Ok I tried a lot to figure this out by myself, but I cannot seem to do so. I am trying the Diabetic Retinopathy Dataset which is a highly imbalanced dataset of 1000 retinal images for detecting various grades of diabetic retinopathy.
I did a 80%/20% training/validation split of the dataset, and oversampled the training set. I trained a ResNet50 on a batch size of 16 and image size of 224x224 and used progressive resizing. I am received mediocre results:
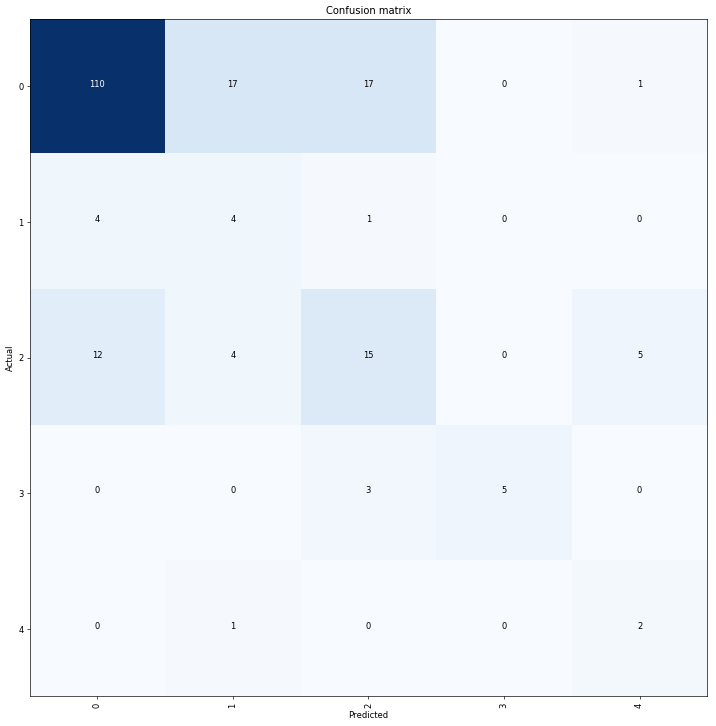
How can I improve the model?