As Jeremy mentioned, it’s a good idea to keep a lab notebook about the things you try when trying to train models on data. Here is an example of me playing around with California housing data using the same random forest regress or we did today in class. For comparison, I also compare with the results of gradient boosting trees. Please note how easy it is to try out different models on the same data. Also note that I show how to split a data set into training and testing samples.
Please note that the random forest did a pretty good job out of the box without me thinking about the model or doing any massaging of the data.
This is the standard scikit-learn version My version is in Java but I’ll be porting to Python (which will mean I’m slower than scikit as theirs is C underneath).
BTW, @jeremy, my earlier experiment was all screwed up because I miss typed max_leaf_nodes instead of min leaf node size or whatever it is. doh! I think I also screwed up interpretation of oob_score_, thinking that was the error and not the score. haha.
Wow all the steps look super handy and intuitive… I thought the process should be much harder but now it looks pretty easy to implement different models.
Yep, as @jeremy says, machine learning doesn’t have to be hard and scikit-learn makes it much simpler than earlier days. You just have to learn what to care about.
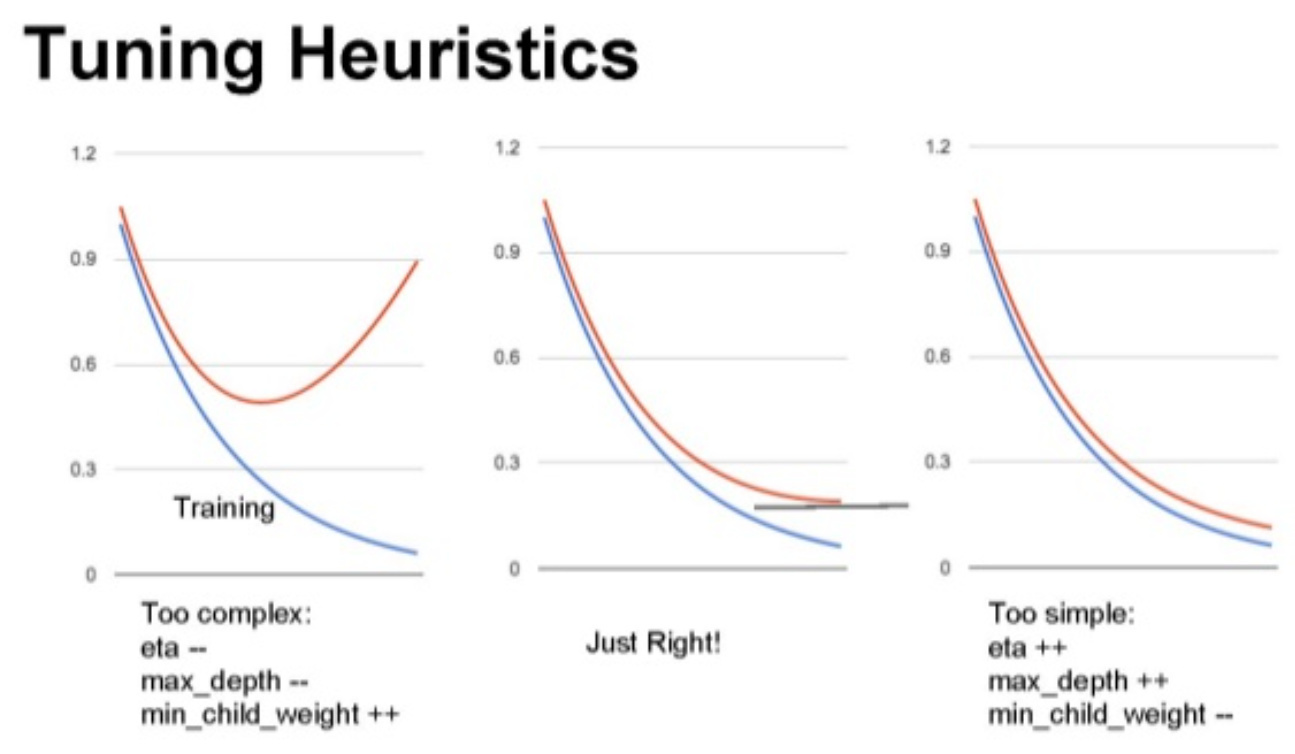
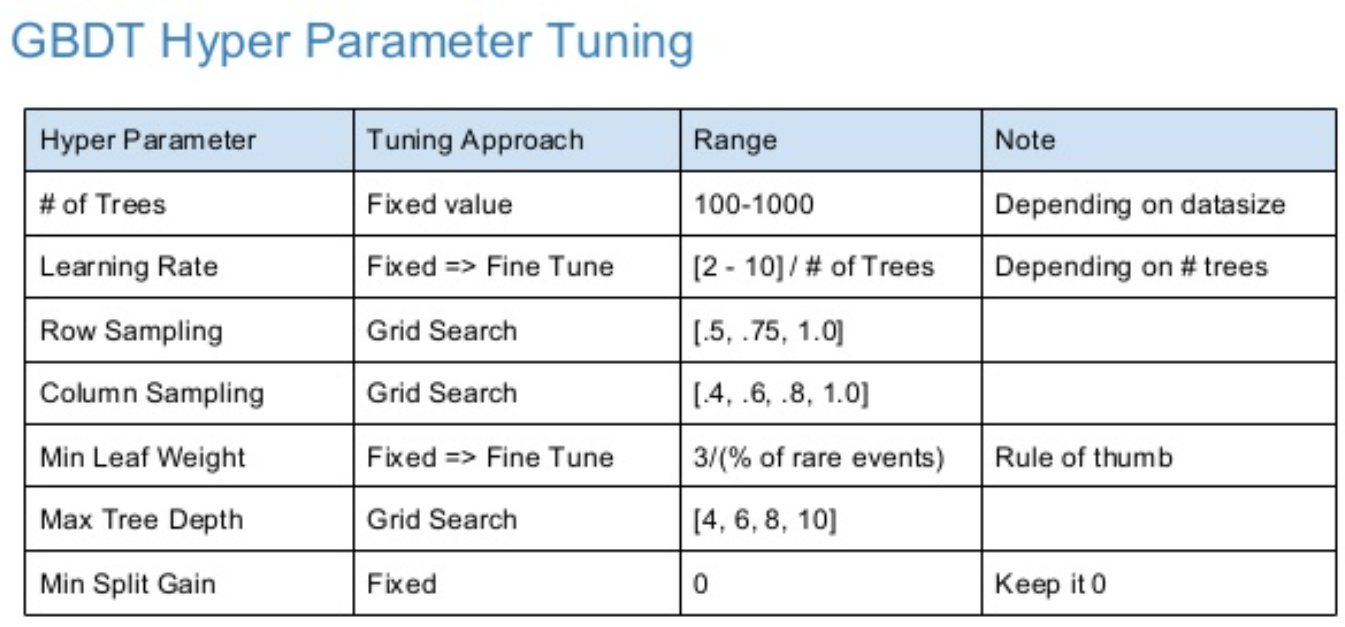
