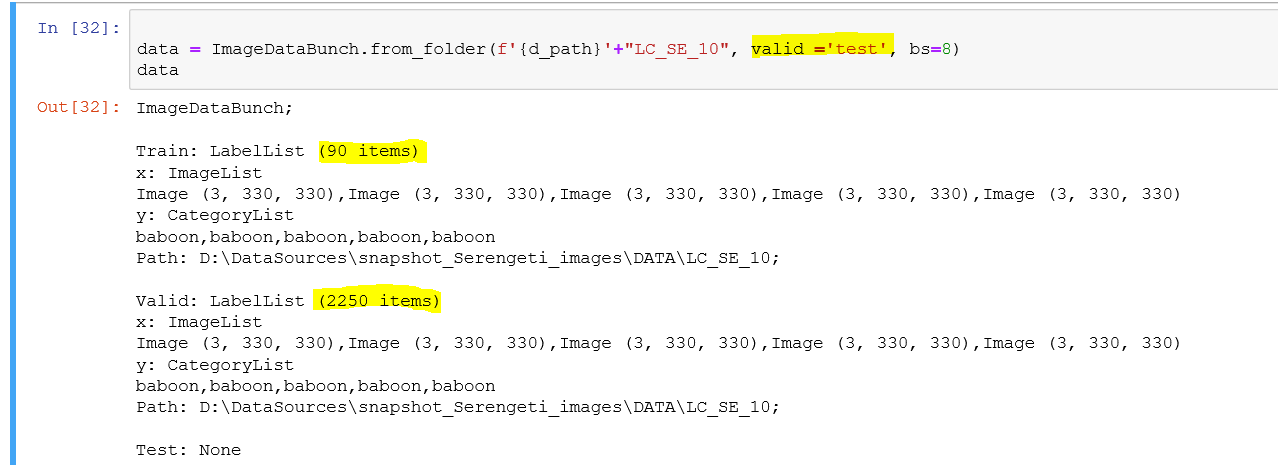
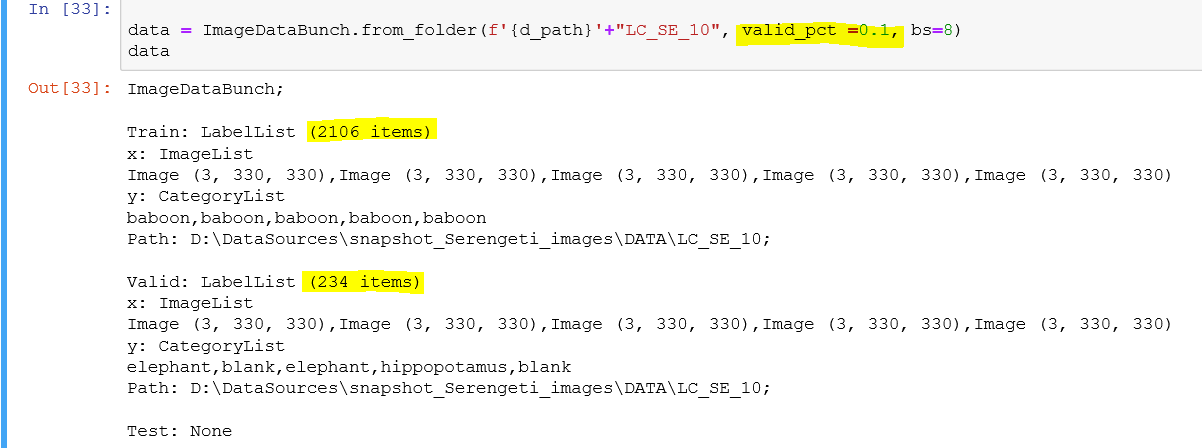
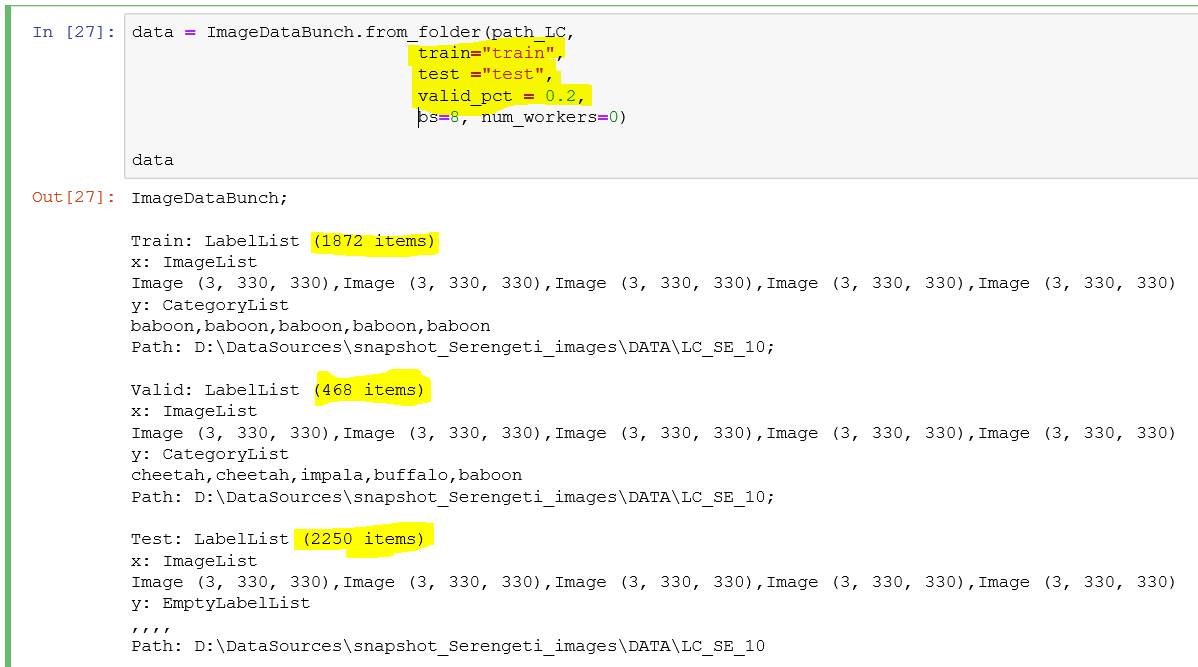
Here is the command I try using:
PATH = Path("kaggleData/competitions/imaterialist-challenge-furniture-2018/")
data = ImageDataBunch.from_folder(PATH, train="train", test="test", ds_tfms=get_transforms(), size=112, bs=64, valid_pct=0.90)
and I get this error:
---------------------------------------------------------------------------
UnboundLocalError Traceback (most recent call last)
<ipython-input-12-7267138863ad> in <module>()
3 #ds_tfms=([crop_pad(size=([112,112]))],[crop_pad(size=([112,112]))])
4
----> 5 data = ImageDataBunch.from_folder(PATH, train="train", test="test", ds_tfms=get_transforms(), size=112, bs=64, valid_pct=0.90)
6 #data = ImageDataBunch.from_folder(PATH, train="train", valid="valid", test="test", size=112, bs=64)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/fastai/vision/data.py in from_folder(cls, path, train, valid, test, valid_pct, **kwargs)
280
281 if test: datasets.append(ImageClassificationDataset.from_single_folder(
--> 282 path/test,classes=train_ds.classes))
283 return cls.create(*datasets, path=path, **kwargs)
284
UnboundLocalError: local variable 'train_ds' referenced before assignment
The problem is in the ImageDataBunch.fromfolder class. It currently looks like this:
@classmethod
def from_folder(cls, path:PathOrStr, train:PathOrStr='train', valid:PathOrStr='valid',
test:Optional[PathOrStr]=None, valid_pct=None, **kwargs:Any)->'ImageDataBunch':
"Create from imagenet style dataset in `path` with `train`,`valid`,`test` subfolders (or provide `valid_pct`)."
path=Path(path)
if valid_pct is None:
train_ds = ImageClassificationDataset.from_folder(path/train)
datasets = [train_ds, ImageClassificationDataset.from_folder(path/valid, classes=train_ds.classes)]
else: datasets = ImageClassificationDataset.from_folder(path/train, valid_pct=valid_pct)
if test: datasets.append(ImageClassificationDataset.from_single_folder(
path/test,classes=train_ds.classes))
return cls.create(*datasets, path=path, **kwargs)
, but if you use valid_pct (aka valid_pct != None), train_ds never gets set initially. So when you do that and use test, it is trying to call train_ds, but that doesn’t ever get defined, it just goes straight to datasets. My suggestion to fix this is to do the following:
