Hi dear fellows !
I am wondering how to change the batch size during training ? More precisely, on dogs / cats data, how to set large BS for last layer training, and reduce it when training the whole model ?
Thank you !
D.
EDIT : thanks to @sermakarevich, there is a methodology to change the batch size during training and this is useful. So, don’t loose time to read my message below 
Hello @DomMIas,
let’s go through the code in order to answer your question :
-
The value of the batch size is set by default to 64 in the ImageClassifierData.from_paths method (
bs=64). -
Of course, you can change it when you setup your data with the code :
bs=... #the value you want
data = ImageClassifierData.from_paths(PATH, bs=bs, tfms=tfms_from_model(arch, sz)) -
Then, your model will be trained by using
data(ie, by using your batch size) :
learn = ConvLearner.pretrained(arch, data, precompute=True) -
Therefore, if you want to change your batch size during training you must rerun the code above (
data = ...andlearn = ...).
BUT : I guess that each time you run the ConvLearner.pretrained method, you create a new model learn. So, in my understanding, the answer to your question is : no, you can not change the batch size during training.
PS : even if we could change the batch size during the training, the question would be : why ? The batch size value relates to the GPU calculation capabilities : the more your model has weights, the lower is the value of you batch size to avoid the crash of your GPU. Then, once you have a batch size that fits both your GPU calculation possibilities and the number of weights of your model, it is safer not to change it I think.
1 Like
ImageClassifierData has bs obejct from ImageData. You can change it as easy as data.bs = 16 and update learner with learner.set_data(data)
Because you might do unfreeze which increases GPU load.
4 Likes
@DomMIas, each image if your batch size is 1, 2 if it is size 2, , or n number of images if size n, the batch size has to “go through” all the layers. You can not begin with, say 32 images, begin calculating activations of first layers and then say, ‘ey, I want 64 images more’. 
The way I see it a batch is, a “calculation unit”, I dont think it’s something you can modifiy “on the fly”, neither know what benefit you intend to get from varying it…
As I understand the BS, it is the number of images being loaded into the GPU. This is limited by the images size of course, but also by all the computations to update weight that take some memory on the GPU. While training only the last layer, only few weight are updated, so there is more memory free for data (for exemple, on dogs/cats, with bs=28, about 800 Mo are used on AWS p2). When all layer are unfrezzed, all weight have to be computed, and the same bs=28 lead to 10 Go of GPU memory used. Increasing bs when memory is under used will probably lead to speedup training.
More over, it is possible to do with keras. ^^
Hello @sermakarevich,
data.bs=xxx works but not learn.set_data(data) in my jupyter notebook.
When I run learn.fit(lr, number_epochs) after the 2 previous codes, my batch size is still the same.
Could you check on your side ? Thank you.
I like you answer (if we unfreeze the first layers, we’ve got more computation to do, and then, it would be a good idea to decrease the batch size for the next epochs if we get GPU computation problems).
However (cf. my question above), is it possible to change the batch size through the fastai library without creating a new model ?
1 Like
Frankly, there is not much I can check on my side as on my side this works. Can you publish your notebook and error you get?
@sermakarevich, attached a foto of my screen. I should get 720 batches (with bs=32), not 360.
What I did wrong ? Thanks.
