What’s the “proper” way to learn from the fast.ai course and other similar courses? I sometimes follow along and sometimes watch the videos. But, it feels like I’m not learning very much.
I recommend you:
- Watch the video with full attention
- Then run all the notebooks and read the book chapters while you execute the corresponding notebook
- Then try to recreate whatever you learnt in this lesson in a specific application of your liking. This time, try not to follow along the tutorial but write everything from scratch (of course reading the book or googling when stuck is allowed)
That’s what I’m doing.
I’m not intimate with the cleaner but AFAIK it works by physically moving image files between folders, so trying to use it with dataset structured differently is out of scope.
From this I understand you are not looking for information on random forests.
Can you describe the actual information covered after random forests that you are seeking, rather than referring to it indirectly. Its inefficient for volunteer time to search and guess what you are referring to. Also adding a time stamped link into the lesson video might be useful.
Great morning everyone, its a wonderful day.
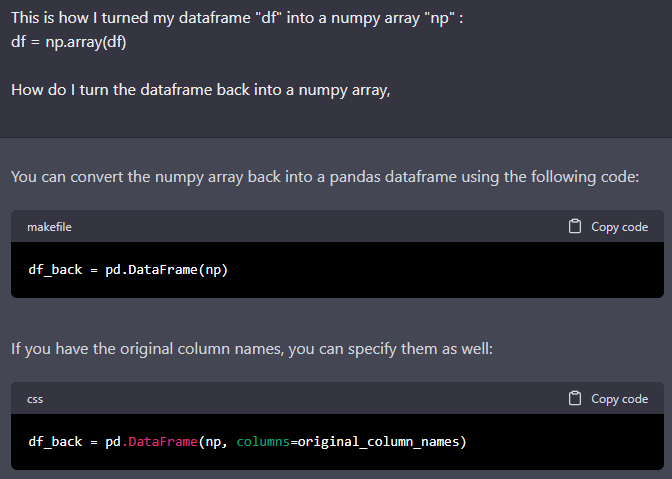
I have finished training a model and had it make predictions but I would like to convert that numpy array back into the original dataframe so I can actually read the output/predictions. I believe this is a data converting issue meaning changing array → df and I found a few functions to do that but they require giving all the columns again. Is there an easier way to do this?
Code example:
df = np.array(df)
I turned my df into a numpyarray like this.
I also forgot to ask about how to convert the categorial values (I used get_dummys function) back to their original
Thank you for the help
No idea to either of those questions, but maybe ChatGPT can help…
YMMV, since it can sound authoritative giving false answers,
so it would be useufl if you could report back results.
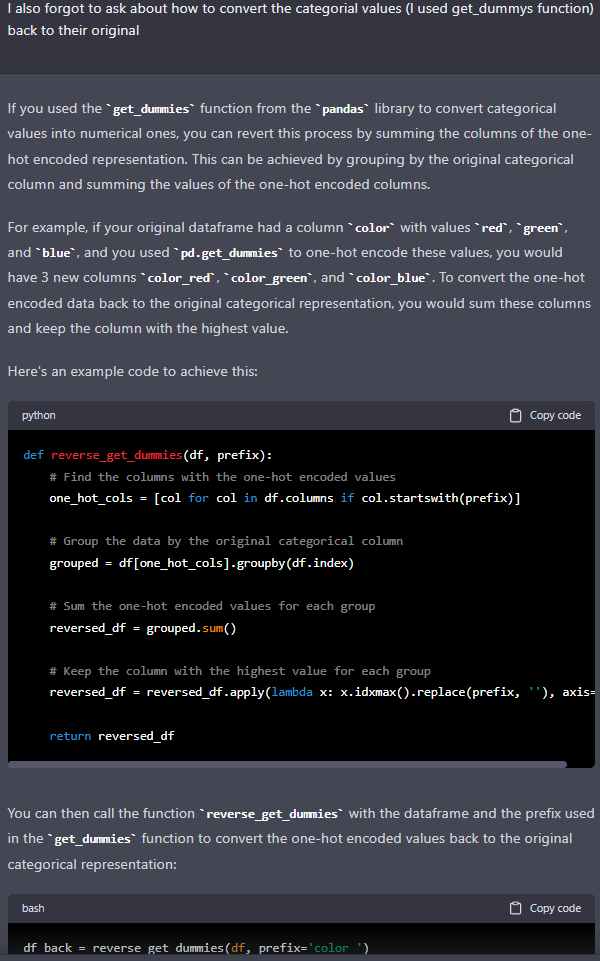
whoops, some code was scrolled off screen and I couldn’t get it all in one snap, co here is the code…
def reverse_get_dummies(df, prefix):
# Find the columns with the one-hot encoded values
one_hot_cols = [col for col in df.columns if col.startswith(prefix)]
# Group the data by the original categorical column
grouped = df[one_hot_cols].groupby(df.index)
# Sum the one-hot encoded values for each group
reversed_df = grouped.sum()
# Keep the column with the highest value for each group
reversed_df = reversed_df.apply(lambda x: x.idxmax().replace(prefix, ''), axis=1)
return reversed_df
Hi everyone,
I’ve been trying to train a model to predict building age from images scraped from Wikipedia and despite what I’ve tried, it doesn’t perform very well.
