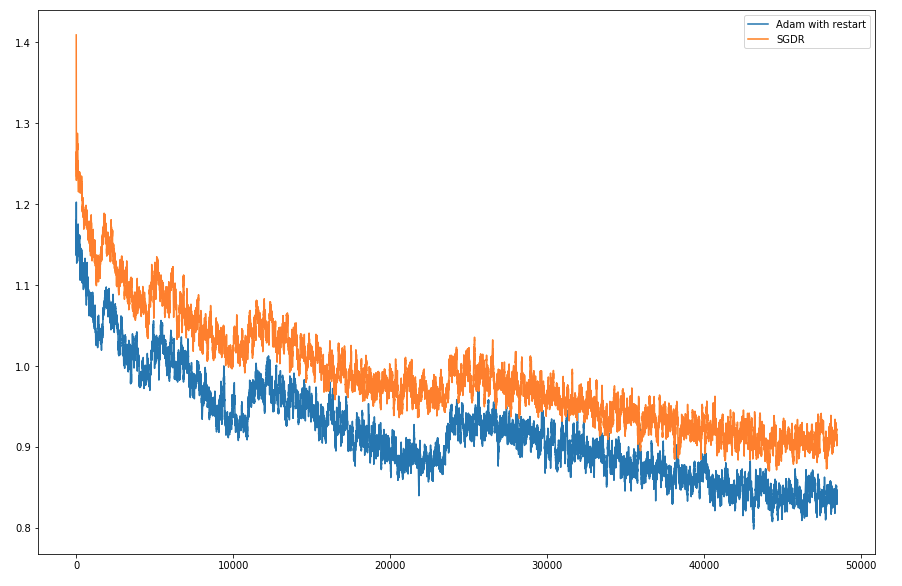
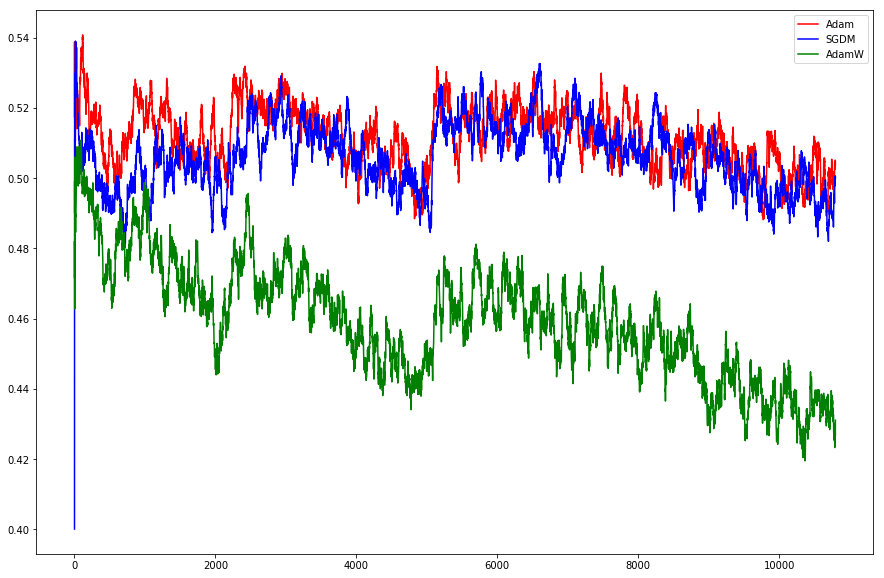
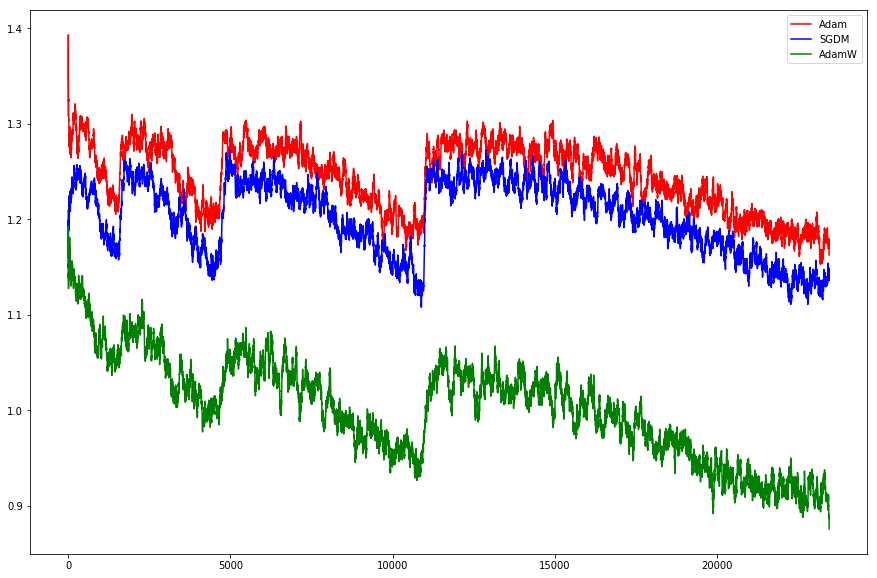
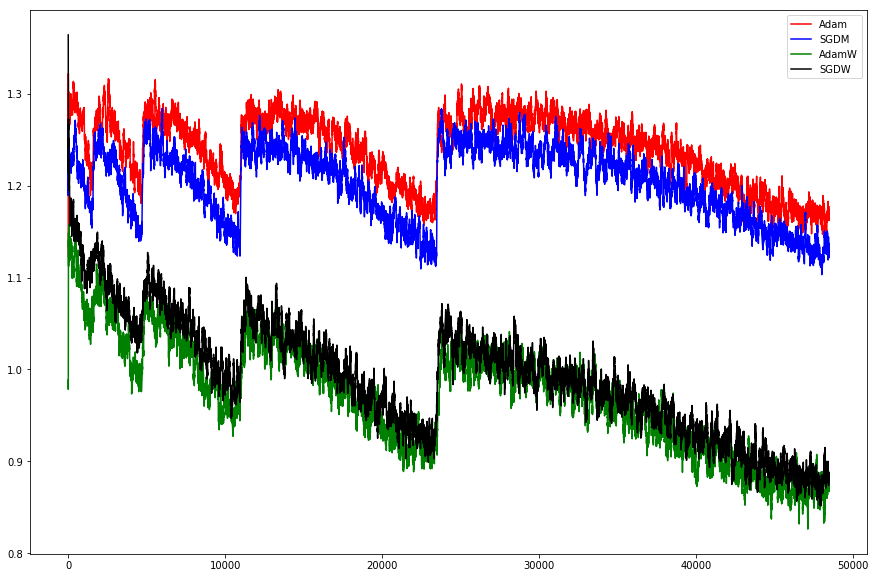
This paper shows how to make Adam much more reliable and accurate: http://arxiv.org/abs/1711.05101
It includes a link to an implementation in Lua Torch. Would anyone like to take up the challenge to port it to Pytorch? Here are the steps I think:
- Diff the original Lua Torch repo they forked from with their new version, to see exactly what they changed
- Make a similar change to Pytorch, and try to incorporate into fastai lib
- Test on same CIFAR10 dataset and training method as the paper, and replicate their result
- Profit!
If you have a try, keep us posted here!