Yeah the documentation is humongous and overwhelming for novice guys like me (or maybe just me)
The fastpages tutorial was very clear and to the point.
1 Like
Many thanks to you both for this helpful feedback.
3 Likes
Noted. We will have to think about this. It might be that fastest way to create a blog might not even involve GitHub at all!
I also find the documentation to be very confusing and took me quite the while to get used to it, especially with the cell options scattered everywhere. I still find it somewhat hard to navigate.
For example I don’t believe they have a single cheat sheet with all the cell options, page options, and site options (some options apply at multiple levels as well)
We will have a talk about this internally and see what we can do and/or talk to the Quarto folks
Thanks for the feedback
3 Likes
Yeah, I have used setting the seed. But I haven’t tried the seed option, if there is any, for databunch object.
np.random.seed(42)
train_images = list(np.random.choice(training_set, train_samples_per_scanner))
So, I only used seed for a random selection of images, but how they get processed by the databunch is a black box for me. Thus, I wanted to save those data bunch objects, but it looks like saving them gives me that error.
Does anyone know how to save data for object detection problems in FASTAI.
1 Like
@muellerzr this is a really easy way to get started with Quarto blogs
Note: GitHub is not required, and you can publish directly to quarto-pub. You can also use a GUI if you want to use VSCode or RStudio for most of the setup!
I’ve added a link to that document in the blogging guide for nbdev. HTH
2 Likes
