Hi there, great folks! I have a few troubles understanding basic collab example.
Here’s the code I wrote to get better understanding of what’s happening:
ratings = [
[1, 1, 5],
[1, 2, 4],
[1, 3, 1],
[2, 1, 5],
[3, 3, 4],
[4, 2, 1],
[5, 1, 5],
]
ratings = pandas.core.frame.DataFrame(ratings)
dls = fcollab.CollabDataLoaders.from_df(ratings, bs=6)
print(len(dls.classes[0])) # n users
print(len(dls.classes[1])) # n movies
learn = fastai.collab.collab_learner(dls, n_factors=5, y_range=(0, 5.5))
learn.fit_one_cycle(5, 5e-3, wd=0.1)
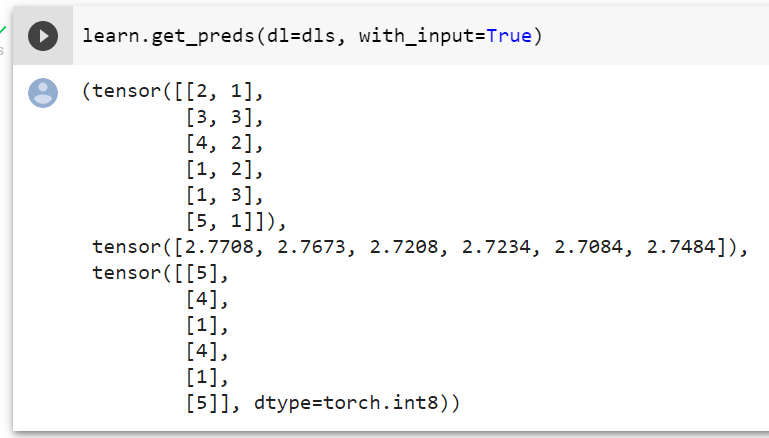
- Why do I get 7 users (and sometimes 8 lol) and 4 items, whereas I have only 3 items? I.e.
len(dls.classes[1]))returns 4 (there’s one #na# item, as I can see). - How do I get final recommendations for user 5? I.e. I want to get all the potential ratings, for every movie. Should I do that:
user_w = learn.weight([5])
for i in range(1, 3):
movie_w = learn.weight([i], is_item=True)
print((user_w * movie_w).sum())
Based on what I’ve learned, it should be something like the code above. But that doesn’t work, of course. Even indexing is wrong (because we have 4 movies, not 3, for some reason)

 , am I right?)
, am I right?)