thanks!
This is expected when there is 90+% in one class but unexpected here. I don’t think you’re doing anything wrong but you can try 2 things
Try to get the roc_auc_score or log loss. You can also predict the probability of consolidation using the model you have trained; use pandas qcut to bin the probability into 10 equal size bins and check the distribution of consolidation vs no-consolidation in the bins. This should give a better idea of model performance than accuracy.
Change the target metric from accuracy to either roc_auc or log_loss to measure learning during training.
I have no experience with medical images but does 64 seem like a small size to train the model?
I think the first thing to be said here is that you’re talking about images that are very different from ImageNet.
Not only are the pictures 64x64 (assumption from what you set the size to), but they are of something that is not in ImageNet.
The network you’re using is being pretrained on pictures of things people take pictures of in everyday life (dogs, cats, people) not medical imaging.
I would not expect it to perform well by any means in the first few epochs, without at least unfreezing and retraining some previous layers. But hey, maybe I’m way off base here. Would love to know other people’s thoughts.
Suggestions:
Make sure to use lr_find(), plot the graph, choose the place just before it improves the best.
Plot your pictures. Look at the ones it’s categorizing correctly and incorrectly.
Thanks!
I originally had images scaled to 224, and only dropped the size to speed things up while I was figuring out what was going wrong.
My main hope that it should work is that a paper on this data set (https://stanfordmlgroup.github.io/projects/chexnet/) claimed expert level pneumonia detection and also used ImageNet. They also downscaled to 224x224 so I assume that resolution would be adequate.
I will have a go with your suggestions, thanks so much for your help!