After finishing up the Notebook for lesson one, I wanted to try build a model that can predict is a picture is of Elon Musk or not, I want through the same steps of finding relevant data and loading it in a DataBlock and tuning it and while this works by telling me who is the image of, I am curious if that’s the best approach for this specific small problem as it seems like the model contains a lot of extra information about other humans too and also, how do I get it to output if it’s elon or not, instead of the labels it does right now ?
Here is my notebook: Is it an Elon Musk ? | Kaggle
1 Like
you could treat all your other classes (“bill gates”, “trevor noah” etc.) as the same class and then let the model learn to differentiate between elon and all of the others. I guess the easiest way to do this would be to copy all of the other images into one folder and call it “others” and then you can proceed as normal.
3 Likes
You could do what @rasmus1610 suggests but since you are using a labeling function already you could also adjust it to your needs. Right now you use parent_label to determine which label each instance gets, by returning the folder the image is in:
parent_label('path/to/folder/file.png')
'folder'
So you could check if that folder is ‘elon musk’ to generate your label from that e.g.:
def get_y(fn):
folder = parent_label(fn)
return 'elon' if folder == 'elon musk' else 'no-elon'
yields:
get_y('path/to/elon musk/file.png')
'elon'
get_y('path/to/else/file.png')
'no-elon'
Make shure to check the dataloaders (dls.show_batch()) to see if the labels fit your expectation.
2 Likes
Thats much more elegant!
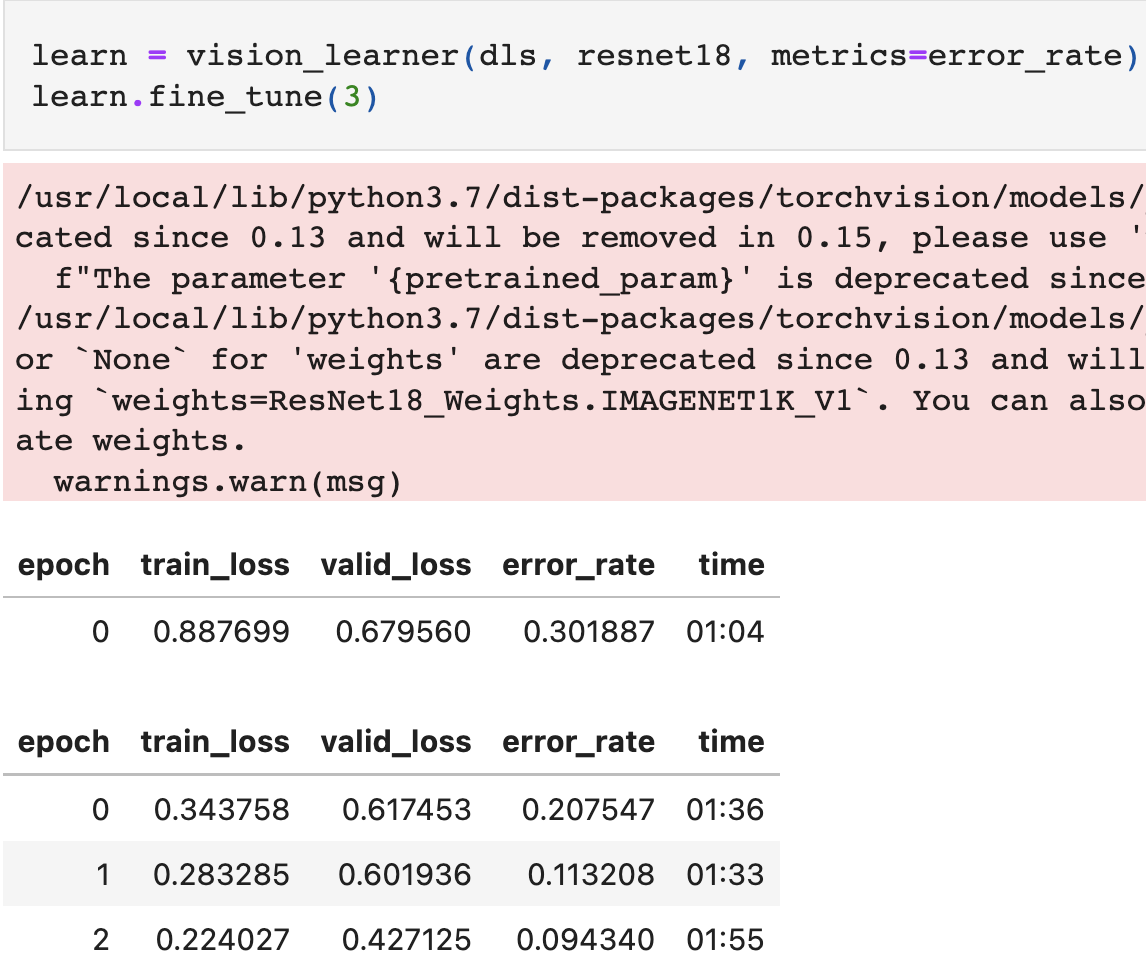
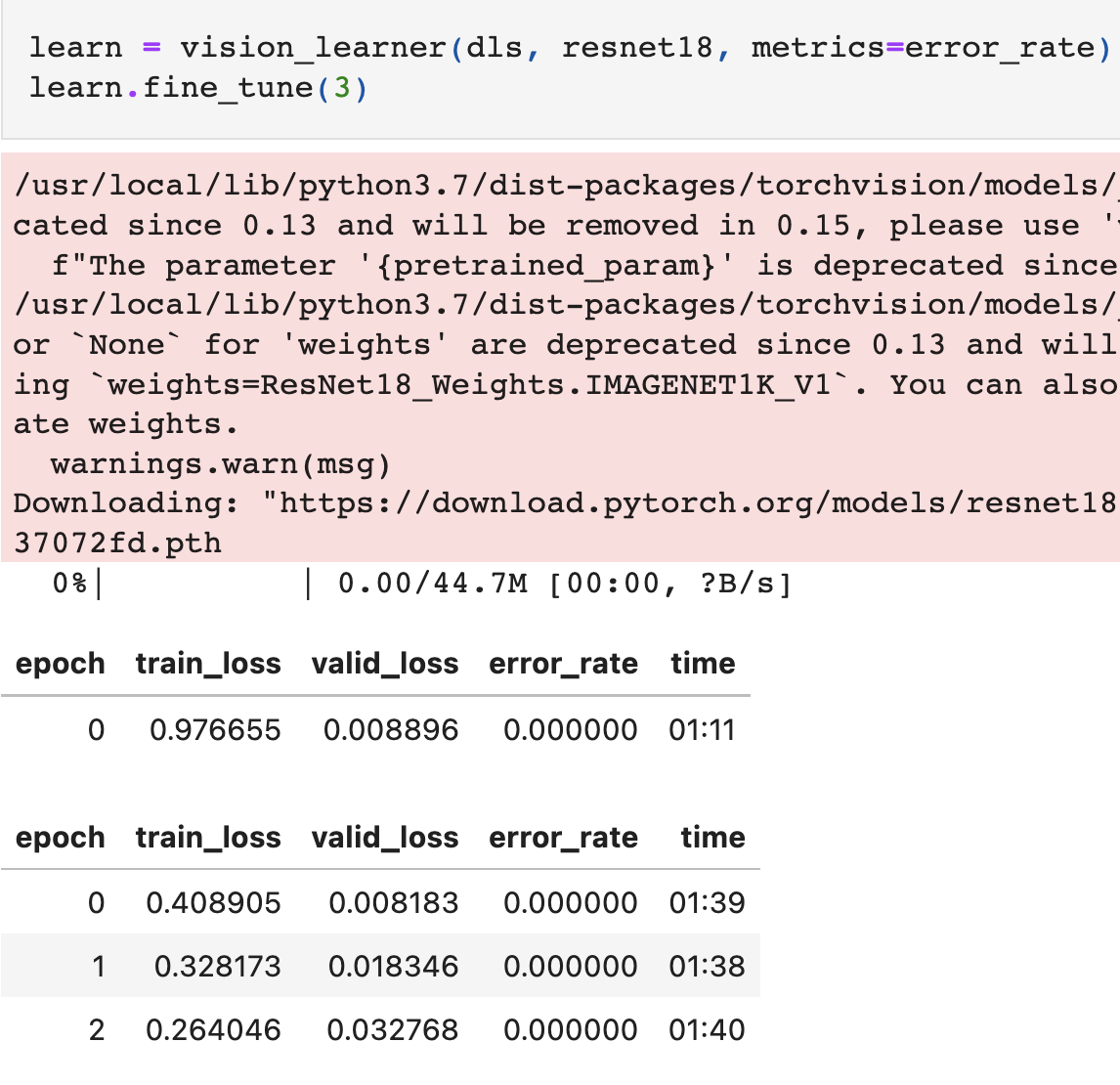
Hi, I created a project - detecting a patient’s fall by binary classification using fastai library - based on ‘Is it a bird’ project after taking a chapter 1 course. But some images were not matching with their labels. So I updated the project after implementing data cleaning, and it showed 100% accuracy.
