Hi guys,
I’ve been thinking about this for some time now. The datasets I work with are usually highly imbalanced, with positive/negative ratios as low as 1:1000. It’s not uncommon get metrics like this:
Negative samples: 33440
Positive samples: 287
Matthews correlation coef. = 0.554
Recall = 0.533
Specificity = 0.996
Precision = 0.583
Balanced accuracy = 0.765
Area under precision-recall curve = 0.492
I realised that even if 99,9% of the negative samples are correctly classified, the remaining 0.004% are still close to the number of true positives
I work with early drug discovery using ML and DL to prioritize molecules for biological testing. Intuitively, I’d say filtering 0.996% of the negative samples is a good thing, which translate to not spend money on things that won’t work in bio testing. But those metrics, especially the precision and recall, makes me feel unease.
I know I can change the threshold for classification using the precision-recall curve, but is that the best we can do? Suppose we tried resampling methods (i.e., undersampling, oversampling etc), different weights for positive and negative classes etc. How do we know that a model is ready for production / publication when the metrics are quite different from what tutorials shows, with amazing accuracies of 0.98?
2 Likes
Hi marcossantana hope all is well and you are having a beautiful day.
In Jeremy’s book he talks abount bench marking. before you even make an ai model, so you could still do it even if you haven’t done so already.
The first point was to have a bench mark which didn’t use ML or AI.
So for example what sort of results would you get, if you had to do the your task without AI, eg. manually or using some form of statistical analysis. (Does your model do better than the bench mark models?)
In the 04_mnist_basics.ipynb Jeremy uses a pixel similarity algorithm to recognize 3 and 7’s.
he then compares this approach to using an ai model to recognize the characters.
In some circumstances other approaches are often better.
In chapter 2 of the fastai book Jeremy talks about deploying your model.
The section titled How to Avoid Disaster may be particularly relevant.
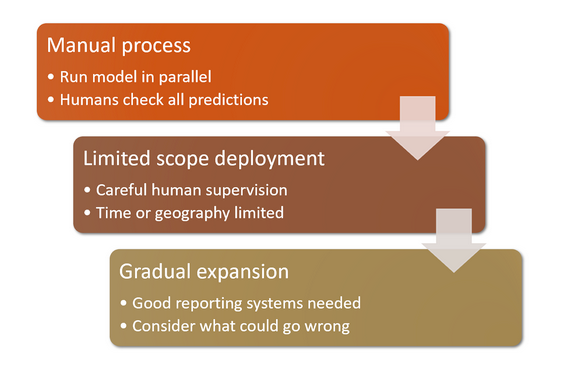
Over time applying the above process to your model would give me confidence one way or the other, if I were using your models.
If other methods were producing 40% and 50% accuracy, then even though your model was producing 78% that would clearly be better.
You could make the changes you suggest and if you use the above approach over time you will observe which gives the best results.
Just a thought hope this helps.
Cheers mrfabulous1 
4 Likes