My current obsession is trying to understand and implement this idea: https://arxiv.org/abs/1603.06208. There’s a PyTorch implementation that I’ve been referencing and learning from. I’m trying to implement it into the fast.ai framework for my own practice and education.
I’ve already got batches loading and training, but I’m stuck at one part. Each data point consists of 20 images of a single object from different perspectives, so the batch size has to be a multiple of 20 with no shuffling. Unfortunately, this means that the images are running through the CNN in the same order every epoch, and its training maximizes out with an accuracy of around 20-30%. The Pytorch implementation fixes this by randomly shuffling the order of the 20-image groups each epoch.
I’ve tried several approaches to do this same thing using fast.ai’s structures, but I can’t get anything to work and I’m getting lost trying to keep track of ImageLists, LabelLists, CategoryLists, etc. The PyTorch implementation is clean and straightforward. Is there a similar way to do this with fast.ai?
I don’t think I understand. Are you suggesting that I need to create a custom image data bunch? As I’ve currently implemented it I use a standard ImageDataBunch but turn off the data loader’s shuffling and use the batch size to make sure that the 20-image groups aren’t broken up into separate batches (I need the groups to make it through the CNN intact for further calculations and processing after each batch). Do you think I need to make a data bunch that groups the 20 images (and their label) into a single datapoint? I could then turn the data loader’s shuffling back on and problem solved. Or is there an easier way? I’m not afraid to try my hand at making a custom data bunch, but wanted to make sure there’s not some easier way that I’m overlooking.
For posterity, I resolved this. After trying my hand at creating a custom ItemBase, ItemList, etc. I got overwhelmed and decided to revisit the PyTorch implementation approach. Here’s the solution I came up with:
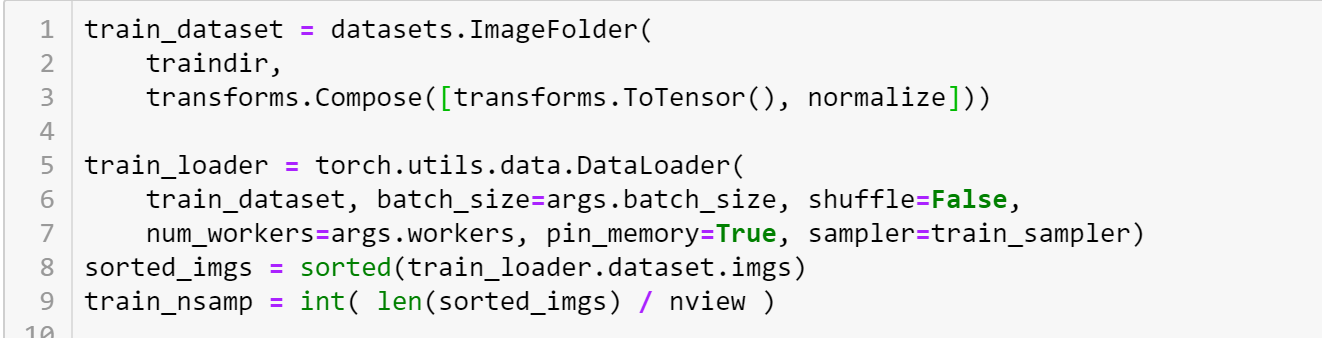
After creating the ImageDataBunch, I saved out the “items” from the datasets, and sorted them, since ImageList.from_folder seems to grab images from directories in no particular order, that I could tell.
Then, I created a learner callback for on_epoch_begin that creates a new ImageList and CategoryList containing the shuffled items, and then overwrites the learner’s current training set lists:
# random permutation
train_nsamp = int( len(learn.data.train_ds) / nview )
inds = np.zeros( ( nview, train_nsamp ) ).astype('int')
inds[ 0 ] = np.random.permutation(range(train_nsamp)) * nview
for i in range(1,nview):
inds[ i ] = inds[ 0 ] + i
inds = inds.T.reshape( nview * train_nsamp )
IL = ImageList([sorted_img[i] for i in inds], path=path)
learn.data.train_ds.x = IL
CL = CategoryList([sorted_cats[i] for i in inds], classes=classes, path=path)
learn.data.train_ds.y = CL
My CNN is happily training above the 90% accuracy range now. It was quite a shock to see what a major improvement the simple act of shuffling training data makes. I’m not sure I completely understand it intuitively yet, but lesson learned. Shuffle data when training!