I am writing this post because I am struggling in interpreting the results obtained after having used the learning rate finder.
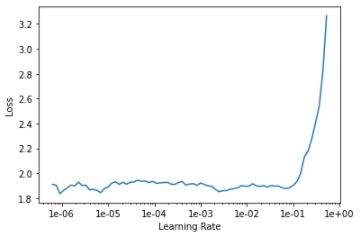
I am applying a transfer-learning algorithm using a pre-trained DenseNet169. I therefore initialized the learner and used the lr_find() method to find the best learning rate to train the last layer group of the model. During this phase, I should observe a plot LearningRate vs Loss similar to the one shown in the book or during the lectures (Please see the figure below)
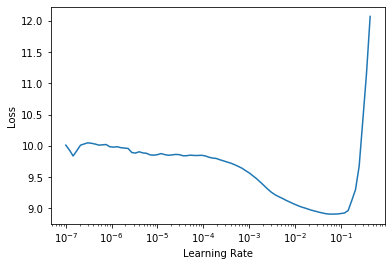
What, instead, I am obtaining is something this the following:
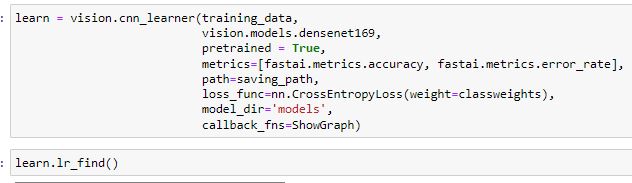
Here is the code used to generate it:
I would be really grateful is somebody could help me in figuring out the reason behind this behaviour.
Hi Miriam, that’s actually a pretty typical graph for a pre-trained model. You would only expect to see a sharp drop when you are actually training. If you want more details on gradient descent and learning rate, there are some excellent lessons in the 4th and 5th fastbooks:
In general when selecting the learning rate, you want to go “back” a notch or so, and not get too close to the bottom of the hill, so probably somewhere between 1e-03 and 1e-02. Hope that helps.
Hi DJ, thank you a lot for your reply.
My doubts arose looking at the plots in an example from the book (the same as those reported in the second link that you sent me) in which a slope could be observed when searching for the best learning rate to use in a transfer learning approach (starting from a pre-trained resnet34) for the fine tuning of the last layer group. The plot that I observed in my case reflects, indeed, the one obtained after unfreezing the model when one usually applies a discriminative learning rate.
In regards of your suggestion to use a learning rate somewhere between 1e-03 and 1e-02, I saw that with the data that I am analyzing, a learning rate of 1e-3 for the fine tuning of the head of the model is probably too high because, despite the training loss decreases, the validation loss doesn’t follow the training loss but rather oscillates around a certain value (e.g. 1.2, 0.9). Yet, the the accuracy on the validation set increases and in my understanding this phenomenon indicates an overfitting. Therefore I tried to reduce the learning rate and with a learning rate of 1e-5 I am able to observe also a decreasing of the validation loss with an increasing of the validation accuracy, of course slower compared to higher learning rates.
I would be happy if you could point out to me if there are any errors in the reasoning so that I can better understand how to interpret my results.
Hi Miriam, thanks for this detailed discussion, and the reminder that accuracy does not always shadow the loss! Your understanding is already more sophisticated than mine in a lot of ways, and I’m learning a lot from you.
You’ll definitely want to go with the learning rate that works the best in reality. “Going back one notch” is not a hard and fast rule. In this case, if you find a smaller learning rate is better, go for it.
The other question on what is causing “validation loss oscillating, validation accuracy increasing” is beyond my knowledge, hopefully others can give more insights. A good starting point seems to be this thread, including a couple of linked articles:
I have also browsed (emphasis on browsed, not studied) a few other related articles on stack exchange and the like, but could not find a real consensus for this type of phenomenon. Overfitting is often mentioned as a possibility, but there are numerous other opinions that are probably dependent on context. In the end, I have to shrug my shoulders and encourage you to explore this rabbit hole more if you have time - it is quite fascinating. Good luck and thanks for this opportunity for adventure!
The LR finder generally just provides a good starting point for your learning rate. I’ve run into instances where the value it provided was great, and others where I found a better value. It does do a pretty good job of showing you a hard upper bound of what your LR should not exceed.
There could be a number of reasons for the results you are observing. When you use a lower LR do your validation loss and accuracy metrics improve to values significantly better than achieved with the higher LR? If so then your LR is probably too high, if not it’s probably something else. What dataset are you training against? How many images are in that dataset (approx) and what batch size are you using? How much of your dataset is allocated to validation/test set? How many epocs are you running?