Might someone take a quick look at my code to see if there’s anything obvious you’d recommend trying to improve the accuracy?
What I’ve tried:
- Different ways of problem structuring e.g. image regression vs. century bucket classification
- Multiple models
- Multiple image sizes
- Multiple image resizing methods
- Multiple learning rates
- Manually removing problematic images
Thanks very much in advance!
link to Colab
Hello,
I don’t know if this forum is still active but I have a question about Lesson two specifically “pred,pred_idx,probs = learn_inf.predict(img)” in the bear classification model. For some reason I get "‘PILImage’ object has no attribute ‘read’.
The full trace stack:
AttributeError Traceback (most recent call last)
<ipython-input-80-9a18687b977c> in <module>
----> 1 pred,pred_idx,probs = learn_inf.predict(img)
25 frames
/usr/local/lib/python3.8/dist-packages/fastai/learner.py in predict(self, item, rm_type_tfms, with_input)
319 def predict(self, item, rm_type_tfms=None, with_input=False):
320 dl = self.dls.test_dl([item], rm_type_tfms=rm_type_tfms, num_workers=0)
--> 321 inp,preds,_,dec_preds = self.get_preds(dl=dl, with_input=True, with_decoded=True)
322 i = getattr(self.dls, 'n_inp', -1)
323 inp = (inp,) if i==1 else tuplify(inp)
/usr/local/lib/python3.8/dist-packages/fastai/learner.py in get_preds(self, ds_idx, dl, with_input, with_decoded, with_loss, act, inner, reorder, cbs, **kwargs)
306 if with_loss: ctx_mgrs.append(self.loss_not_reduced())
307 with ContextManagers(ctx_mgrs):
--> 308 self._do_epoch_validate(dl=dl)
309 if act is None: act = getcallable(self.loss_func, 'activation')
310 res = cb.all_tensors()
/usr/local/lib/python3.8/dist-packages/fastai/learner.py in _do_epoch_validate(self, ds_idx, dl)
242 if dl is None: dl = self.dls[ds_idx]
243 self.dl = dl
--> 244 with torch.no_grad(): self._with_events(self.all_batches, 'validate', CancelValidException)
245
246 def _do_epoch(self):
/usr/local/lib/python3.8/dist-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
197
198 def _with_events(self, f, event_type, ex, final=noop):
--> 199 try: self(f'before_{event_type}'); f()
200 except ex: self(f'after_cancel_{event_type}')
201 self(f'after_{event_type}'); final()
/usr/local/lib/python3.8/dist-packages/fastai/learner.py in all_batches(self)
203 def all_batches(self):
204 self.n_iter = len(self.dl)
--> 205 for o in enumerate(self.dl): self.one_batch(*o)
206
207 def _backward(self): self.loss_grad.backward()
/usr/local/lib/python3.8/dist-packages/fastai/data/load.py in __iter__(self)
125 self.before_iter()
126 self.__idxs=self.get_idxs() # called in context of main process (not workers/subprocesses)
--> 127 for b in _loaders[self.fake_l.num_workers==0](self.fake_l):
128 # pin_memory causes tuples to be converted to lists, so convert them back to tuples
129 if self.pin_memory and type(b) == list: b = tuple(b)
/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py in __next__(self)
626 # TODO(https://github.com/pytorch/pytorch/issues/76750)
627 self._reset() # type: ignore[call-arg]
--> 628 data = self._next_data()
629 self._num_yielded += 1
630 if self._dataset_kind == _DatasetKind.Iterable and \
/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py in _next_data(self)
669 def _next_data(self):
670 index = self._next_index() # may raise StopIteration
--> 671 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
672 if self._pin_memory:
673 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/fetch.py in fetch(self, possibly_batched_index)
41 raise StopIteration
42 else:
---> 43 data = next(self.dataset_iter)
44 return self.collate_fn(data)
45
/usr/local/lib/python3.8/dist-packages/fastai/data/load.py in create_batches(self, samps)
136 if self.dataset is not None: self.it = iter(self.dataset)
137 res = filter(lambda o:o is not None, map(self.do_item, samps))
--> 138 yield from map(self.do_batch, self.chunkify(res))
139
140 def new(self, dataset=None, cls=None, **kwargs):
/usr/local/lib/python3.8/dist-packages/fastcore/basics.py in chunked(it, chunk_sz, drop_last, n_chunks)
228 if not isinstance(it, Iterator): it = iter(it)
229 while True:
--> 230 res = list(itertools.islice(it, chunk_sz))
231 if res and (len(res)==chunk_sz or not drop_last): yield res
232 if len(res)<chunk_sz: return
/usr/local/lib/python3.8/dist-packages/fastai/data/load.py in do_item(self, s)
151 def prebatched(self): return self.bs is None
152 def do_item(self, s):
--> 153 try: return self.after_item(self.create_item(s))
154 except SkipItemException: return None
155 def chunkify(self, b): return b if self.prebatched else chunked(b, self.bs, self.drop_last)
/usr/local/lib/python3.8/dist-packages/fastai/data/load.py in create_item(self, s)
158 def retain(self, res, b): return retain_types(res, b[0] if is_listy(b) else b)
159 def create_item(self, s):
--> 160 if self.indexed: return self.dataset[s or 0]
161 elif s is None: return next(self.it)
162 else: raise IndexError("Cannot index an iterable dataset numerically - must use `None`.")
/usr/local/lib/python3.8/dist-packages/fastai/data/core.py in __getitem__(self, it)
456
457 def __getitem__(self, it):
--> 458 res = tuple([tl[it] for tl in self.tls])
459 return res if is_indexer(it) else list(zip(*res))
460
/usr/local/lib/python3.8/dist-packages/fastai/data/core.py in <listcomp>(.0)
456
457 def __getitem__(self, it):
--> 458 res = tuple([tl[it] for tl in self.tls])
459 return res if is_indexer(it) else list(zip(*res))
460
/usr/local/lib/python3.8/dist-packages/fastai/data/core.py in __getitem__(self, idx)
415 res = super().__getitem__(idx)
416 if self._after_item is None: return res
--> 417 return self._after_item(res) if is_indexer(idx) else res.map(self._after_item)
418
419 # %% ../../nbs/03_data.core.ipynb 53
/usr/local/lib/python3.8/dist-packages/fastai/data/core.py in _after_item(self, o)
375 raise
376 def subset(self, i): return self._new(self._get(self.splits[i]), split_idx=i)
--> 377 def _after_item(self, o): return self.tfms(o)
378 def __repr__(self): return f"{self.__class__.__name__}: {self.items}\ntfms - {self.tfms.fs}"
379 def __iter__(self): return (self[i] for i in range(len(self)))
/usr/local/lib/python3.8/dist-packages/fastcore/transform.py in __call__(self, o)
206 self.fs = self.fs.sorted(key='order')
207
--> 208 def __call__(self, o): return compose_tfms(o, tfms=self.fs, split_idx=self.split_idx)
209 def __repr__(self): return f"Pipeline: {' -> '.join([f.name for f in self.fs if f.name != 'noop'])}"
210 def __getitem__(self,i): return self.fs[i]
/usr/local/lib/python3.8/dist-packages/fastcore/transform.py in compose_tfms(x, tfms, is_enc, reverse, **kwargs)
156 for f in tfms:
157 if not is_enc: f = f.decode
--> 158 x = f(x, **kwargs)
159 return x
160
/usr/local/lib/python3.8/dist-packages/fastcore/transform.py in __call__(self, x, **kwargs)
79 @property
80 def name(self): return getattr(self, '_name', _get_name(self))