- Before Data Cleaning:
- After Data Cleaning:
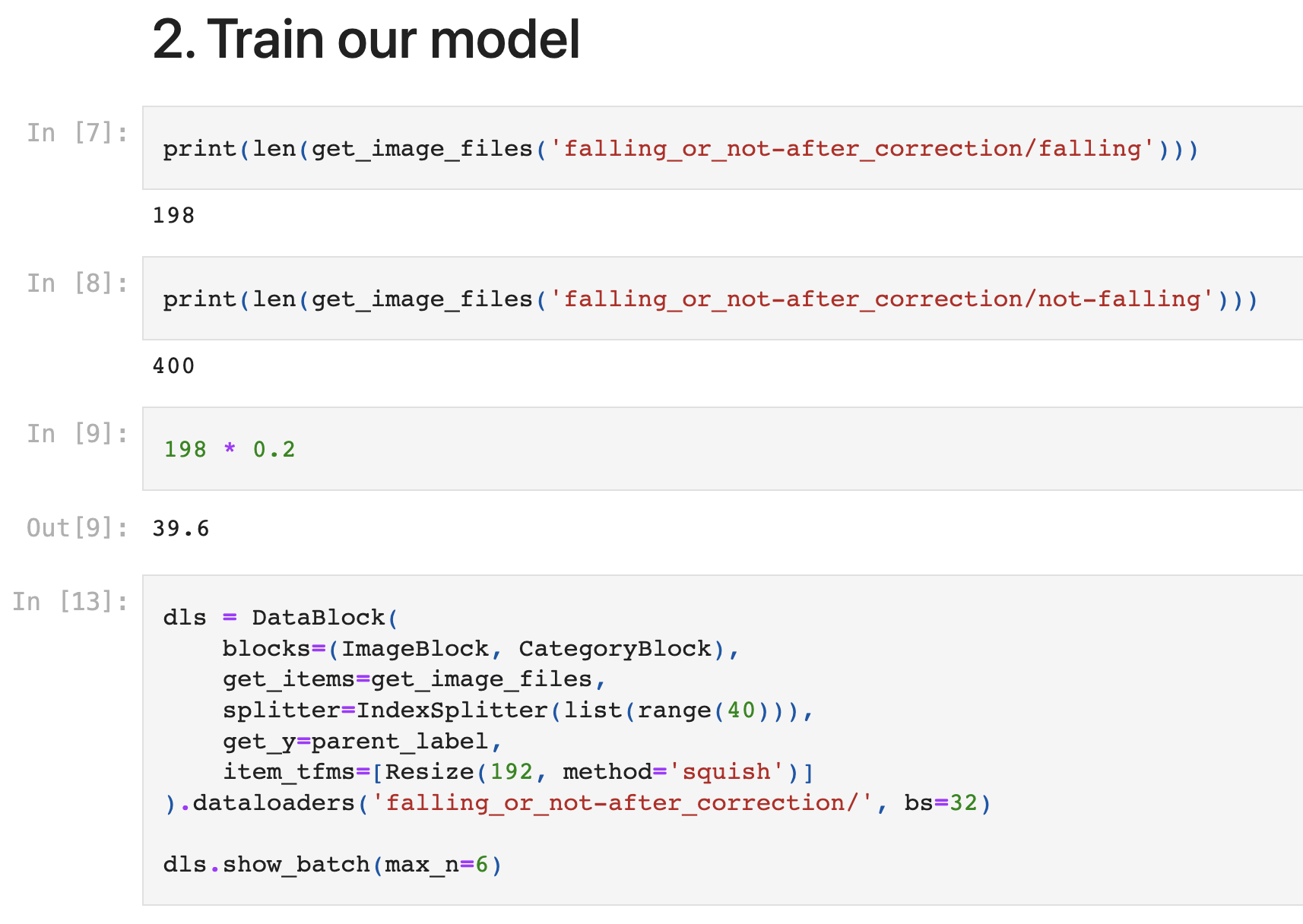
- The source code for training:
Questions:
- I think I trained with 80% of total dataset, did it train with 80% of total data, OR 100% of total data?
