I checked also others topic from previous years, but I am not sure if it would be appropriate to share the code of the fastbook with them at the moment directly in the forum, I saw several useful posts.
Let me know if you have the same issue
Thank @jeremy, yes it is such an amazing book and course, I am too excited.
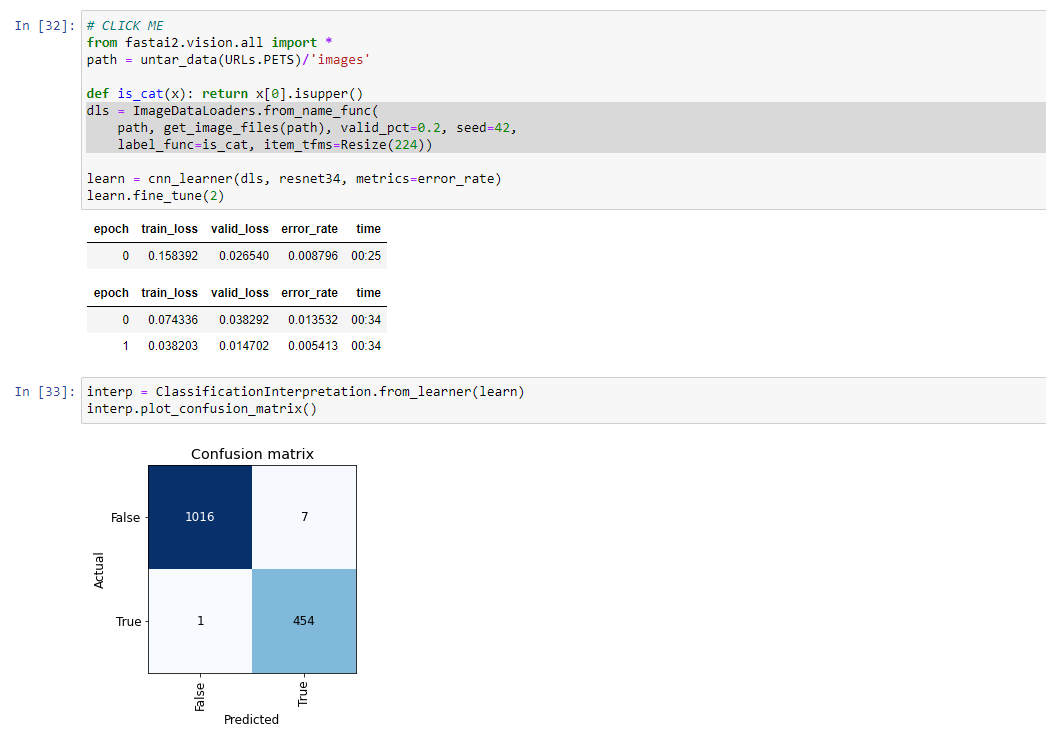
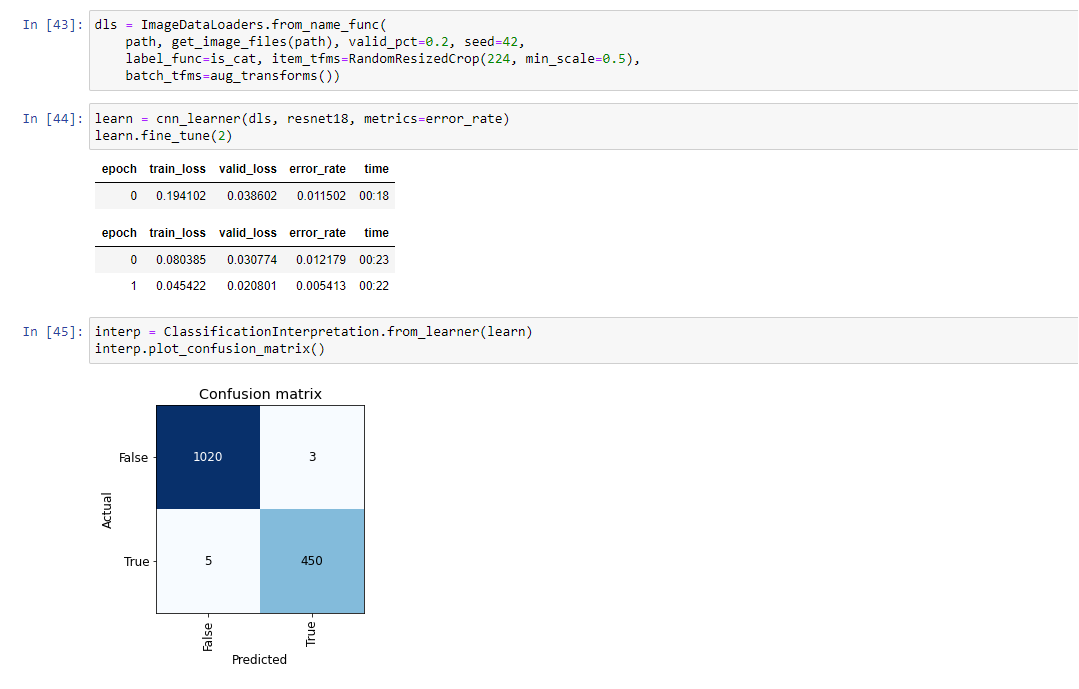
I was playing with Data Augmentation with Cat / Dog in the Chapter One.
Not sure what I am doing wrong. Is the operation too simple for our NN that it refuses to work?!
Besides Jeremy teaching about data augmentation, there are a number of papers that discuss the idea and why it works. However here is a paper discussing it: https://arxiv.org/pdf/1809.02492
A general understanding of why though can be summed up like this:
Our dataset will realistically always be limited. There is a limited number of samples, and these samples are built and shown in a particular fashion. But in the real world it won’t look this way, there are images that we will see that was never seen in our training data. How do we deal with this? NN’s are great at generalizing, but data augmentation can take us a step further. By augmenting our data, we provide the network a larger corpus of data to train on, as an image that’s rotated 45 degrees is quite different from it’s regular image, and in the case of RandomCrop, the particular cropped region could make certain features larger. The concept is further explored in Chapter 5 as well (See the “presizing” section)