In lesson1-pets, using the jupyter notebook
On this line: data.show_batch(rows=3, figsize=(7,6))
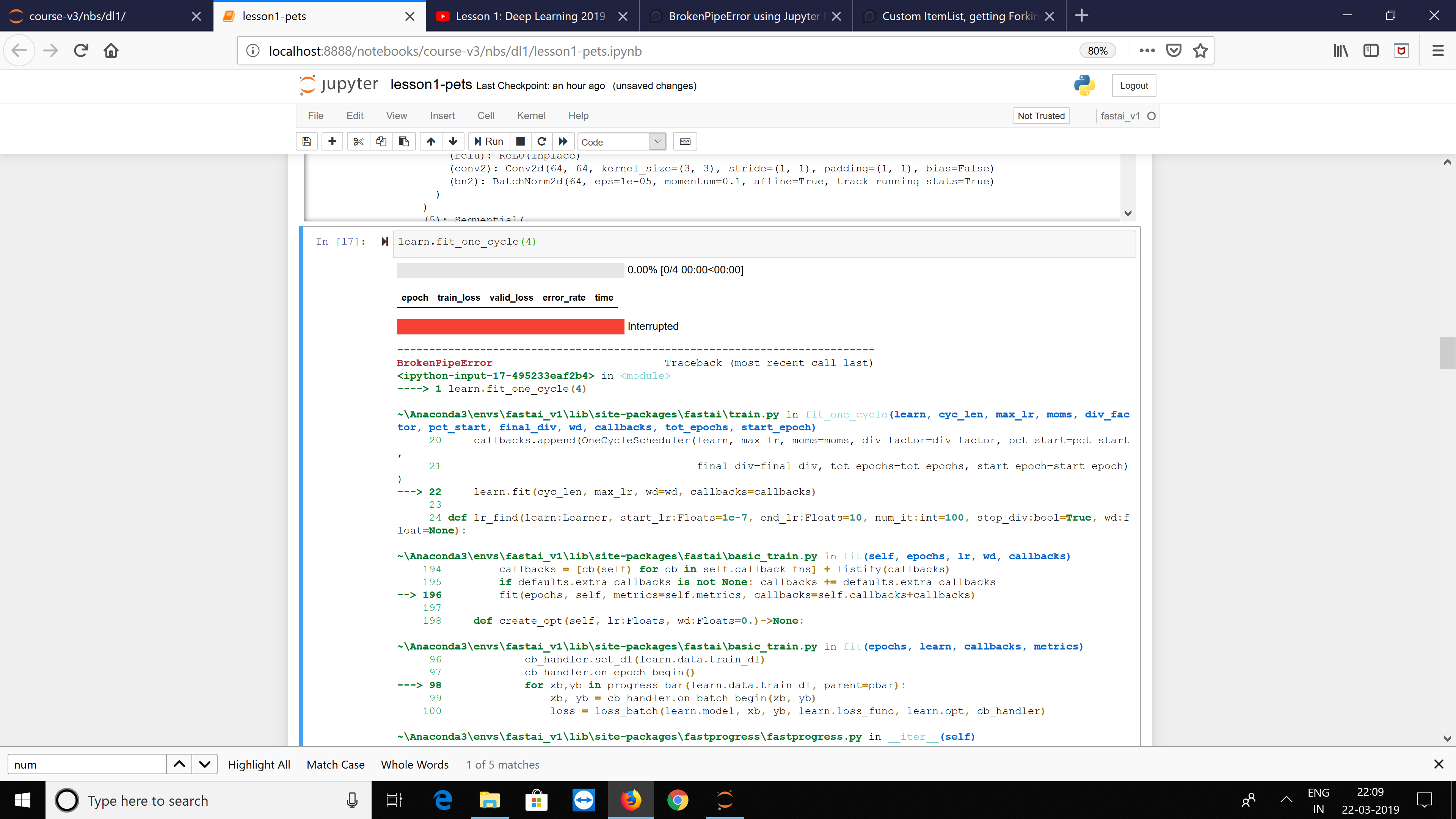
I get this error message:
BrokenPipeError Traceback (most recent call last)
in
----> 1 data.show_batch(rows=3, figsize=(7,6))~\Anaconda3\lib\site-packages\fastai\basic_data.py in show_batch(self, rows, ds_type, reverse, **kwargs)
183 def show_batch(self, rows:int=5, ds_type:DatasetType=DatasetType.Train, reverse:bool=False, **kwargs)->None:
184 “Show a batch of data inds_typeon a fewrows.”
→ 185 x,y = self.one_batch(ds_type, True, True)
186 if reverse: x,y = x.flip(0),y.flip(0)
187 n_items = rows **2 if self.train_ds.x._square_show else rows~\Anaconda3\lib\site-packages\fastai\basic_data.py in one_batch(self, ds_type, detach, denorm, cpu)
166 w = self.num_workers
167 self.num_workers = 0
→ 168 try: x,y = next(iter(dl))
169 finally: self.num_workers = w
170 if detach: x,y = to_detach(x,cpu=cpu),to_detach(y,cpu=cpu)~\Anaconda3\lib\site-packages\fastai\basic_data.py in iter(self)
73 def iter(self):
74 “Process and returns items fromDataLoader.”
—> 75 for b in self.dl: yield self.proc_batch(b)
76
77 @classmethod~\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py in iter(self)
817
818 def iter(self):
→ 819 return _DataLoaderIter(self)
820
821 def len(self):~\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py in init(self, loader)
558 # before it starts, and del tries to join but will get:
559 # AssertionError: can only join a started process.
→ 560 w.start()
561 self.index_queues.append(index_queue)
562 self.workers.append(w)~\Anaconda3\lib\multiprocessing\process.py in start(self)
110 ‘daemonic processes are not allowed to have children’
111 _cleanup()
→ 112 self._popen = self._Popen(self)
113 self._sentinel = self._popen.sentinel
114 # Avoid a refcycle if the target function holds an indirect~\Anaconda3\lib\multiprocessing\context.py in _Popen(process_obj)
221 @staticmethod
222 def _Popen(process_obj):
→ 223 return _default_context.get_context().Process._Popen(process_obj)
224
225 class DefaultContext(BaseContext):~\Anaconda3\lib\multiprocessing\context.py in _Popen(process_obj)
320 def _Popen(process_obj):
321 from .popen_spawn_win32 import Popen
→ 322 return Popen(process_obj)
323
324 class SpawnContext(BaseContext):~\Anaconda3\lib\multiprocessing\popen_spawn_win32.py in init(self, process_obj)
63 try:
64 reduction.dump(prep_data, to_child)
—> 65 reduction.dump(process_obj, to_child)
66 finally:
67 set_spawning_popen(None)~\Anaconda3\lib\multiprocessing\reduction.py in dump(obj, file, protocol)
58 def dump(obj, file, protocol=None):
59 ‘’‘Replacement for pickle.dump() using ForkingPickler.’‘’
—> 60 ForkingPickler(file, protocol).dump(obj)
61
62 #BrokenPipeError: [Errno 32] Broken pipe
I have installed fastai according to the instructions.
conda install -c pytorch -c fastai fastai
conda install jupyter notebook
conda install -c conda-forge jupyter_contrib_nbextensions
I am on Windows 10, GPU is geforce gtx 1060.