I’m looking at BPTT and am wondering what sort of intuition everybody uses to determine BPTT? I’m currently using a BPTT of 12, but I don’t really know what that means. Anybody have a good handle on what BPTT actually does? Maybe a blog or paper that is worth reading on the topic?
The bptt just breaks up the inputs to your language model (LM) into manageable chunks. It determines how many timepoints into the past that you are handling in a single minibatch.
Let’s say that you’re training a LM on a corpus that is ~10M tokens long. Your choice of bptt and batch-size (bs) determines the size of the minibatch that you handle at a given time. Suppose you choose a bptt of 20 and a bs of 100. How that works is you take the ~10M-tokens vector, split it into 100 parts, and stack all 100 parts on top of each other, then transpose. What you wind up with is a matrix of size (100K,100). Then, you grab a minibatch of size (20,100) and pass it into your NN.
For a language model, you’re trying to predict the next word in the sequence, so the target is also going to be size (20,100). So you pass your minibatch through the NN, compute the loss between the output and the target, and update all the weights in your network based on that. Repeat until you’ve gone through your entire dataset.
6 Likes
I’ve rewatched lesson 6 many times trying to understand it (still need to give it a few more runs) but outside of fastai, I liked this article - https://machinelearningmastery.com/gentle-introduction-backpropagation-time
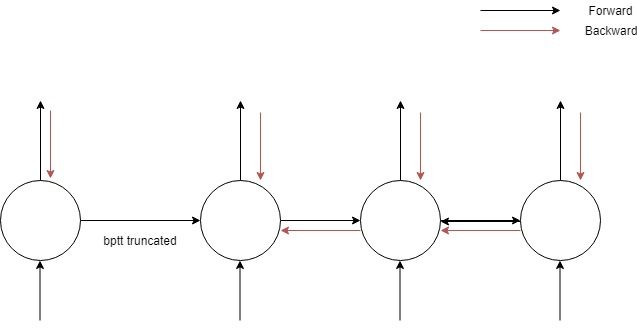
The key point is the difference between bptt and truncated bptt (which we implement in fastai)
If we look at this tiny network, full bptt would be a backprop through all the neurons in the network but a truncated bptt will not backpropogate through all layers in the horizontal direction
I’m not clear on what value we should set. I would say that it should be the maximum we can afford based on available compute, which is probably wrong. Jeremy mentioned that torchtext uses some form of augmentation in bptt in lesson 6 varying it for different mini batches.
A couple of questions I’ll add.
Is there a relationship between batch size and bptt that we should consider?
Will a higher value of bptt generally perform better than a lower one?
thanks
3 Likes
At 21:45 of the lesson 7 video, someone asks Jeremy how to pick bptt.
He brings up three issues to consider:
- A given minibatch matrix is size (bptt,bs), so it needs to fit in GPU memory. If you’re getting out-of-memory error, need to reduce bptt or bs.
- If training is unstable (loss suddenly shooting off to Nan), try reducing bptt bc you have less layers to gradient-explode through.
- If training is too slow, can reduce bptt. The rnn ‘for-loop’ can’t be parallelized, so a longer bptt will take longer to train.
Overall, pick a bptt that is high as possible while making sure performance, memory, and stability are optimal.
6 Likes
Bptt is the number of tokens you read before trying to predict the next token. In your “counting to 10” example you technically don’t need anything beyond 1. I went as low as 3 and it worked fine.
If you’re trying to predict English words, the longer sequence your model reads the easier it will be to predict the target word. If you only read say 3 words, “how can I” and try to predict the 4th word it’s going to be super hard to get the 4th word right…as there Are so many words that can go after “How can I”.
3 Likes