---> 81 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
82 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs)
83 def __repr__(self): return f'{self.name}:\nencodes: {self.encodes}decodes: {self.decodes}'
/usr/local/lib/python3.8/dist-packages/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
89 def _call(self, fn, x, split_idx=None, **kwargs):
90 if split_idx!=self.split_idx and self.split_idx is not None: return x
---> 91 return self._do_call(getattr(self, fn), x, **kwargs)
92
93 def _do_call(self, f, x, **kwargs):
/usr/local/lib/python3.8/dist-packages/fastcore/transform.py in _do_call(self, f, x, **kwargs)
95 if f is None: return x
96 ret = f.returns(x) if hasattr(f,'returns') else None
---> 97 return retain_type(f(x, **kwargs), x, ret)
98 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
99 return retain_type(res, x)
/usr/local/lib/python3.8/dist-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs)
118 elif self.inst is not None: f = MethodType(f, self.inst)
119 elif self.owner is not None: f = MethodType(f, self.owner)
--> 120 return f(*args, **kwargs)
121
122 def __get__(self, inst, owner):
/usr/local/lib/python3.8/dist-packages/fastai/vision/core.py in create(cls, fn, **kwargs)
123 if isinstance(fn,bytes): fn = io.BytesIO(fn)
124 if isinstance(fn,Image.Image) and not isinstance(fn,cls): return cls(fn)
--> 125 return cls(load_image(fn, **merge(cls._open_args, kwargs)))
126
127 def show(self, ctx=None, **kwargs):
/usr/local/lib/python3.8/dist-packages/fastai/vision/core.py in load_image(fn, mode)
96 def load_image(fn, mode=None):
97 "Open and load a `PIL.Image` and convert to `mode`"
---> 98 im = Image.open(fn, mode="r")
99 im.load()
100 im = im._new(im.im)
/usr/local/lib/python3.8/dist-packages/PIL/Image.py in open(fp, mode)
2850 exclusive_fp = True
2851
-> 2852 prefix = fp.read(16)
2853
2854 preinit()
AttributeError: 'PILImage' object has no attribute 'read'
I thought I was able to fix the problem from something I saw on Google that said to change “Image. open()” to “to_image()” with no success. I also tried to see if maybe I wasn’t downloading the full library or an updated library by changing “fastai.vision.widgets” to “fastai.vision.all” that didn’t seem to work. I also tried to use a keyword argument “mode=r” in “Image. open()” with no success. I am a beginner so I might be approaching this problem wrong. If anyone could help me I would greatly appreciate it! I’ve been working on this for a couple of hours now but I won’t stop trying.
I don’t think you have to pass the PILImage object to .predict, try passing the path of the image to it, I think it might work.
2 Likes
Correct! You can just pass the image path:
2 Likes
Thank you so much for your help! Here is an appreciation ![]()
1 Like
Thank you for clarifying! Here is an appreciation ![]()
1 Like
I am continuing to get 0.0000% for my first result on the Spaceship Titanic challenge on Kaggle. My final csv comes out as a file with no index, and PassengerId as a str, and Transported as a (0,1) integer. I am at a loss as to why it is a zero. Can someone help? It is surely something dumb I have done.
I’m also having issues running the Hugging Faces Space for my pet classifier. Even trying to run Jeremy’s is throwing a runtime error. Thanks for any help given for the above two questions.
What does
load_learnerrequires all your custom code be in the exact same place as when exporting yourLearner(the main script, or the module you imported it from).