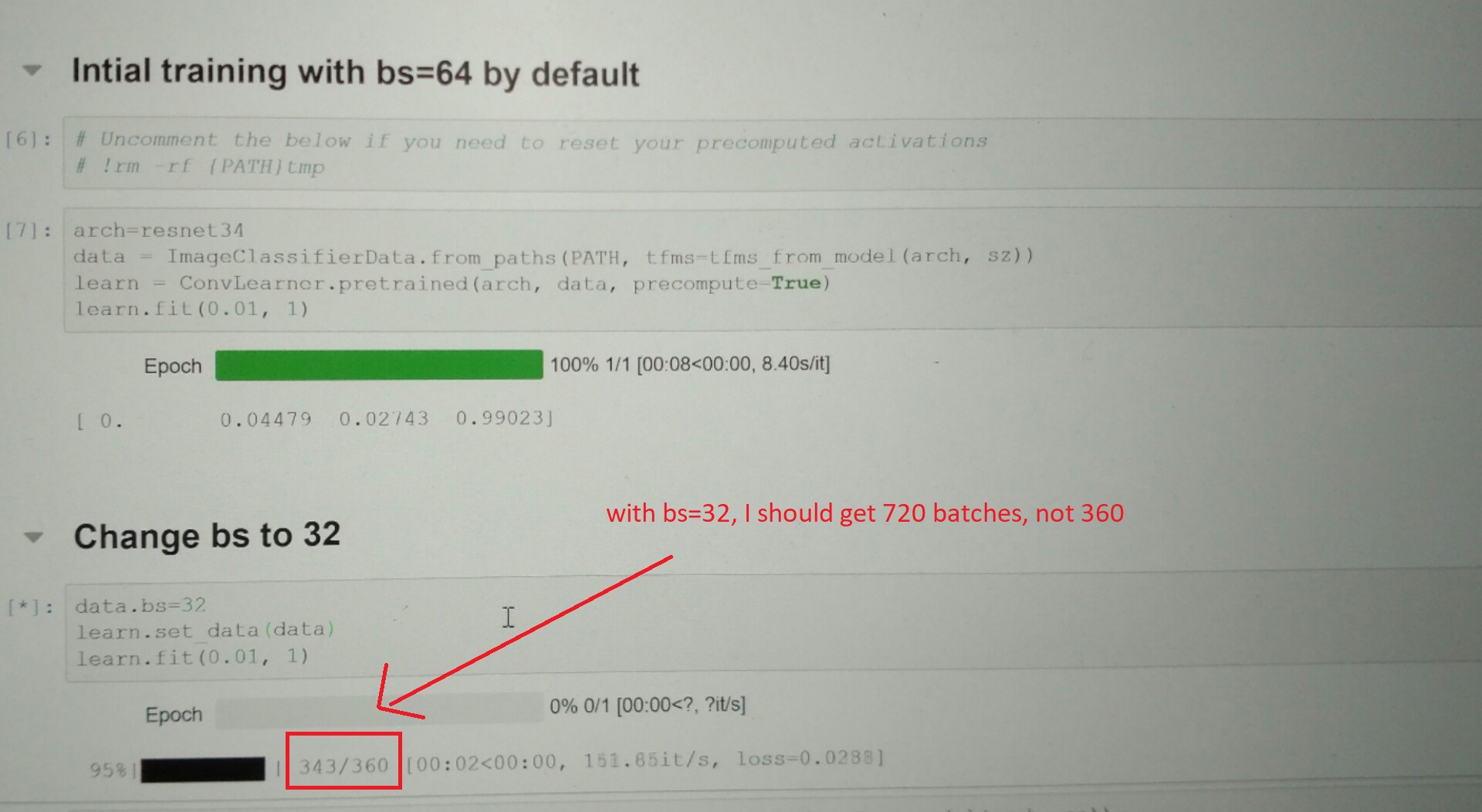
Yes, sorry, my bad, two things we need to change (not sure why :)):
- you need to regenerate your data object once again with new bs = 32
- in Learner
def data(self): return self.fc_data if self.precompute else self.data_. As you can see precompute needs to be False otherwise model uses fc_data pre-calculated object. So you need to do:
learn.precompute = False
learn.set_data(data)
8 Likes
Many thanks @sermakarevich !
Thanks to you, we have now a methodology to change the batch size during training through the following steps :
data = ImageClassifierData_from_paths(PATH, bs=new_bs, tfms=tfms_from_model(arch,sz))
learn.precompute = False
learn.set_data(data)
PS : this methodology works as well in the Dog Breed Identification challenge to pass the test set to the learn model for making predictions AFTER training. Cf Dog Breed Identification challenge
1 Like
Okay, this is why just changing data.bs does not work:
- ImageClassifierData returns ImageData cls with lots of stuff
cls(path, datasets, bs, num_workers, classes=trn[2]) - And ImageData class at init calls its method
get_dlwhich takes bs as input:
def get_dl(self, ds, shuffle): if ds is None: return None return ModelDataLoader.create_dl(ds, batch_size=self.bs, shuffle=shuffle, num_workers=self.num_workers, pin_memory=False)
Even though we changed bs in ImageData class, this does not affect bs in ModelDataLoader
1 Like
Ok, now I got what you want, and why. Dont know if its possible with this library. 
