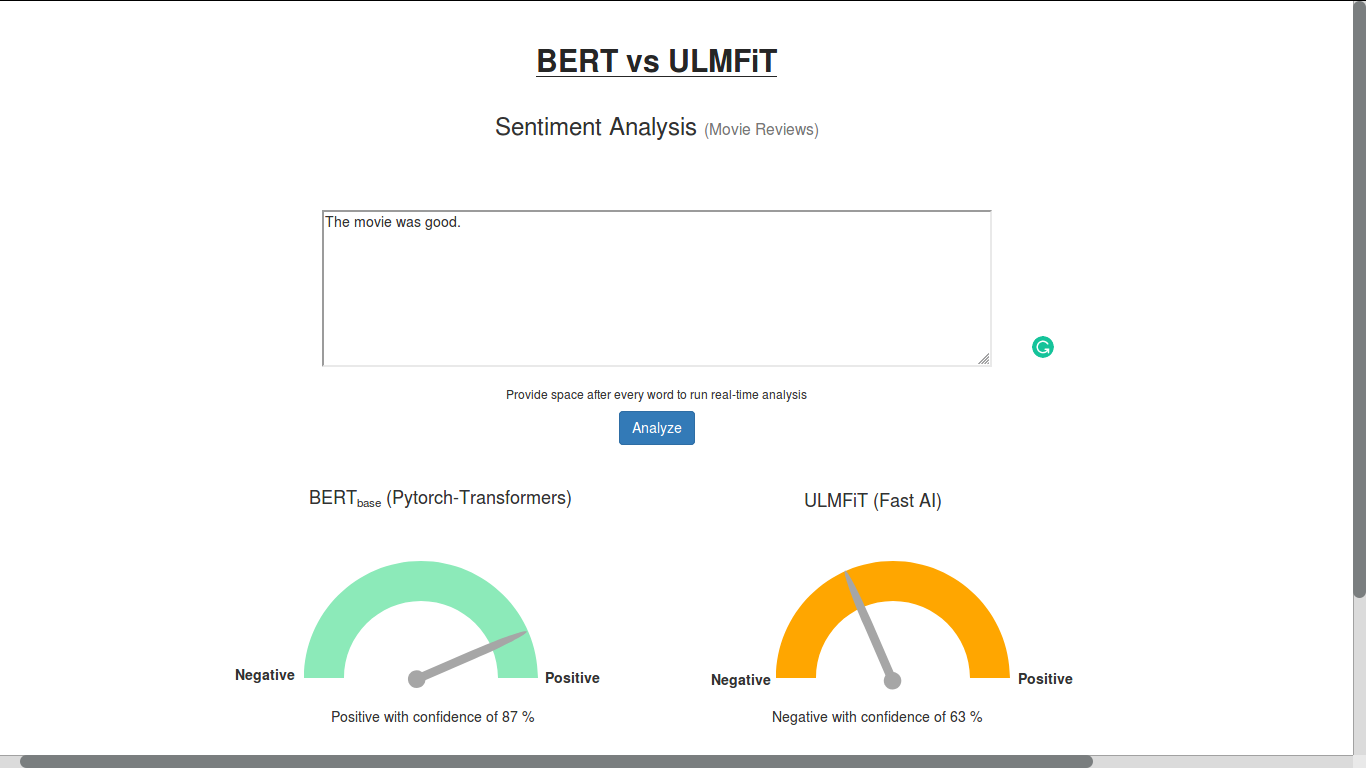
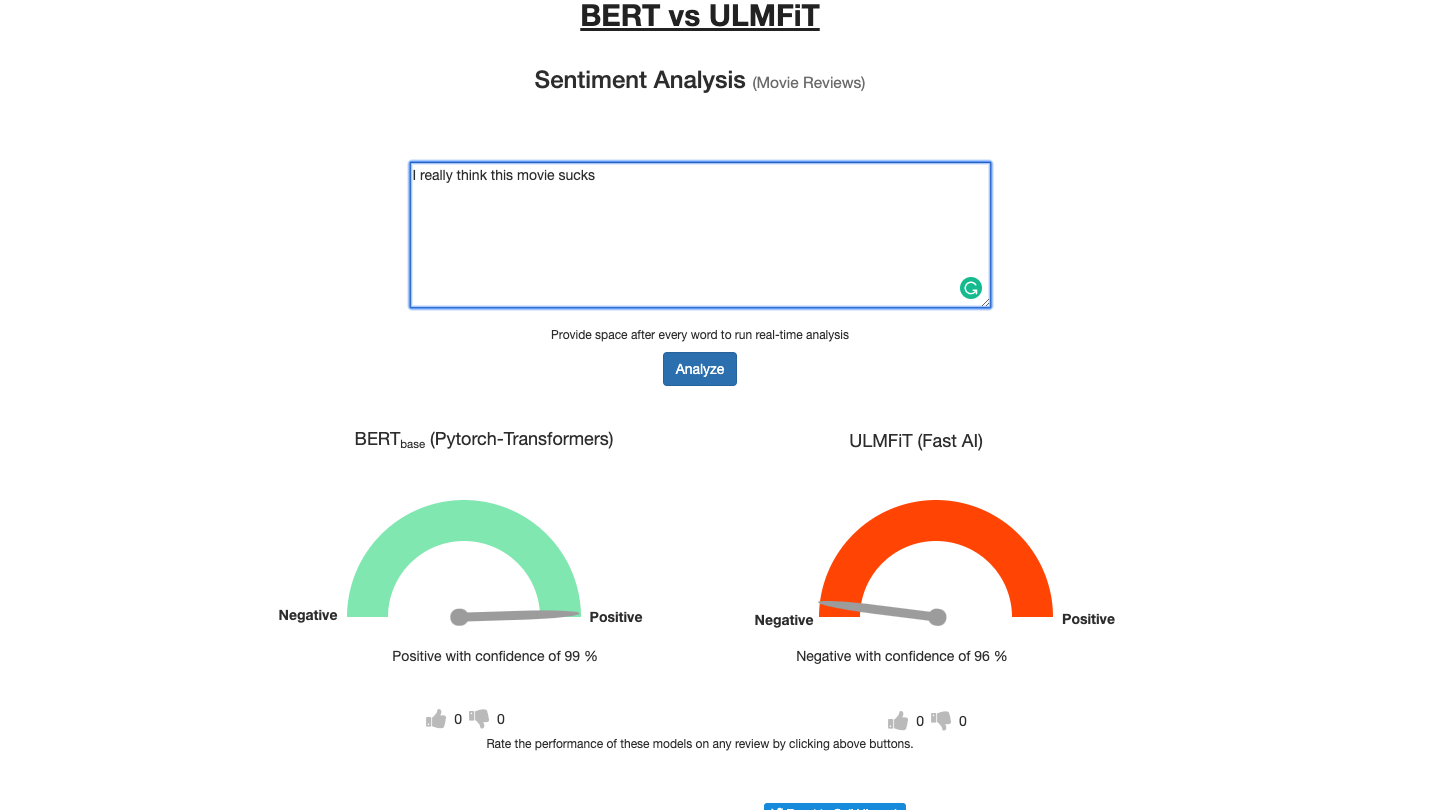
Hi, when pytorch-transfomers was released, I wanted to try it out to see how well it performs and how convenient it is to use. So I got started, one thing led to another and ended up building this BERT vs ULMFiT sentence classfier (trained on IMDB dataset) web app.
It is deployed on Google App engine. I have also added an option to provide feedback on reviews where a model does really well (or not) which we can then further analyze.
I ran the same prediction in the official IMDB notebook and it gave me same prediction. Are you observing anything different?
My guess is that ULMFiT doesn’t like short sentences. If you add something more then the sentiment may turn positive.
I ran into issues with ULMFiT using short sentences too. “I farted because I laughed so hard” it thought was a very negative sentiment, whereas BERT was a positive prediction.