@classmethod
def from_folder(cls, path:PathOrStr, train:PathOrStr='train', valid:PathOrStr='valid',
test:Optional[PathOrStr]=None, valid_pct=None, **kwargs:Any)->'ImageDataBunch':
"Create from imagenet style dataset in `path` with `train`,`valid`,`test` subfolders (or provide `valid_pct`)."
path=Path(path)
if valid_pct is None:
train_ds = ImageClassificationDataset.from_folder(path/train)
datasets = [train_ds, ImageClassificationDataset.from_folder(path/valid, classes=train_ds.classes)]
else:
datasets = ImageClassificationDataset.from_folder(path/train, valid_pct=valid_pct)
train_ds = datasets[0] #<--------This line is the fix I am proposing
if test: datasets.append(ImageClassificationDataset.from_single_folder(
path/test,classes=train_ds.classes))
return cls.create(*datasets, path=path, **kwargs)
I believe this fixes the issue without adding complications, but the other alternative would be instead of this line:
if test: datasets.append(ImageClassificationDataset.from_single_folder(
path/test,classes=train_ds.classes))
changing it to something like this:
if test: datasets.append(ImageClassificationDataset.from_single_folder(
path/test,classes=datasets[0].classes))
I believe both solutions solve the issue so I guess whichever one is preferable.
Here is my install information:
=== Software ===
python version : 3.6.6
fastai version : 1.0.14
torch version : 1.0.0.dev20181015
nvidia driver : 396.24
torch cuda ver : 9.2.148
torch cuda is : available
torch cudnn ver : 7104
torch cudnn is : enabled
=== Hardware ===
nvidia gpus : 2
torch available : 2
- gpu0 : 11175MB | GeForce GTX 1080 Ti
- gpu1 : 11178MB | GeForce GTX 1080 Ti
=== Environment ===
platform : Linux-4.15.0-36-generic-x86_64-with-debian-stretch-sid
distro : Ubuntu 16.04 Xenial Xerus
conda env : fastai
python : /home/kbird/anaconda3/envs/fastai/bin/python
sys.path :
/home/kbird/anaconda3/envs/fastai/lib/python36.zip
/home/kbird/anaconda3/envs/fastai/lib/python3.6
/home/kbird/anaconda3/envs/fastai/lib/python3.6/lib-dynload
/home/kbird/anaconda3/envs/fastai/lib/python3.6/site-packages
/home/kbird/anaconda3/envs/fastai/lib/python3.6/site-packages/IPython/extensions
/home/kbird/.ipython