One thing to note @parrt is that gradient boosting trees are much more sensitive to hyperparameters than RFs. Generally, doing a grid search for hyperparams is necessary to get good performance, or manually carefully tuning. Here’s tips from former top ranked Kaggler Owen Zhang:
One thing to note is that this dataset only contains continuous variables, and no missing values, so @parrt was able to skip the steps where we handled these two issues.
They’re not hard either, mind you - just 3 lines of code!
Could anyone explain how to use train_cats()? I keep getting the following error when trying to use this function.
AttributeError: ‘NoneType’ object has no attribute ‘items’
Thoughts on pd.get_dummies()? My jupyter notebook crashes whenever I try to create a dummy variables using this function on features that have many many categories.
Generally speaking you shouldn’t need to use get_dummies() with tree-based methods - and almost certainly not if there are lots of categories. (As Terence mentioned, there aren’t any categorical vars in this dataset anyway).
Sorry, I should have clarified that my question pertains to a different data set that does have categorical variables. Regardless, train_cats() wasn’t working for me and neither was get_dummies() because there were too many “categories” (such as songID) within a couple features – get_dummies() would crash on those. I’m a little stuck on how to move forward. Any suggestions?
You manually set the fields to category type, so no need for you to call train_cats. train_cats changes string types to category types, and assumes that you don’t already have category types.