mean? What is “custom code”? I’m trying to use it w/ a model I trained on a GPU and get the error
AttributeError Traceback (most recent call last)
/tmp/ipykernel_356192/2010272548.py in
----> 1 learn = load_learner('../reproduced/pets_classifier_05/pets.pkl')
~/forest/miniconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in load_learner(fname, cpu, pickle_module)
444 distrib_barrier()
445 map_loc = 'cpu' if cpu else default_device()
--> 446 try: res = torch.load(fname, map_location=map_loc, pickle_module=pickle_module)
447 except AttributeError as e:
448 e.args = [f"Custom classes or functions exported with your `Learner` not available in namespace.\Re-declare/import before loading:\n\t{e.args[0]}"]
~/forest/miniconda3/envs/fastai/lib/python3.7/site-packages/torch/serialization.py in load(f, map_location, pickle_module, **pickle_load_args)
710 opened_file.seek(orig_position)
711 return torch.jit.load(opened_file)
--> 712 return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
713 return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
714
~/forest/miniconda3/envs/fastai/lib/python3.7/site-packages/torch/serialization.py in _load(zip_file, map_location, pickle_module, pickle_file, **pickle_load_args)
1047 unpickler = UnpicklerWrapper(data_file, **pickle_load_args)
1048 unpickler.persistent_load = persistent_load
-> 1049 result = unpickler.load()
1050
1051 torch._utils._validate_loaded_sparse_tensors()
...
1043
1044 # Load the data (which may in turn use `persistent_load` to load tensors)
AttributeError: Custom classes or functions exported with your `Learner` not available in namespace.\Re-declare/import before loading:
Can't get attribute 'Resampling' on
So AFAIU this: Saving and Loading Models — PyTorch Tutorials 1.13.1+cu117 documentation, it’s not possible to save a model on some machine and load in on another machine if the directory structure is not exactly the same?! What directory structure is that referring to?
What do you recommend if I want to train and save a model on a GPU machine in the cloud and export/save the model and download it and load it onto my machine?
Hello! I’m playing around with the fastai library trying to get a linear 1-input 1-output model to fit points that were generated from the equation of the straight line (y = x + 10). For some reason when I create a Learner that uses the MSE loss, SGD as an optimizer, and 0.01 for the learning rate, it reaches a point where the slope of the model has the same slope as the function that generated the dataset (one in this case) but the y intercept keeps getting stuck at 0.
When I try to do the same thing using PyTorch, it works! Any idea why this might be happening?
I attached the code I wrote based on what I learned from chapter 4 of the fastai book.
from fastai.vision.all import *
from fastbook import *
# 0) prepare the dataset as a list of tuples
# y = ax + b
x_train = torch.arange(-10, 10, 1).float()
y_train = x_train + 10
x_valid = torch.arange(-9.5, 10.5, 1).float()
y_valid = x_valid + 10
x_train = x_train.view(-1, 1)
y_train = y_train.unsqueeze(dim=1)
ds_train = list(zip(x_train, x_train))
x_valid = x_valid.view(-1, 1)
y_valid = y_valid.unsqueeze(dim=1)
ds_valid = list(zip(x_valid, x_valid))
# 1) create a dataloader using the prepared dataset from step (0)
dl_train = DataLoader(dataset=ds_train, batch_size=20)
dl_valid = DataLoader(dataset=ds_valid, batch_size=20)
dls = DataLoaders(dl_train, dl_valid)
# 2) define the architecture
simple_net = nn.Linear(1, 1)
# 3) define the loss function
def mse(preds, trgts): return ((preds-trgts)**2).mean()
# 4) create a fastai learner
learn = Learner(dls=dls, model=simple_net, loss_func=mse, opt_func=SGD, lr=0.01)
# 5) train for 100 epochs
learn.fit(100)
# plot results
with torch.no_grad():
# plot the x and y axes
plt.plot(x_train, tensor([0]*len(x_train)) , "b")
plt.plot(tensor([0]*len(x_train)), y_train, "b")
# plot the validation set
plt.plot(x_valid, y_valid, "g")
# plot the output of the model input values between -10 and 10
x_test = torch.arange(-10, 10, 0.01).float().view(-1, 1)
plt.plot(x_test, simple_net(x_test), "r")
Thank you!
I did the similar thing. I used Paperspace to train my model and uploaded my trained model on Hugging Face space. I deployed two models, Alien vs Ghost and Fruit or not.
I wrote a blog on my training process and another on my deployment process.
Hopefully it helps.
Hi @yehia,
you have a small type on your dataset definition (both for train and valid):
ds_train = list(zip(x_train, x_train))
Should be:
ds_train = list(zip(x_train, y_train))
By the way, I found the bug by running dls.one_batch() which shows the data that is being used by the network for training, there I saw that x and y values were the same
1 Like
Hi @lucasvw,
Great catch! Thank you so much for the help, and the tip about using dls.one_batch() is very useful.
Have a pleasant day ![]()
1 Like