Highlighting the Big Transfer (BiT) paper from google that @jeremy pointed out on twitter, achieves SOTA on a wide variety of downstream computer vision tasks with fairly standard fine-tuning.
BiT-Large pre-trained on JFT-300M dataset appears to be a fairly simple pre-training process and architecture, Interestingly (for me anyways) they ditched BatchNorm in favor of a combo of GroupNorm + Weight Standardisation in order to train sufficiently large batches.
Fine-tuning uses SGD, Mixup, fixed resolution scaling rules, random square crops and image flips (where appropriate).
They will be releasing code + weights + examples soon
Aside from ditching BatchNorm, nothing seems to be too revolutionary (or maybe I’m wrong), glad to see these fastai basics are still killing it
They mention that additional hyperparamter tuning could lead to better results again. With @LessW2020’s optimizer work and @Diganta’s Mish activation function the community here could probably push these results In guessing
they also use no Dropout or Weight Decays…
But I agree with you, this boundary can be pushed further with new optimizers, training schedules, gradual unfreezing, gradual image size increase etc…=)
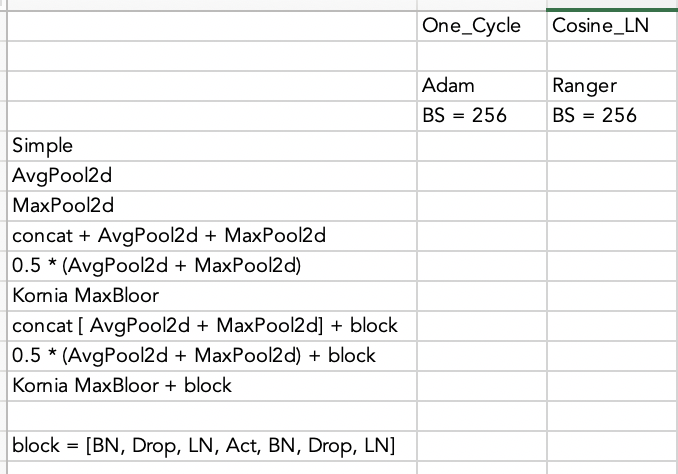
I think we as fastai community can perform systematic experiments and make nice repo on best practices how to do transfer learning and achieve state of the art results =)
Might be an idea to limit it to vision classification at first? How to break out architecture tweaks from training techniques (e.g. training schedule)?
Awesome, was out for a few days there, your list above sounds like a good place to start, thanks @DrHB! Yep its a good idea, would like to get myself up to speed on fastai2 too before kicking off new work.
Hey, great start by the sounds of it! Sorry have been trying (unsucessfully) to compete in the Google Quest comp on Kaggle, will get to this tomorrow once it closes!