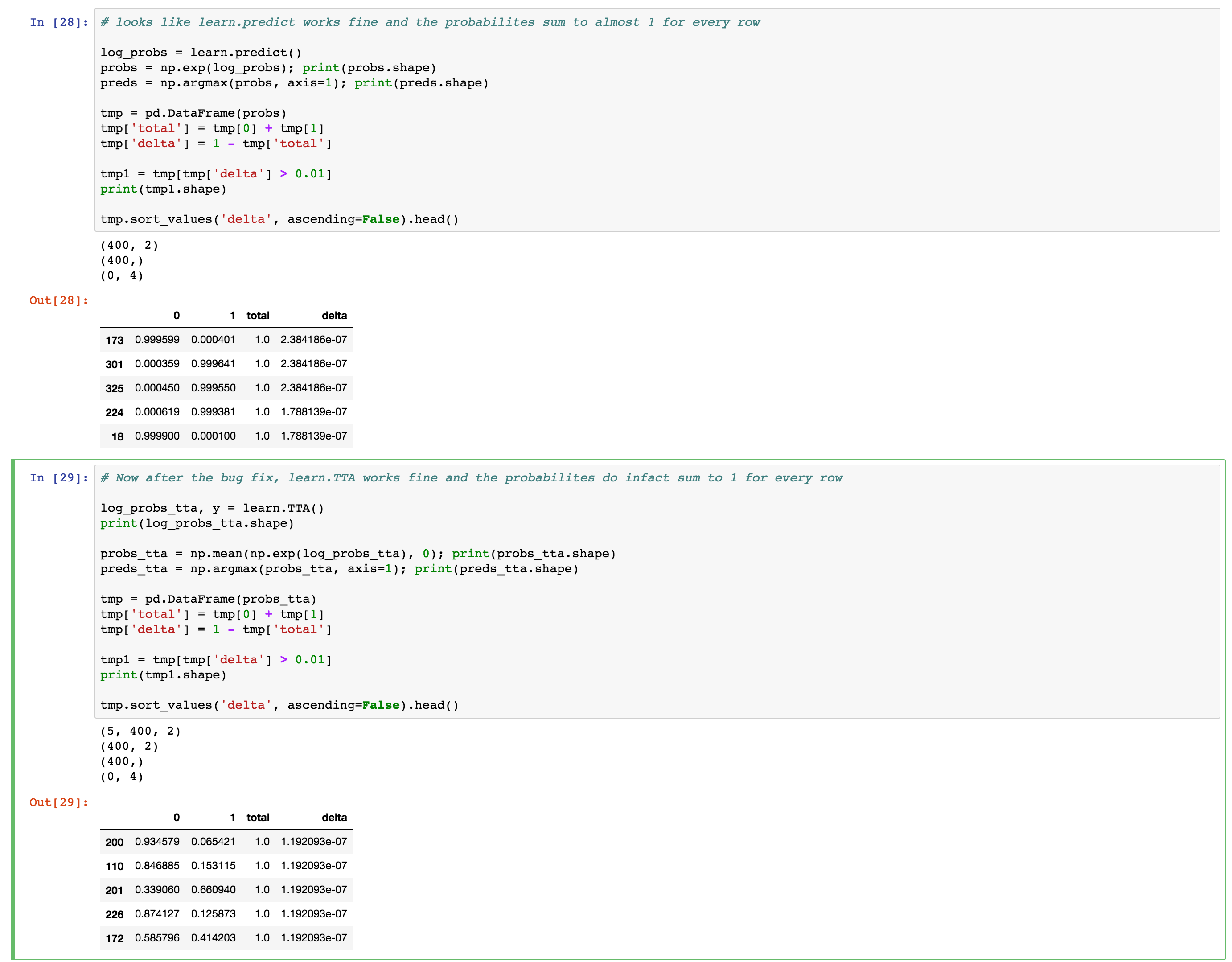
Thanks to a smart observation by @abi, I realized that TTA() is averaging the log of the softmax layer, rather than the probabilities. This isn’t ideal. So I’ve changed it to return the actual individual TTA predictions, which you then average yourself. See the updated lesson1.ipynb for an example.
(I didn’t do the np.exp and mean inside TTA, since not all models need exp).
About the specific transforms applied by TTA, I understand it uses tfms we set when learning, so… that also means that if we don’t define tfms (cause we are not using image augmentation when training) TTA will not be applying any transformation at “test time”? Or TTA has some defaults that applies independently of or “train time” augmentation?
This question isn’t specifically related to the change with how TTA() works but it is a question about loss/acc from TTA().
I’m in a situation where my TTA() loss/acc are looking MUCH better than my val loss/acc during training. Although TTA() results do look inline with training loss/acc.
Below are the results I am seeing for reference. My guess is that it could be because I am using heavy training augmentation (aug_tfms=transforms_top_down) so maybe the model isn’t able to predict well on the val set which obviously doesn’t have any aug_tfms during training yet it does perform well on the test set since with TTA we are also doing aug_tfms? I also checked the predictions and they all look pretty good…
Train loss 0.01297
Val loss 0.11317
Val acc 0.9576
TTA loss 0.019
TTA acc 0.992
Its for an ongoing Kaggle comp (with very strict rules) so I can’t go into much more detail than that - sorry! As for the transforms, I am just using the defaults from transforms_top_down that is included with fastai.
Just generally speaking though, do you think it sounds logical that the augs could be so heavy on training that they would throw off validation loss (no augs) and yet do well on TTA since augs are back?
Also while its quite straight forward usually with dogs/cats vs satellite imagery which type of augs to use, but I am sorta in a “hybrid” situation where its a tough call whether or not to go with side_on or top_down Its hard to explain but basically imagine that there is some “thing” on top of another “thing” and the thing on top could be varying a lot in shape/size yet the thing below it is very consistent in its position yet could still vary somewhat in shape/size.
Anyway I appreciate any feedback you might have given the extremely vague details I could provide!