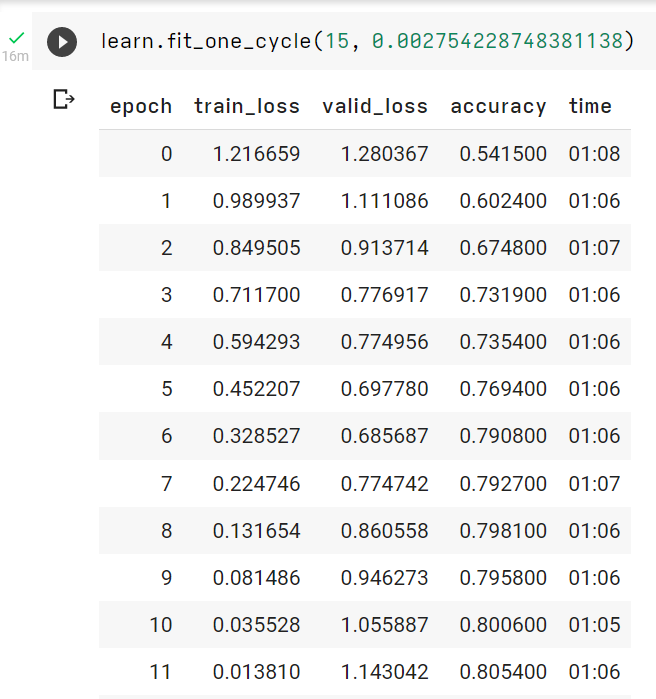
I have trained a Resnet-18 model on cifar-10 dataset for 15 epochs but i am unable to decide it is overfitting or underfitting. As training loss is continuously decreasing and val loss is increasing it clearly qualifies for overfitting but val accuracy is increasing and i cant understand that phenomena. Any help regarding this will be appreciated.
Hi @Mayanand1,
Ch. 5 of the FastBook talks about this phenomenon a little:
Selecting the Number of Epochs
… (2nd paragraph of this section in ch. 5 of FastBook) …
On the other hand, you may well see that the metrics you have chosen are really getting worse at the end of training. Remember, it’s not just that we’re looking for the validation loss to get worse, but the actual metrics. Your validation loss will first get worse during training because the model gets overconfident, and only later will get worse because it is incorrectly memorizing the data. We only care in practice about the latter issue. Remember, our loss function is just something that we use to allow our optimizer to have something it can differentiate and optimize; it’s not actually the thing we care about in practice.
Here’s how I understand: Early on in training, the model focuses on improving its predictions on examples it gets really wrong. But later in training, the model is getting most predictions correct, so it turns its attention to maximizing its confidence (ie. rather than predict the target class with 60% probability, it tries to predict it with 100% probability). In this way, the model becomes overconfident.
The reason validation loss starts to increase while validation accuracy still increases has to do with the difference between cross-entropy loss and accuracy. Cross-Entropy loss depends on how confident the model’s predictions are (ie. predicting the correct class with probability 100% produces less loss than predicting it with probability 60%). But on the other hand, accuracy doesn’t care about how confident the model is, it only cares about the class with the highest probability.
Now consider what happens when the model gets a prediction wrong. Since its overconfident, it will get the prediction really wrong (ie. maybe it predicts the correct class with probability 0.1%). This will cause a huge loss, but will affect the accuracy in the same way as if the model was slightly wrong.
Here’s a summary of what I’m trying to say:
- Model becomes overconfident → predicts 1 class with high confidence, others with low confidence.
- For example, predictions might look like
[0.01, 0.99, 0.00](really high confidence on class 2)
- For example, predictions might look like
- Thus when the model gets a prediction wrong, it gets it really wrong (imagine actual class is class 3)
- When the model gets a prediction really wrong:
- Cross-Entropy Loss will be huge
- Accuracy will be same as if the model was only slightly wrong → still is just 1 example incorrect
I am still trying to sort out my thoughts on this so my explanation is a bit muddled, but hopefully it helps a little bit.
2 Likes
Thanks @GoofyMango for such a nice and elaborative explanation, it really helped me lot understanding overconfidence in models.
1 Like