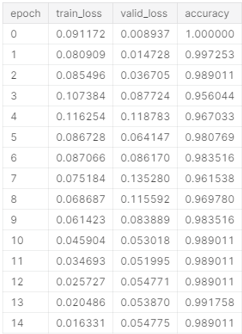
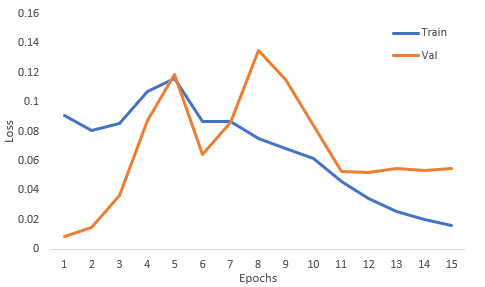
Hey! I tried to fine-tune a pretrained EfficientNet-B7 using ~1450 images for train and ~360 images for validation. I trained only the first stage, using a learning rate of 3e-4, and ran it for 15 epochs (with the idea of picking the model at the best epoch). These are the results I got:
Could somebody explain what’s happening? What can we infer about this behaviour?
I think this is going to come down to your data. Just looking at the graph and your hyper parameters leaves too much up to interpretation.
Based on experience alone, this may be something like the images being part of the dataset that the pretrained weights have already been trained on. So you really need only ~1 epoch to get your network trained, with a lower learning rate.
Overall your validation loss might be sporadic enough that your aren’t normalizing correctly? Are you normalizing your inputs the same in both your training and validation set?
Just a few ideas, we won’t know without more information about your dataset, and preferably a minimally reproducible example if you can supply some code.
For this problem I used a stratified crossvalidation with 5 folds and the same hyperparameters for all of them (i.e. LR: 3e-4, epochs=15, batch_size=32, image_size=224x224 and mixed precision). Here is a snapshot with the relevant code (I omitted the inference part):
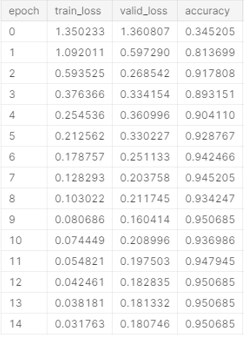
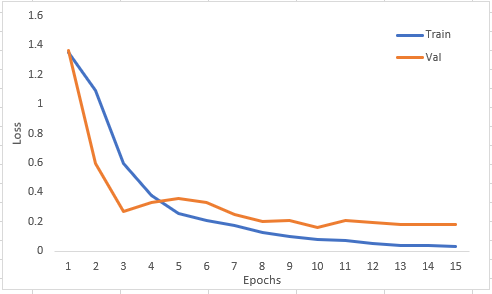
In 4 of the 5 folds I got the behaviour I described in my first comment (I posted the results for fold 4). Only in the 1st fold I got something “more reasonable”:
@muellerzr@marii Hey! I think the problem is that the learner is not restarting at the end (or at the beginning, when it is instantiated) of each CV iteration. Even though I set learn=0 at the end, the learner at the next CV iteration starts the training where it ended at the previous one. This explains why in fold 2 and the following ones the best score is at epoch one. I tried using learn=0, learn.destroy(), del learn and gc.collect() …, but nothing seems to work. Do you know a way to fix this problem?
Thanks!