So I’m trying to replicate Jeremy’s results using Fast.ai on a dataset which is really different from the kind of pictures resnet has been trained on.
I’m using this dataset : Chest Xray, which contains xray from people having pneumonia or not (binary classification).
The dataset is not big and has 5216 training images which are unbalanced (3875 pneumonia / 1341 normal), and a validation set of 624 images.
So I’m trying to follow what Jeremy did when he used satellite images with transfer learning on Resnet34 (lesson2-image_models).
But no matter what I try my model never generalizes. My training loss and validation loss are diverging almost immediately, and my training loss << validation loss. So I’m overfitting.
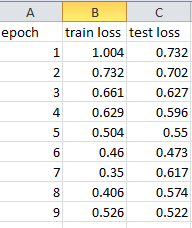
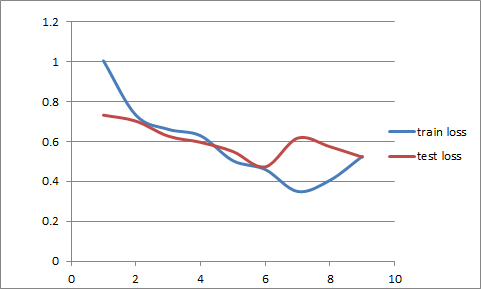
I tried to change the size of the images because my guess was that starting at a size of 64 was too little for X-ray scans, I tried to bump the dropout to 0.75. I increased and decreased batch size, and try to not use data augmentation. But nothing worked, my model always overfit when training the last layers. Here’s a picture of what it look likes :
No matter the hyperparameters it is always the same pattern where my trn_loss and val_loss start high and my training loss then decreases but my validation loss stays the same or increases.
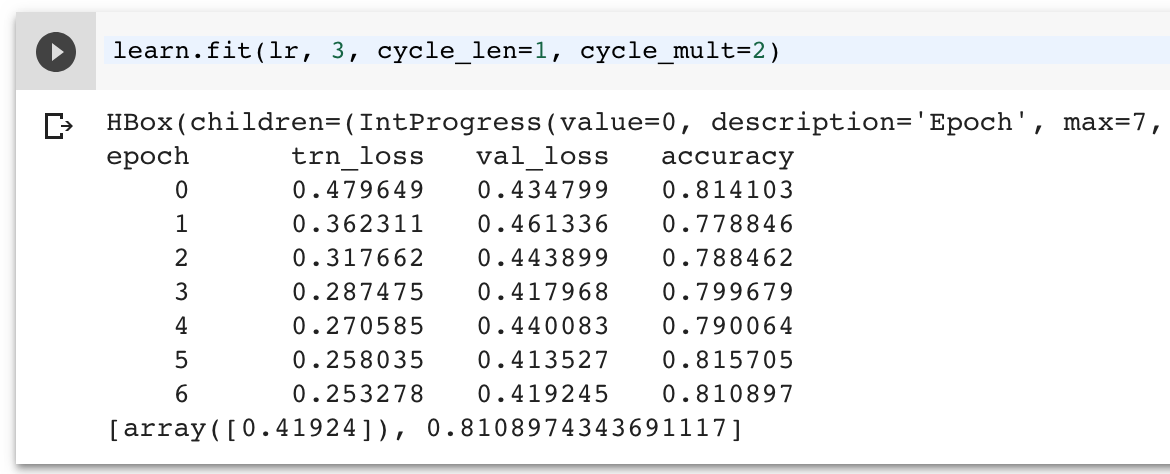
I also tried to unfreeze the pre-trained layers and train them with differential learning rates but it just made thing worse. Here’s one example :
So at that point, am I right to think that resnet34 (I also tried with vgg16) pre-trained on ImageNet don’t work with that dataset of xray scans ? Or maybe I need to work on the scans themself before feeding them into the model ?
What are the best practices when our model is prone to overfit ? Maybe there are other things to tweak to try and make that work ?
I also have a question regarding overfitting. Can a model during training recover automatically from overfitting ? Let’s say that the training loss start decreasing and the validation loss increasing, should I stop the model right away and change my hyperparameters or can it recover from overfitting after a few epochs ?
I’m also new to Deep Learning and I’m trying to have a sense of the numbers. We are talking of overfitting when the training loss is lower than the validation loss, right. But by how much ? If the difference is around 0.1 is it overfitting ? 0.2 ? 0.5 ?
And one last question I swear
Is there a technique to train our model on lots of epochs and saving the weights after each one so we can go back to the state where the model was the better ?
Let’s say that we train on 50 epochs but after epoch number 34 our model start to overfit. Maybe I want to go back and use the weights the model had at epoch 34 without restarting from scratch.
Well your log shows that the accuracy is improving so things are ok:) Training loss is always small than val-loss.
To reduce/avoid overfitting there are several techniques
data augmentation. THIS is very important when the dataset is small
weight decay, ie the wds argument in fit fx wds = 1e-4
dropout
You might want to experiment with training of the dogs&cats and cifar10 dataset to internalize the different training parameters/methods. Especially cifar10 ns MNIST are fast to train.
What are the tell-tale signs of overfitting? These are good tips for how to deal with overfitting, but what are the signals / signs? This is something that is still unclear to me. Thanks~~
Personally,
I used learn.save(‘448’) and learn.load(‘448’) everytime after i used learn.fit. Doing that I can always go back and used the weights before anything like overfitting or kernel froze up happened. I can shut down the kernel, go back to it and just load the weights and continue the training from where it left.
Also, other ways to avoid overfitting, Jarame mentioned in one of the videos about increasing the sz. I think it’s in video 2 or 3. don’t know if you have tried it?
maybe you will get some thought in this article: http://wiki.fast.ai/index.php/Over-fitting
hope it helps! feel free to correct me and share your progress.
no, it’s not always like that. it usually starts with trn_loss> val_loss, then with you training more and more epochs val_loss number will start to get larger. and at one point it will be bigger than trn_loss that’s when it start to overfitting. just look at the first picture in this post
I asked this in the v3 forum – you’re assumption of val loss > train loss == overfit is wrong. Assuming a well constructed validation set, watch your metrics. That’s what they’re for. If you don’t have a good val set then you’re flying blind.
In your above examples you can/should train longer.
Also remember that sometimes you’ll “see” a model popping out of a local – one epoch of bad numbers doesn’t mean you’re done.
I found something weird after I click on the link it says “sorry, you don’t have access to that topic” do you know how can I get the access?
from the title seems like it is limited to deep learning course?
thanks.
" Sorry for making a new topic about this, but the discussion is scattered in various threads.
My take away from the lessons I’ve completed so far is sort of split between two camps:
You want train loss > validation loss (under fit) or = validation loss (perfectly fitting.) As soon as validation loss > training loss, you are over fitting.
As long as your accuracy on the validation is still increasing, you’re good to continue training.
Can someone help disambiguate for me?"
Jeremy’s response:
“It’s the 2nd. (1) is definitely not true - I actually explicitly made that case a couple of lessons ago. But I do agree many folks on the forum have incorrectly claimed it.”




 do you know how can I get the access?
do you know how can I get the access?