For some epochs of training the valid_loss will increase and at the same time the root mean square error metric will decrease and vice versa. It is my understanding that the tabular model uses mean squared error for the valid loss in regression tasks. Hence it does not make sense for them to move in different directions.
I am training a tabular model on a very similar problem to the Rossmann forecasting example.
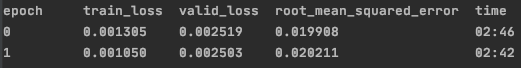
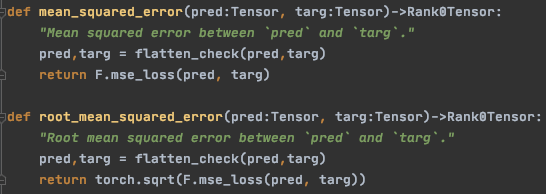
I have looked at the tabular model source code to figure out what loss function its uses and can only find the loss function being assigned to F.nll_loss which wouldn’t make sense for a regression problem as i understand it.
In basic_data.py:

The only reasons I can think for the diverging valid_loss and rmse metric is that they using different segments of data (i thought they both used the valid data set) or it isn’t actually the mse being used to calculate the valid_loss.
Any help on this would be much appreciated I’m struggling to nail the reason myself and it is making it difficult to compare specifications when I have two metrics telling me different things ie I am not sure which one to trust as the final influencer of my specification.
Many thanks
Alex