- Is “train_loss” related to training set?
- Is “valid_loss” trained in training set, or valid set(20% of total dataset)?
- Is this classifier trained with only 80% of data without working with 20%?
- Is it okay to get 100% accuracy after data cleaning?
- Does 100% accuracy (after data cleaning) mean that the project was trained with all dataset including valid set?
I’m a beginner, and please help me! Thank you in advance.
Answers to your question (If I understand it correctly):
- It has been trained on 80 % of the total dataset.
-
train_lossis the loss computed on your training dataset (80%) -
valid_lossis the loss computed on your validation dataset (20%) - The model is only trained on 80 % of the dataset (see #1), the remaining 20% are for evaluating the model (that’s your validation dataset).
- What do you mean with “is it okay”? It’s great that you get 100% accuracy, although I see a problem with your creation of the validation dataset (see below)
- Again the model was only trained on your training dataset, containing 80 % of the images.
One thing I’m concerned about is that you didn’t split your dataset randomly but you used the first 40 images as a validation set and evaluated the performance on that. I’m not entirely sure how get_image_files transverses the folder structure but I’m pretty sure that the first 40 images, that are returned by get_image_files are only from your 'falling' folder. So your validation dataset consists only of images of one class. This makes it not usable for evaluating a model that should discriminate between images of two classes. I would just use splitter=RandomSplitter() and retrain the model again.
5 Likes
Thank you for the explanation. They were really helpful!
I am running a new Mac Pro M1 and followed the setup from the book. nbdev didn’t seem to get me Jupyter running. So I ran mamba install -c jupyter and everything seems to run sufficiently.
Is this going to cause issues as I progress to the next lessons?
If it works for your current purpose you should be fine. But do note that PyTorch M1 support is still not fully there and things might or might not work on an M1 depending on the code. I’ve only gone up to section 4 on an M1 Mac and that worked fine (with some tweaking). I don’t know about the the other four sections yet but generally, with some tweaking you can get it working has been my general experience.
@rasmus1610 I’m not entirely sure how
get_image_filestransverses the folder structure but I’m pretty sure that the first 40 images, that are returned byget_image_filesare only from your'falling'folder. So your validation dataset consists only of images of one class.
I have a question…Although I’m not sure about IndexSplitter, I thought data is loaded from ‘falling_or_not-after_correction/’ folder containing ‘falling’ folder and ‘not-falling’ folder, so valid set would be set with image data from falling[:40] and not-falling[:40]… I mean, I thought valid set would have “falling[:40] + not_falling[:40]”.
But according to your words, the valid set has set to falling[:40]. Is it because (falling + not_falling)[:40]??
I’m not sure which one is right… What do you think? Thank you for detailed explanation, anyway.
You are exactly right. The validation set is (falling + not_falling)[:40].
What get_image_files returns is basically a concatenated list of all of the images in falling and not_falling. Since you don’t shuffle this list, the first 40 items will be from one folder only.
If the validation dataset would consist of falling[:40] + not_falling[:40] you would also have 80 images in your validations dataset and not 40.
2 Likes
I’ve been wasting a lot of time it feels trying to get Mac Pro M1 working with fastai course - protobufs, python versions, pytorch-nightly etc: have given up and now use a remove server in VS Code provided buy Paperspace - Remote Jupyter Kernel | Paperspace. Much happier so far.
1 Like
I see. Thank you for answering my question!
Generally it is “safe”, except from yourself and those whom you grant write access to. ![]()
These protections are more to enforce best practices are used or not accidently mess up your repository (i.e. --force)…
I would set the repository to private and double check that there are no credentials or “secrets” were pushed to the repository before exposing it to the public.
Which one do I click if I want other send pull request but I need to approve them to approve the change?
Likely nothing. If they don’t have write access to the repo, then only way to incorporate changes is through a pull request which must be processed by those who have write access.
Edward
Yeah same here, I’m using a remote server on Callisto right now. It makes things like this a little easier since I don’t have to worry about M1 compatibility issues.