So, I was watching first video of practical deep learning can anyone explain me what exactly is happening in backward pass(using a diagram is much preferred i.e. take a curve & few points to explain)
So, I’ll explain what I have understood. In forward pass we take kaiming he weight & pass them throw linear layer, relu & linear layer. The output of that forward pass now needs to backpropogate and match the expected output
So, in backward pass. We calculate gradients…gradient is like how much we want to move the points to match the expected points/weights
So, we calcualte mse.grad, relu.grad, lin_grad & pass them outputs of each layer…like l1, out, l2, w2, b2, b1, w1 etc in reverese order
I’m I correct? Please help me get it 100% correct. Thanks much appreciated
Yes, your intuition is correct. We would do backward pass/back propagation, to update the weights.
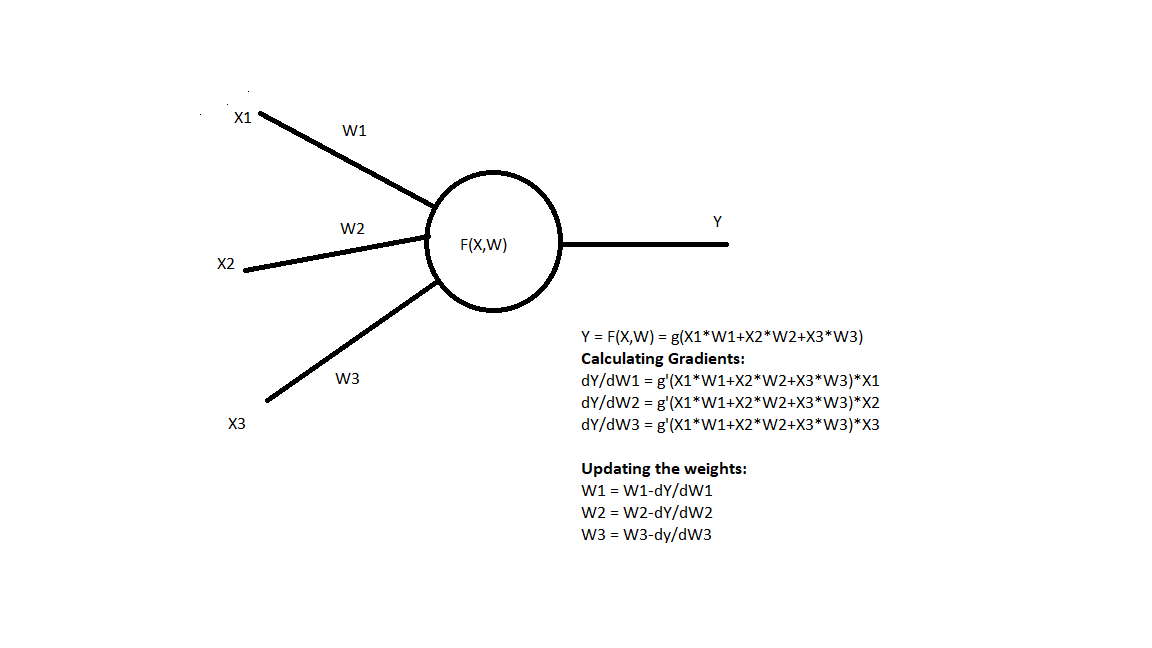
Consider the neural network consists of activations and weights(learnable parameters). For each and every computation you calculate the gradients of output with respect to an input
In this example, the X1,X2,X3 are activations and W1,W2,W3 are weights. Assume g is a function in which some activation(like sigmoid) is applied and loss is also calculated based on ground truth(like Cross Entropy loss). We have to calculate the gradient of the function for each learnable parameter in the backward pass and update it.
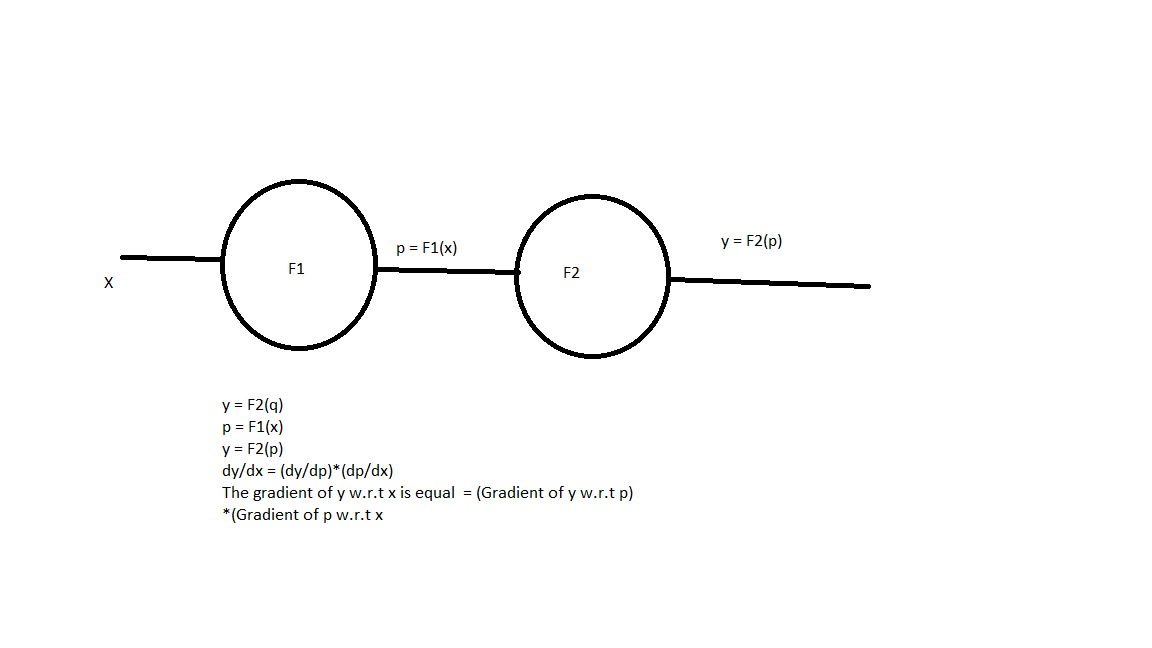
Now, let’s see why do we have to go backward
In this example, we have to calculate the gradient of x w.r.t y for that we need to know the gradient of y w.r.t p(dy/dp) first as per the equation. So, We first calculate that and multiply with dp/dx.
Similarly, in a neural network, there is a series of numerical calculation on each trainable parameter/weight. To calculate it’s gradient w.r.t loss we first calculate the gradients of later layers and go backward multiplying them.
Hope it’s clear to you now. If you have more doubts look at here
1 Like