It is also possible to update data object in learner even with precompute = True. All you need is to reproduce save_fc1 method outside the class:
learn.set_data(new_data)
learn.get_activations()
act, val_act, test_act = learn.activations
m=learn.models.top_model
if len(learn.activations[0])==0:
predict_to_bcolz(m, learn.data_.fix_dl, act)
if len(learn.activations[1])==0:
predict_to_bcolz(m, learn.data_.val_dl, val_act)
if len(learn.activations[2])==0:
if learn.data_.test_dl: predict_to_bcolz(m, learn_.data.test_dl, test_act)
learn.fc_data = ImageClassifierData.from_arrays(learn.data_.path,
(act, learn.data_.trn_y), (val_act, learn.data_.val_y), learn.data_.bs, classes=learn.data_.classes,
test = test_act if learn.data_.test_dl else None, num_workers=8)
This code precomputes fc_data object with new data set.
Thank you very much for your answers. But I just realized that bigger BS means also longer loading time into the GPU… increasing to much the BS lead to increasing the overall epoch time ! 
Remember bigger batch size ===> bigger learning rate
I started controlling GPU memory load with watch -n 1 nvidia-smi with the goal to define bs as high as possible. bs highly depends on architecture you are using and precompute/unfreeze settings. Keeping your GPU load high ensure slightly quicker training.
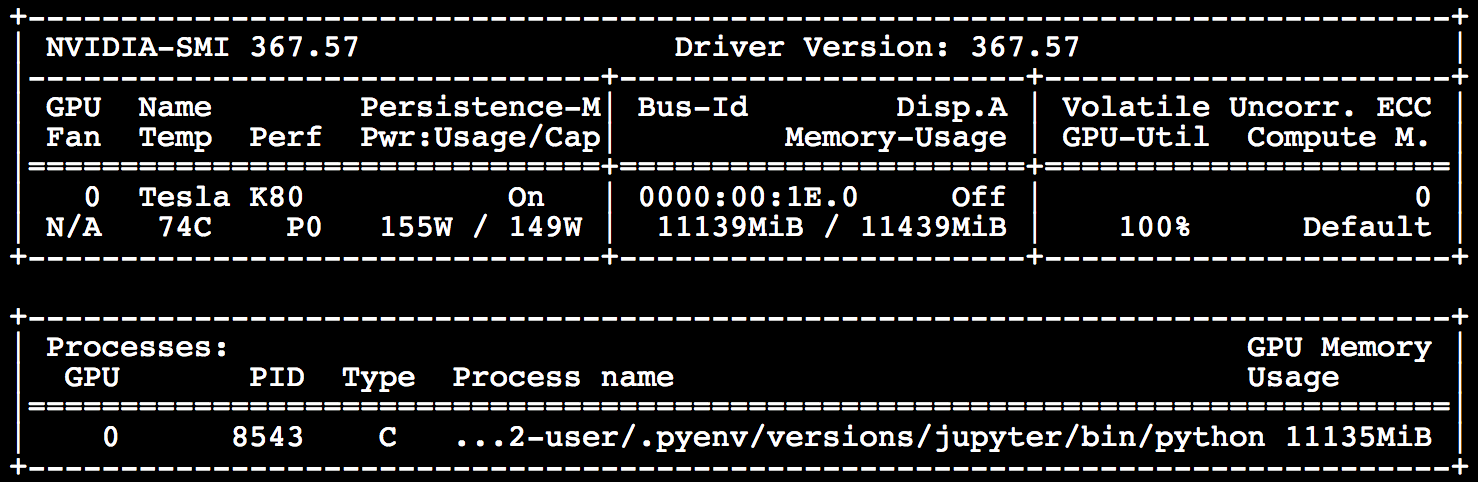
4 Likes
you could also try nvidia-smi dmon. (more info in the manual pages)
2 Likes
@suvash Now I am sure this is correct, but still I have not dig into the difference: nvidia-smi dmon mem and nvidia-smi Memory-Usage show significantly different metrics. Cuda crashes when there is no memory left according to nvidia-smi Memory-Usage metric while dmon shows utilisation is 60% only.
Interesting. Haven’t looked into the differences properly yet. Thanks for mentioning this.
I’d be interested to hear about why this difference too - I’ve noticed it before, but haven’t looked into it…